
Self-Supervised Learning for Time-Series Anomaly Detection in Industrial Internet of Things




Abstract
:1. Introduction
- We first introduce an IIoT architecture for real-time data collection based on edge computing. In this way, the historical data can be collected for the offline phase and continuously detect anomalies for every new input data in a real testbed.
- We further propose an efficient SSL method based on the normal IIoT sensory data to detect any anomalous pattern. The self-labeled data is generated corresponding to the augmentation data based on rotation and jittering technique. Then, the convolution neural network is presented to classify the timeseries for anomaly detection on the IIoT system.
- We conduct extensive experiments in industrial sensor datasets acquired from the real environment to verify the effectiveness of the proposed framework and performance enhancement of SSL in anomaly detection. The comprehensive experimental evaluations indicate that the proposed framework performs significantly better than well-known existing anomaly detection approaches in terms of processing time and detection accuracy.
2. Related Works
2.1. Traditional Anomaly Detection Method
- Supervised Deep Anomaly Detection: Typically, a supervised DAD uses the labels of normal and abnormal data to train a deep supervised binary or multiclass classifier. In a multi-cloud environment, Salman et al. [2] employed Linear Regression and Random Forest for anomaly detection and their categorization. Furthermore, Watson Jia et al. [3] have proposed an anomaly detection method using supervised learning based on Long Short-Term Memory (LSTM) along with the statistical properties of the time-series data. However, the supervised DAD method lacks labeled training data, and the performance of the model will be poor due to the imbalanced samples used to detect an anomaly.
- Semi-supervised Deep Anomaly Detection: Semi-supervised learning takes into account the problem of classification when only a small portion of data has a corresponding label. For example, Wulsin et al. [4] employed Deep Belief Nets in a semi-supervised paradigm to model electroencephalogram (EEG) waveforms for classification and anomaly detection. Shen Zhang et al. [12] proposed two semi-supervised models based on the generative feature of variational autoencoders (VAE) for bearing anomaly detection. The semi-supervised DAD approach is popular as it can use only a single class of labels to detect anomalies. However, semi-supervised learning still requires that the relationship between labeled and unlabeled data distribution holds during data collection. This makes the model difficult to extend in the future when this distributional similarity is uncertain in the IIoT system.
- Unsupervised Deep Anomaly Detection: In the unsupervised DAD approach, the system will be trained using the normal data, so when data falls outside some boundary condition, it is flagged as anomalous. To employ unsupervised DAD, the models such as autoencoder (AE) [6,13,14], LSTM [15,16,17], and Generative Adversarial Network (GAN) [18,19,20] are trained to generate normal data on the training dataset. Subsequently, the models either predict or reconstruct time-series data, identifying outliers based on a comparison of the real and predicted or reconstructed values. Perera et al. [20] employed One-class GAN (OCGAN) to improve robustness using a denoising autoencoder and learn latent space that exclusively represents a given class utilizing two discriminators. Meanwhile, Wu et al. [15] proposed LSTM–Gauss–NBayes in IIoT for anomaly detection. Specifically, the stacked LSTM model was employed to forecast the tendency of the time series, and the Naive Bayes model was used to detect anomalies based on the prediction result. However, because these methods can fit data, there is a risk that they could also fit anomalous data. Moreover, LSTM based on anomaly detection methodology is time-consuming and cannot be used for anomaly detection in real time.
2.2. Self-Supervised Learning for Anomaly Detection
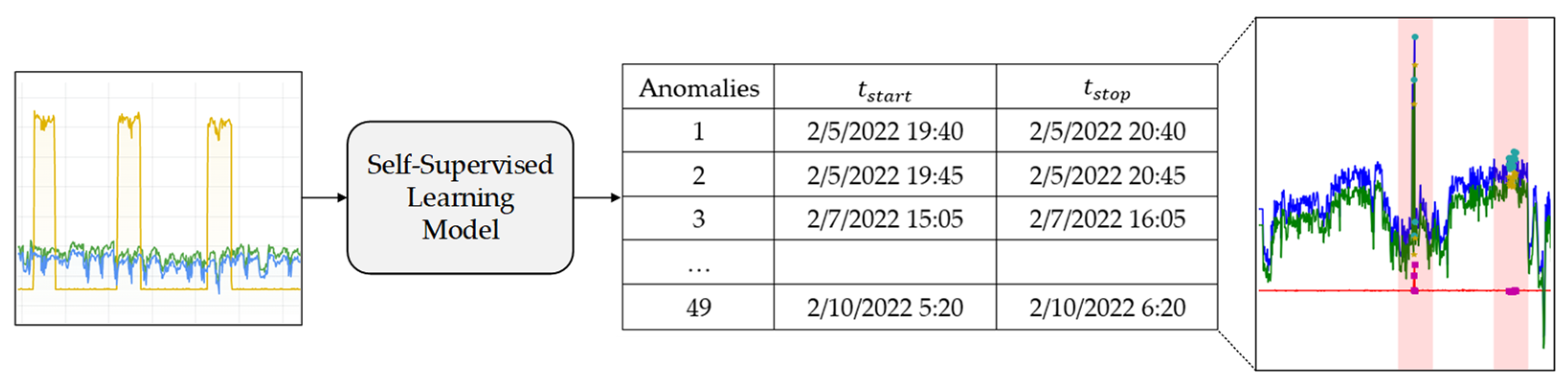
3. Data Preparation
3.1. Data Collection and Preprocessing
- Convert timestamps into the same interval: In the IIoT time-series data collection process, the inconsistency of the timestamps may occur due to the effect of network delay. Furthermore, while conducting anomaly detection, the failure that occurs at a specific time is caused by a variety of factors simultaneously. Thus, various types of sensor feature data must be converted into the same time interval;
- Clean data: We realized that the data collection may obtain some missing value due to the different types and impacts [8]. Moreover, the alignment of data timestamps also causes missing values. There are many methods to impute missing values, e.g., forward filling and backward filling. Accordingly, the k-nearest neighbor imputation [29] is used to fill the missing values caused by the robustness and sensitivity of this method;
- Integrate multiple-sensor feature into single multivariate time series: Multiple PM sensors are typically used for the condition measurement of an industrial site, particularly in a cleanroom environmental monitoring system. Event anomalies are commonly caused by multiple factors. Therefore, various characteristics must be integrated for the model to uncover potential information between distinct variables and reduce the computation time.
- Scale multivariate time-series data: To achieve a sustainable learning process, the input data should be scaled before fitting with the model. The StandardScaler is employed in this paper to scale the values of the features with mean 0 and standard deviation 1 to prevent the different sizes of data from affecting the training. The formula for this function is as follows:
3.2. Sliding Sample
4. Methodology
4.1. Self-Supervised Learning Paradigm
4.2. Anomaly Detection
4.3. Deployment on Edge Devices
5. Evaluation
5.1. Framework Performance
5.1.1. Experiment Dataset
5.1.2. Evaluation Metrics
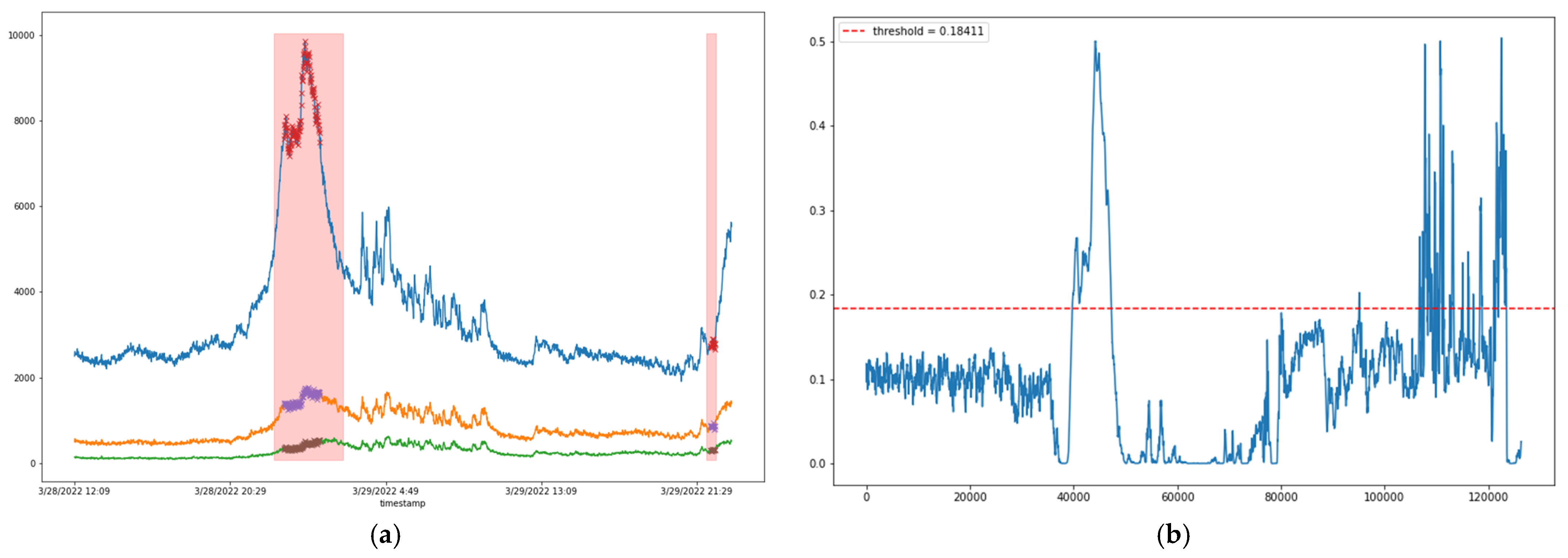
5.1.3. Experimental Results
5.2. Model Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hasan, M.; Islam, M.; Zarif, I.I.; Hashem, M. Attack and anomaly detection in IoT sensors in IoT sites using machine learning approaches. Internet Things 2019, 7, 100059. [Google Scholar] [CrossRef]
- Salman, T.; Bhamare, D.; Erbad, A.; Jain, R.; Samaka, M. Machine Learning for Anomaly Detection and Categorization in Multi-Cloud Environments. In Proceedings of the 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, 26–28 June 2017; pp. 97–103. [Google Scholar] [CrossRef] [Green Version]
- Jia, W.; Shukla, R.M.; Sengupta, S. Anomaly Detection using Supervised Learning and Multiple Statistical Methods. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1291–1297. [Google Scholar]
- Wulsin, D.F.; Gupta, J.R.; Mani, R.; Blanco, J.A.; Litt, B. Modeling electroencephalography waveforms with semi-supervised deep belief nets: Fast classification and anomaly measurement. J. Neural Eng. 2011, 8, 036015. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hossain, A.; Choudhury, Z.A.; Suyut, S. Statistical process control of an industrial process in real time. IEEE Trans. Ind. Appl. 1996, 32, 243–249. [Google Scholar] [CrossRef]
- Pidhorskyi, S.; Almohsen, R.; Doretto, G. Generative probabilistic novelty detection with adversarial autoencoders. Proc. Adv. Neural Inf. Process. Syst. 2018, 31, 6822–6833. [Google Scholar]
- Geiger, A.; Liu, D.; Alnegheimish, S.; Cuesta-Infante, A.; Veeramachaneni, K. TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 33–43. [Google Scholar]
- Gunupudi, R.K.; Nimmala, M.; Gugulothu, N.; Gali, S.R. CLAPP: A self-constructing feature clustering approach for anomaly detection. Future Gener. Comput. Syst. 2017, 74, 417–429. [Google Scholar] [CrossRef]
- Wu, M.; Song, Z.; Moon, Y.B. Detecting cyber-physical attacks in CyberManufacturing systems with machine learning methods. J. Intell. Manuf. 2019, 30, 1111–1123. [Google Scholar] [CrossRef]
- Jahan, I.; Alam, M.M.; Ahmed, F.; Jang, Y.M. Anomaly Detection in Semiconductor Cleanroom Using Isolation Forest. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence, Jeju Island, Korea, 20–22 October 2021; pp. 795–797. [Google Scholar] [CrossRef]
- Bui, V.; Pham, T.L.; Nguyen, H.; Jang, Y.M. Data Augmentation Using Generative Adversarial Network for Automatic Machine Fault Detection Based on Vibration Signals. Appl. Sci. 2021, 11, 2166. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Semi-Supervised Bearing Fault Diagnosis and Classification Using Variational Autoencoder-Based Deep Generative Models. IEEE Sens. J. 2021, 21, 6476–6486. [Google Scholar] [CrossRef]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding Gaussian mixture model for unsupervised anomaly detection. In Proceedings of the ICLR—International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Abati, D.; Porrello, A.; Calderara, S.; Cucchiara, R. Latent Space Autoregression for Novelty Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 481–490. [Google Scholar]
- Wu, D.; Jiang, Z.; Xie, X.; Wei, X.; Yu, W.; Li, R. LSTM Learning with Bayesian and Gaussian Processing for Anomaly Detection in Industrial IoT. IEEE Trans. Ind. Inform. 2020, 16, 5244–5253. [Google Scholar] [CrossRef] [Green Version]
- Ezeme, M.O.; Mahmoud, Q.H.; Azim, A. Hierarchical Attention-Based Anomaly Detection Model for Embedded Operating Systems. In Proceedings of the 2018 IEEE 24th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hakodate, Japan, 28–31 August 2018; pp. 225–231. [Google Scholar] [CrossRef]
- Ergen, T.; Kozat, S.S. Unsupervised Anomaly Detection With LSTM Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3127–3141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Information Processing in Medical Imaging—IPMI 2017; Springer: Cham, Switzerland, 2017; Volume 10265, pp. 146–157. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. GANomaly: Semi-supervised anomaly detection via adversarial training. In Computer Vision—ACCV 2018; Springer: Cham, Switzerland, 2018; Volume 11363, pp. 622–637. [Google Scholar]
- Perera, P.; Nallapati, R.; Xiang, B. Ocgan: One-class novelty detection using gans with constrained latent representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2898–2906. [Google Scholar]
- Gidaris, S.; Singh, P.; Komodakis, N. Unsupervised representation learning by predicting image rotations. In Proceedings of the 6th International Conference on Learning Representations ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2018; pp. 1096–1103. [Google Scholar]
- Xu, J.; Xiao, L.; López, A.M. Self-Supervised Domain Adaptation for Computer Vision Tasks. IEEE Access 2019, 7, 156694–156706. [Google Scholar] [CrossRef]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. In Proceedings of the International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Franceschi, J.Y.; Dieuleveut, A.; Jaggi, M. Unsupervised scalable representation learning for multivariate time series. In Adv. Neural Inf. Process. Syst. 2019, 32, 4650–4661. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. Wav2vec: Unsupervised pre-training for speech recognition. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Graz, Austria, 15–19 September 2019; pp. 3465–3469. [Google Scholar]
- Ravanelli, M.; Zhong, J.; Pascual, S.; Swietojanski, P.; Monteiro, J.; Trmal, J.; Bengio, Y. Multi-task self-supervised learning for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6989–6993. [Google Scholar]
- Five Types of PLC Programming Languages by Editorial Staff. Available online: https://instrumentationtools.com/plc-programming-languages/ (accessed on 22 January 2022).
- Beretta, L.; Santaniello, A. Nearest neighbor imputation algorithms: A critical evaluation. BMC Med. Inform. Decis. Mak. 2016, 16, 74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sax, M.J. Apache Kafka. In Encyclopedia of Big Data Technologie; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| particle05 | particle10 | particle25 | |
|---|---|---|---|
| Count | 326,582.000000 | 326,582.000000 | 326,582.000000 |
| Mean | 3104.740019 | 718.597795 | 209.517894 |
| Std | 1277.831192 | 305.942819 | 113.964858 |
| Min | 908.000000 | 195.000000 | 43.000000 |
| 25% | 2422.000000 | 501.000000 | 119.000000 |
| 50% | 2786.000000 | 651.000000 | 187.000000 |
| 75% | 3720.000000 | 896.000000 | 258.000000 |
| Max | 9869.000000 | 1811.000000 | 642.000000 |
| Missing | 0.000223 | 0.000223 | 0.000223 |
| ConvNet | Layer (Type) | Output Shape | Parameter |
|---|---|---|---|
| 1D_Convolutional_Layer_1 (Conv1D) | (None, 12, 64) | 1408 | |
| Batch_Normalization_1 | (None, 12, 64) | 256 | |
| ReLU | (None, 12, 64) | 0 | |
| 1D_Convolutional_Layer_2 (Conv1D) | (None, 12, 64) | 28736 | |
| Batch Normalization_2 | (None, 12, 64) | 256 | |
| ReLU | (None, 12, 64) | 0 | |
| Global_average_pooling1d | (None, 64) | 0 | |
| Dense | (None, 2) | 130 | |
| 1D_Convolutional_Layer_1 (Conv1D) | (None, 12, 64) | 1408 |
| Dataset | Metric | LSTM | Autoencoder | LSTM Autoencoder | ARIMA | Proposed SSL Method |
|---|---|---|---|---|---|---|
| NAB Artificial With Anomaly | Precision | 0.73107 | 0.72430 | 0.77263 | 0.91406 | 0.91787 |
| Recall | 0.69479 | 0.70883 | 0.86849 | 0.87097 | 0.94293 | |
| F1 score | 0.69779 | 0.71648 | 0.81776 | 0.89199 | 0.93023 | |
| NAB Machine Temperature | Precision | 0.55820 | 0.51323 | 0.57451 | 0.83113 | 0.81129 |
| Recall | 0.25035 | 0.30607 | 0.60268 | 0.82712 | 0.85502 | |
| F1 score | 0.34566 | 0.38346 | 0.58826 | 0.82912 | 0.83258 | |
| NAB NYC taxi | Precision | 0.73430 | 0.89275 | 0.88584 | 0.94607 | 0.93665 |
| Recall | 0.64736 | 0.87833 | 0.96715 | 1.00000 | 1.00000 | |
| F1 score | 0.67347 | 0.88548 | 0.92471 | 0.97229 | 0.96729 | |
| Particle-Matter dataset (ours) | Precision | 0.38288 | 0.75716 | 0.83033 | 0.90233 | 0.91326 |
| Recall | 0.27205 | 0.40998 | 0.52072 | 0.73905 | 0.79869 | |
| F1 score | 0.31809 | 0.53193 | 0.64005 | 0.80366 | 0.85214 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, D.H.; Nguyen, V.L.; Nguyen, H.; Jang, Y.M. Self-Supervised Learning for Time-Series Anomaly Detection in Industrial Internet of Things. Electronics 2022, 11, 2146. https://doi.org/10.3390/electronics11142146
Tran DH, Nguyen VL, Nguyen H, Jang YM. Self-Supervised Learning for Time-Series Anomaly Detection in Industrial Internet of Things. Electronics. 2022; 11(14):2146. https://doi.org/10.3390/electronics11142146
Chicago/Turabian StyleTran, Duc Hoang, Van Linh Nguyen, Huy Nguyen, and Yeong Min Jang. 2022. "Self-Supervised Learning for Time-Series Anomaly Detection in Industrial Internet of Things" Electronics 11, no. 14: 2146. https://doi.org/10.3390/electronics11142146