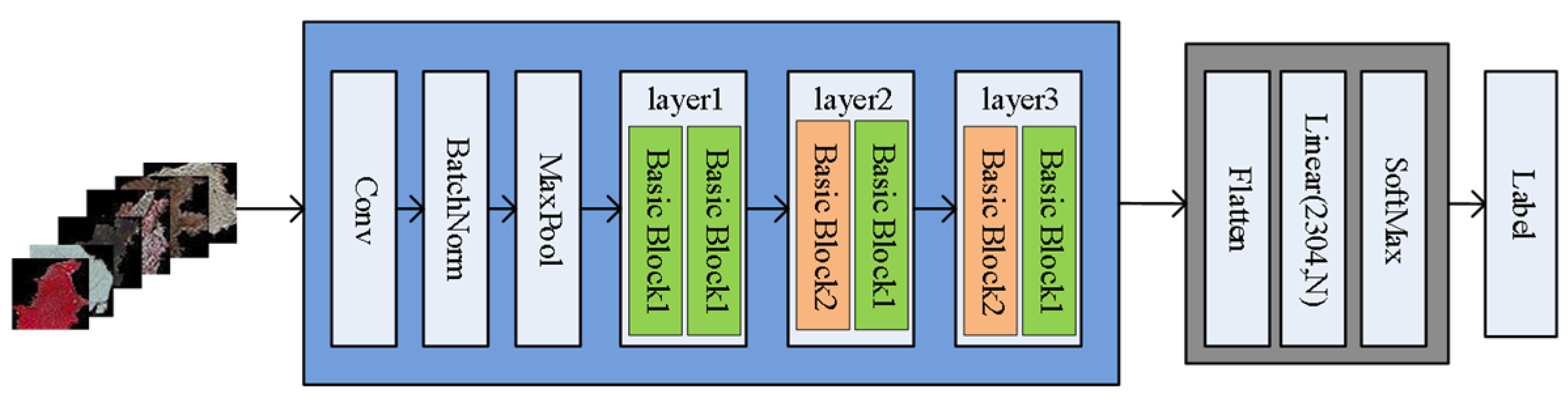
This section introduces the GL-SLIC algorithm, a novel approach designed to enhance the segmentation and classification of sandstone thin section images. This is achieved through the methodical integration of textural and color features into superpixel segmentation. The GL-SLIC algorithm is structured into three primary stages: GLBP Feature Construction, GL-SLIC Superpixel Segmentation, and Region Merging.
GLBP Feature Construction: The foundation of this algorithm lies in GLBP (Gabor-Local Binary Pattern) features, which synergistically combine texture and color information.
GL-SLIC Superpixel Segmentation: Building upon the GLBP features, this step employs the SLIC (simple linear iterative clustering) algorithm for superpixel segmentation. This method effectively partitions the image into numerous coherent superpixels, each closely corresponding to natural divisions within the image based on the enhanced GLBP features.
Region Merging: Following segmentation, this process merges adjacent superpixels exhibiting similar characteristics. This merging step addresses the issue of over-segmentation, where individual superpixels may be too small or fragmented to be useful in isolation.
2.3.1. GLBP Feature Extraction
This section introduces a novel texture feature extraction algorithm that integrates the local binary pattern (LBP) operator with Gabor filters, leveraging both spatial and frequency domain characteristics, as shown in
Figure 3. This hybrid approach robustly extracts features from sandstone thin section images, effectively minimizing the impact of external factors such as noise, illumination, rotation, and shadows.
Operational Steps:
1. Input Data: The initial step involves inputting the sandstone thin section image data designated for segmentation.
2. Feature Extraction Using Gabor Filters: The algorithm applies Gabor filters at various scales and orientations to the original sandstone thin section images. Specifically, the filters are set at six different scales and six orientations, creating a total of 36 distinct Gabor filters. These filters systematically extract features across the images, resulting in 36 Gabor feature vectors.
Figure 4 illustrates the features extracted by the Gabor filters at each scale and orientation. The scales are shown vertically from top to bottom (1 through 6), and the orientations are displayed horizontally.
3. Mean Feature Calculation Using Gabor Filters.
Each Gabor feature extracted from different orientations and scales is averaged to calculate the mean feature for each respective setting. The Gabor filters are applied at six different scales and orientations, resulting in 36 distinct Gabor filters. The mean of the features extracted by each Gabor filter at these scales and orientations is computed as follows:
Figure 5 visually demonstrates the effectiveness of Gabor filter transformations in extracting distinctive textural features from sandstone thin sections at various scales and orientations. Each panel within the figure highlights the nuanced differences between quartz grains and other geological components, which are not easily discernible in the original images. In panels such as
Figure 5a,b, red boxes identify two quartz grains that appear similar in the raw image but are distinctly separated in the processed images due to the enhanced textural contrasts provided by the Gabor features. Similarly,
Figure 5d,f use red and blue boxes to differentiate between quartz and pores with enhanced clarity. This shows that even subtle textural differences become pronounced when viewed through Gabor-filtered images. The distinct representation of quartz in
Figure 5f, where its color appears markedly darker than surrounding materials, exemplifies how effectively these features can isolate specific components.
4. Encoding with LBP Operator
The mean feature images obtained from the Gabor filters are then encoded using the LBP operator. This operator emphasizes local textural patterns by comparing each pixel with its neighborhood.
Figure 6 displays the LBP-encoded images corresponding to the mean features.
5. GLBP Feature Construction Using PCA
The six image matrices generated from the LBP encoding are then subjected to principal component analysis (PCA). This step reduces dimensionality and extracts the most significant features, forming a feature vector that succinctly represents the textural characteristics of the sandstone images.
2.3.2. Enhanced SLIC Superpixel Segmentation Algorithm: GL-SLIC
In this section, we introduce the GL-SLIC algorithm, an advanced version of the Simple Linear Iterative Clustering (SLIC) superpixel segmentation method. This algorithm incorporates texture features derived from GLBP (Gabor–local binary pattern) attributes. This enhanced algorithm aims to produce superpixels that more accurately conform to the edges of mineral particles within sandstone images, capturing both local and global features effectively.
Process and Methodology:
1. Feature Extraction: Initially, the GLBP texture features of the image are extracted using Gabor filters and LBP operators. The image is then transformed from RGB color space to CIE-Lab color space to prepare it for segmentation. This transformation enhances the distinction based on lightness and color components, which align more closely with human visual perception.
2. Initialization of Cluster Centers: The image is divided into K superpixel grids, with each grid’s step size proportional to the total number of pixels in the image. The initial cluster centers are chosen by placing them at certain intervals, ensuring that each superpixel represents a region of approximately equal size within the image. Each initial cluster center corresponding to a superpixel center is denoted as . is mapped to a six-dimensional vector , where and are spatial positions, ,, and are the color features in the CIE-Lab color space, and represents the GLBP feature value for k = 1,2,…, K.
3. Optimization of Initial Cluster Centers: To enhance the accuracy of clustering and segmentation, an optimization strategy for initial cluster centers is employed. This process involves adjusting the cluster centers to areas with the lowest gradient within their neighborhoods. This helps avoid placing them on edges or noisy regions where abrupt changes in image properties occur. As a result, the algorithm ensures that superpixels are more likely to encapsulate homogeneous regions, thereby improving the overall segmentation quality.
The calculation of the gradient at a pixel position (
x,
y) is crucial for this optimization process and is defined by the following formula:
where
represents the first three components of the feature vector
at location
, specifically
,
, and
. This gradient computation integrates the local differences in luminance and color channels, effectively capturing edge intensity which guides the relocation of cluster centers to less variant regions.
4. Initialization of Distances and Labels: Each pixel is initially assigned a label = −1 and a distance . This setup prepares for the subsequent clustering process by ensuring all pixels can be evaluated for their proximity to potential new cluster centers.
5. Distance Calculation Between Pixels and Cluster Centers: For each pixel within the neighborhood of a cluster center, the distance to the cluster center is computed. This calculation incorporates a combination of Euclidean distances based on spatial, color, and texture features. The overall distance metric used for superpixel segmentation is composed of three parts: color feature distance, spatial feature distance, and texture feature distance.
Color Feature Distance
:
Spatial Feature Distance
:
Texture Feature Distance
:
Overall Distance Metric
:
where
and
are normalization factors for spatial and color distances, respectively, and
is a weighting function for the texture gradient.
6. Pixel Classification and Iteration: Pixels are classified into the nearest cluster based on the calculated distances. Cluster centers are then recalculated as the mean of the features within each cluster, and this reassignment continues iteratively until the cluster centers stabilize, indicating that a robust segmentation has been achieved.
7. Recalculation of Cluster Centers: The process of recalculating the cluster centers involves updating their positions based on the mean of the feature vectors of all pixels currently assigned to each cluster. This is achieved by performing the following steps:
Compute Mean Feature Vectors: For each cluster, calculate the mean of the feature vectors of all assigned pixels. This mean vector becomes the new position of the cluster center.
Reassign Pixels: With the newly calculated cluster centers, reassign each pixel to the nearest cluster based on the comprehensive distance metric previously defined. This involves recalculating the distances for all pixels relative to each new cluster center and updating their cluster assignments accordingly.
Iteration: This process of recalculating cluster centers and reassigning pixels is iterated. After each iteration, check for significant changes in the positions of the cluster centers.
Convergence Criterion: The iteration stops when the changes in the cluster centers’ positions between successive iterations fall below a predefined threshold, indicating convergence. This threshold ensures that the algorithm terminates when cluster centers stabilize, reflect.
8. Finalization of Clusters: The process concludes with a final adjustment of clusters to ensure that each superpixel optimally represents a distinct region of the image, with minimal intra-cluster variance and maximized inter-cluster distinction.
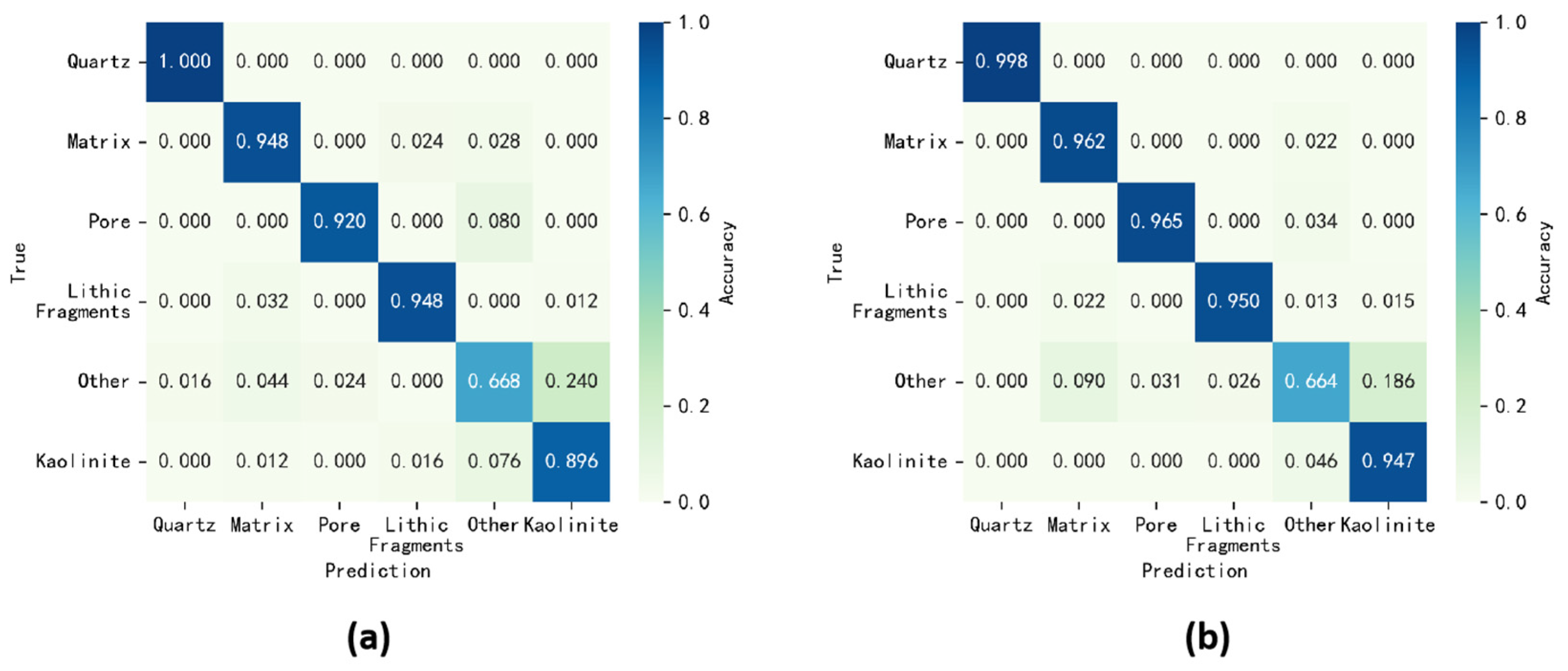
The GL-SLIC algorithm leverages the textural and color features encoded by the GLBP method, resulting in superpixels that are more aligned with natural divisions in the image, such as mineral boundaries. This improved segmentation forms a critical foundation for accurate subsequent analyses, including region merging and classification tasks.
2.3.3. Superpixel Merging Strategy
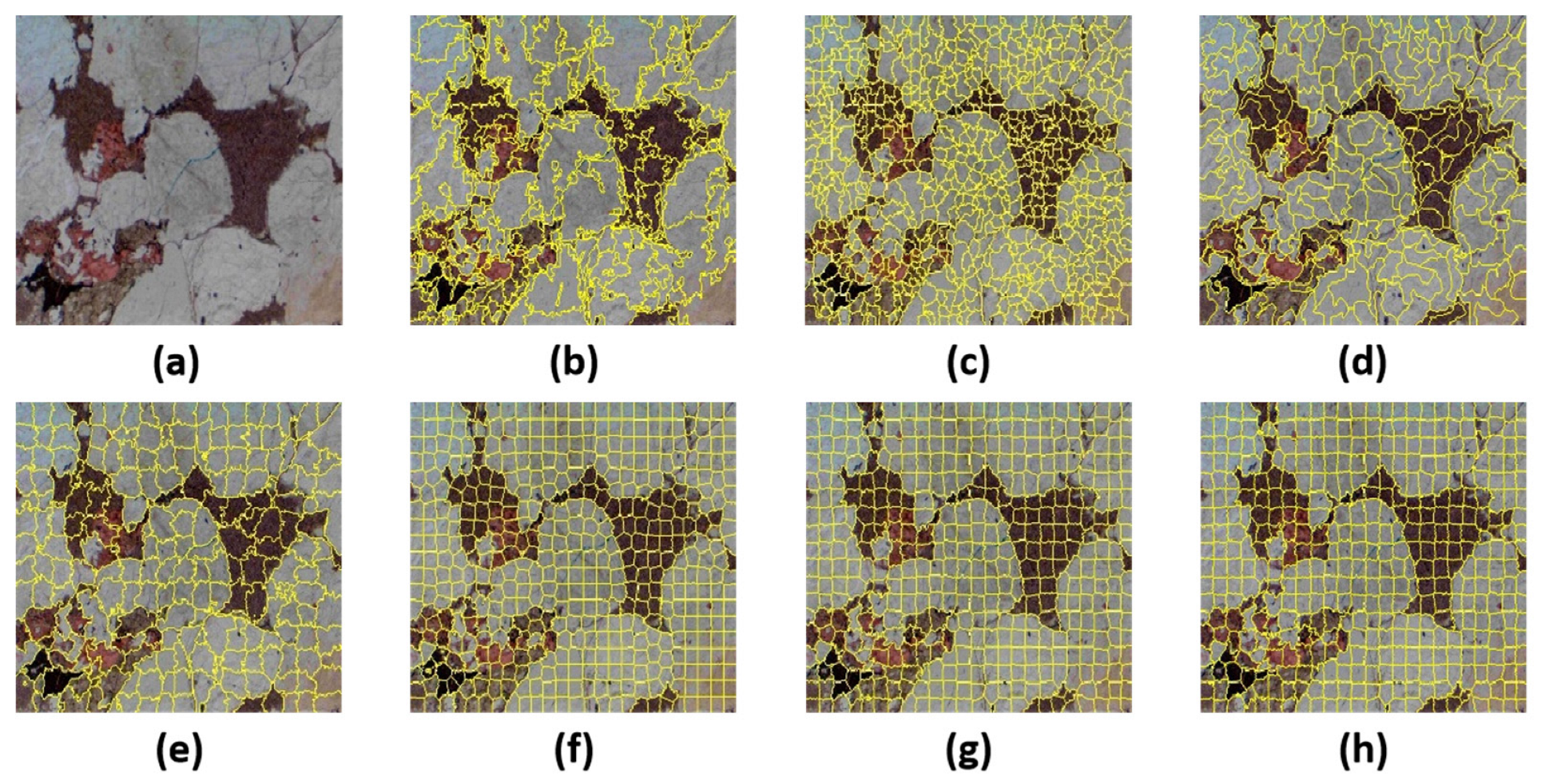
To enhance the quality of data for training classification models, a coarse merging of generated superpixels is necessary. Initially, an adjacency matrix is constructed based on the average color features of each superpixel block. The dissimilarity between two adjacent regions is measured by the Euclidean distance between the average color values of the superpixels. Regions with smaller dissimilarities are more similar and thus are candidates for merging. Given a threshold, superpixel merging is conducted using a breadth-first traversal algorithm tailored for graph-based segmentation. The range for the threshold is determined by the variability in the color features across different rock images, which can be significant.
To set the threshold , consider the following inequalities which balance between merging too many dissimilar superpixels and maintaining meaningful segmentation.
Normalized Difference Threshold:
where
is the weight of the edge between superpixels
and
, representing the dissimilarity based on color features.
and
are the minimum and maximum weights in the adjacency graph, respectively.
Weighted Threshold Formulation:
Alternative Formulation:
where
and
are parameters that you can adjust to fine-tune the merging criteria, ideally within a range of [0, 1].
Given the diversity in rock images, a more relaxed merging strategy might lead to excessive merges; hence, the threshold settings are critical to ensure that only truly similar superpixels are combined. Moreover, while the GL-SLIC algorithm primarily utilizes the CIE-Lab color space for distance metrics, in this context, the YCBCR color space is also employed to cater to different chromatic and luminance variations more effectively.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}