
NSVDNet: Normalized Spatial-Variant Diffusion Network for Robust Image-Guided Depth Completion

Abstract
:1. Introduction

- We design the uncertainty-aware diffusion network to enhance the robustness to depth measurement corruption, where the input depth uncertainty is integrated into the diffusion to avoid input noise from propagating to neighboring pixels;
- We implement the diffusion with the normalized spatial-variant diffusion (NSVD) module, which diffuses the input depth with spatial-variant kernels constructed from the semantic structural features extracted from the RGB image;
- We design the hierarchical deployment of NSVD modules to ensure both global smoothness and local detail preservation.
- We conduct extensive experiments to demonstrate that the proposed NSVDNet is more robust to input depth corruption than competing schemes. Additionally, the ablation study validates the design of the network architecture.
2. Related Works
2.1. Depth Completion
2.2. Affinity-Based Depth Completion
3. Normalized Spatial-Variant Diffusion
3.1. Problem Formulation and Solution Interpretation
3.2. Normalized Spatial-Variant Diffusion
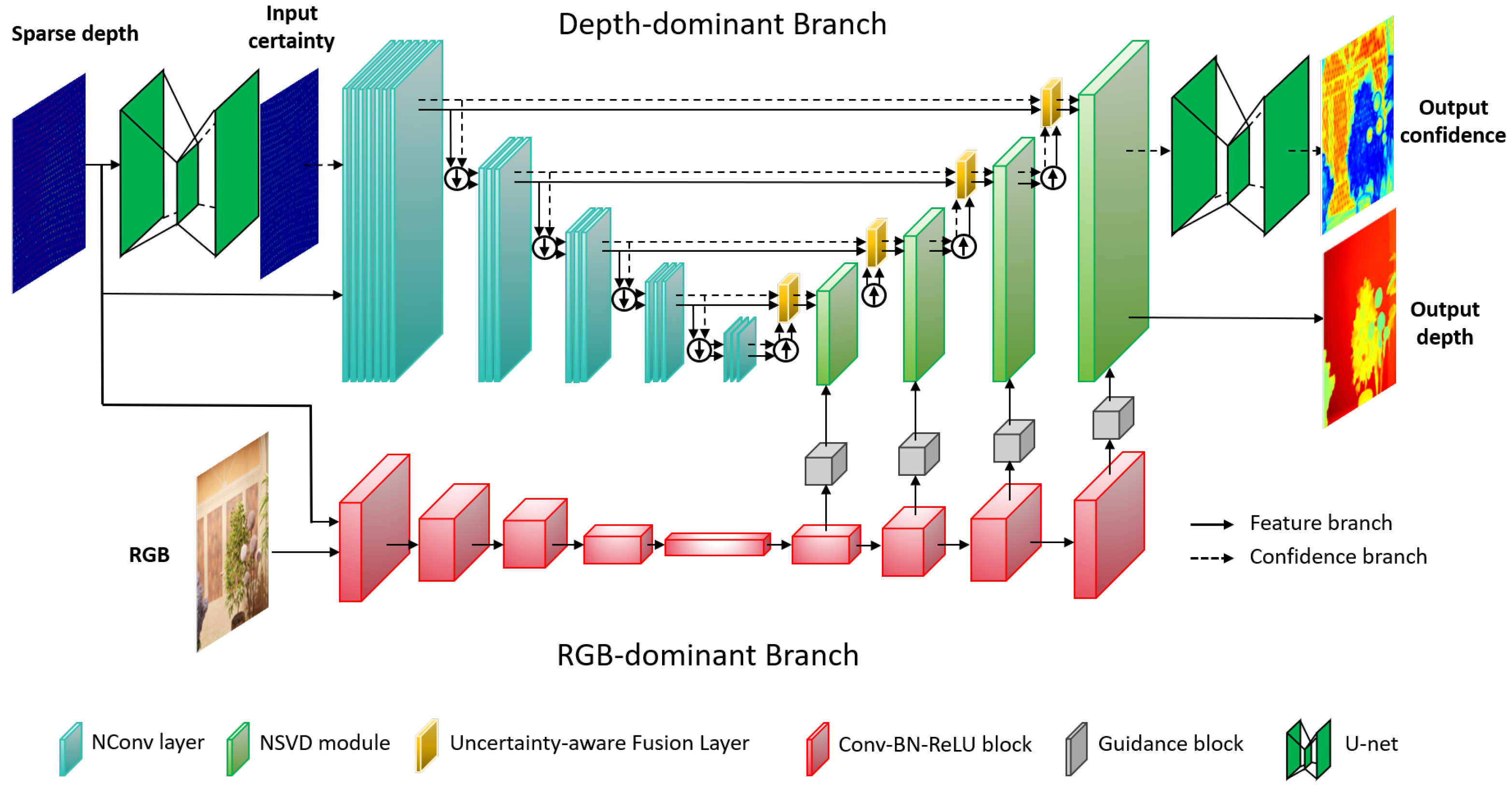
4. Network Architecture
4.1. Depth-Dominant Branch
4.2. Uncertainty-Aware Feature Fusion
4.3. RGB-Dominant Branch
4.4. Hierarchical Normalized Spatial-Variant Diffusion
4.5. Loss Function
5. Experimental Results
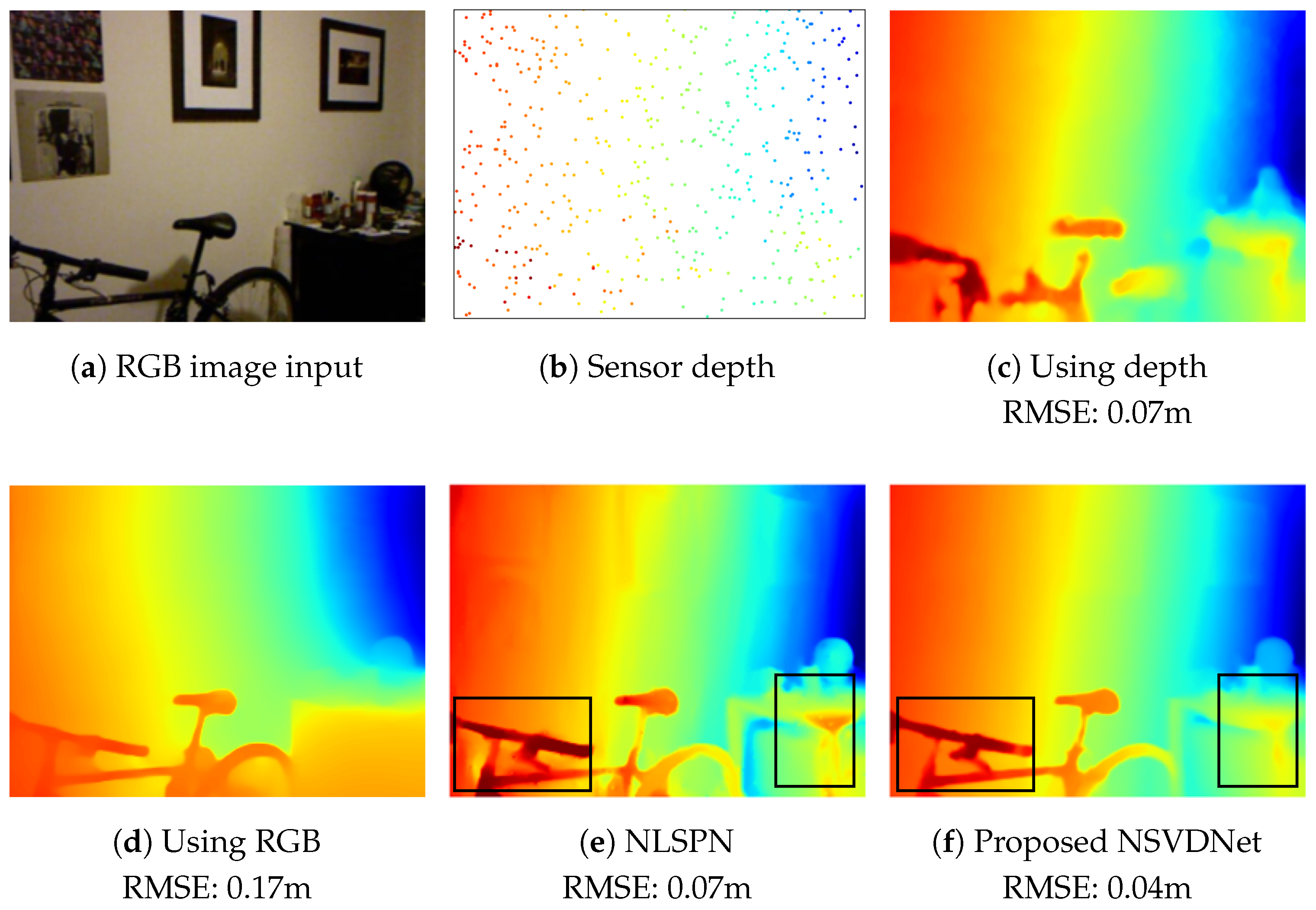
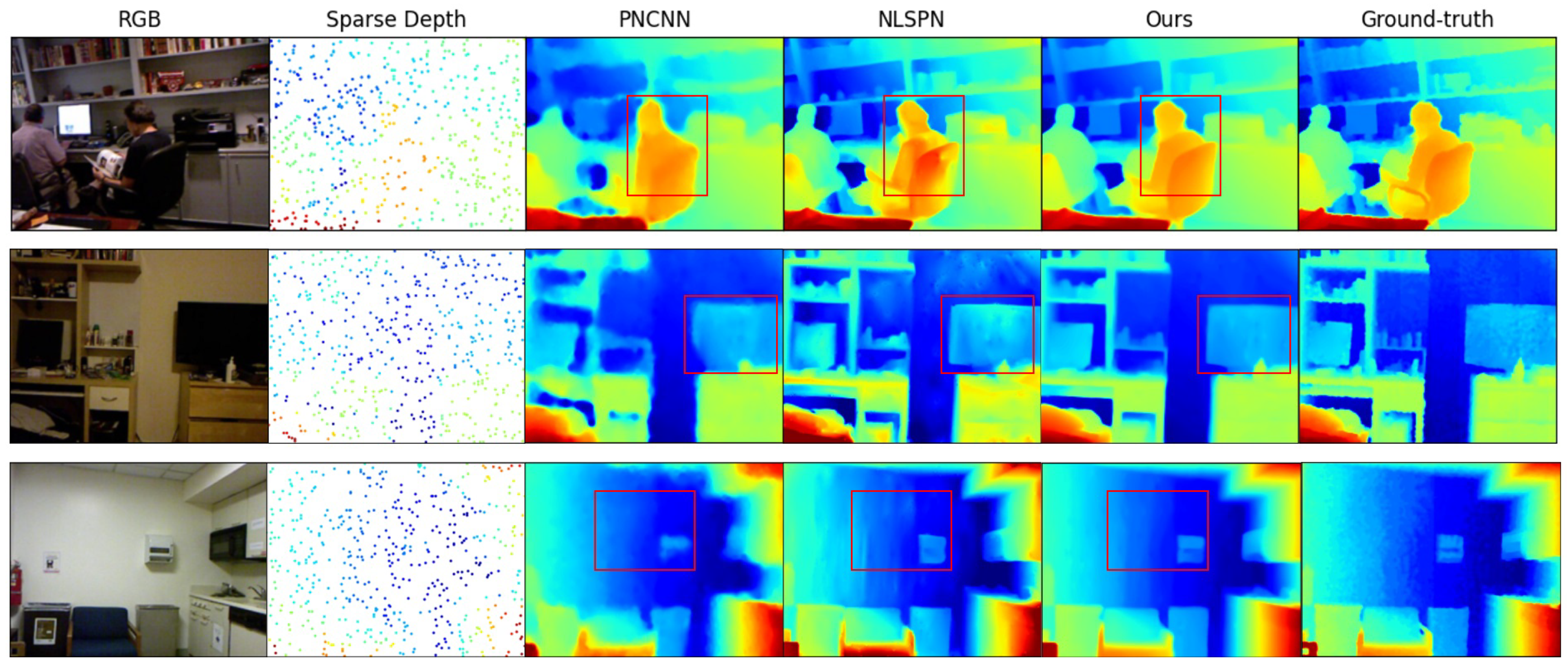
- In Section 5.2, we adopt the NYUv2 [12] and KITTI [20] datasets for evaluation in indoor and outdoor scenarios. The quantitative evaluation results using the two datasets are shown in Table 3 and Table 4, respectively, while the qualitative results further demonstrates the visual comparison using the NYUv2 dataset.
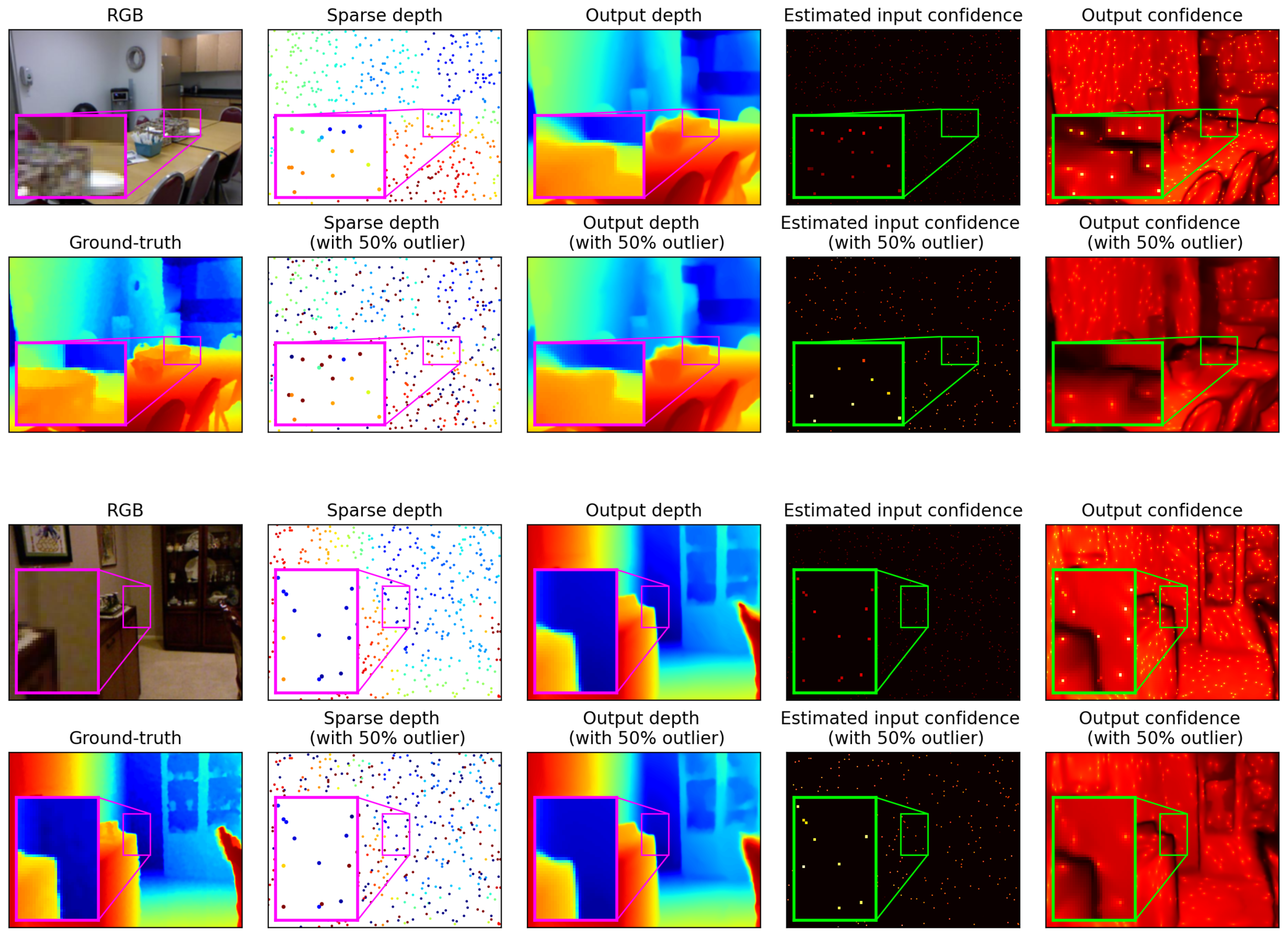
- In Section 5.3, we focus on the evaluation of robustness to input corruption in sparse depth, where we simulate corrupted sparse-depth using NYUv2 and show strong robustness of NSVDNet.
- In Section 5.3, we further test the generalization ability of NSVDNet to the new dataset via testing on the TetrasRGBD dataset [40] with the model trained on the NYUv2 noisy dataset. The visual results using simulated noise and the visual comparison with existing schemes using real sensor data are demonstrated, which validates that NSVDNet has a strong generalization ability to real usage scenarios.
- In Section 5.4, we present ablation studies to verify the effectiveness of each module in the NSVDNet.
5.1. Implementation Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Operator | # Operator | Input Dimension (H × W × D) | Output Dimension (H × W × D) |
|---|---|---|---|---|
| Input confidence estimator | UNet | 1 | 256 × 256 × 1 (sparse depth) | 256 × 256 × 1 (input certainty) |
| Encoder | NConv | 7 | 256 × 256 × (1+1) (sparse depth + input certainty) | 256 × 256 × 2 |
| MaxPool | 1 | 256 × 256 × 2 | 128 × 128 × 2 | |
| NConv | 3 | 128 × 128 × 2 | 128 × 128 × 2 | |
| MaxPool | 1 | 128 × 128 × 2 | 64 × 64 × 2 | |
| NConv | 3 | 64 × 64 × 2 | 64 × 64 × 2 | |
| MaxPool | 1 | 64 × 64 × 2 | 32 × 32 × 2 | |
| NConv | 3 | 32 × 32 × 2 | 32 × 32 × 2 | |
| MaxPool | 1 | 32 × 32 × 2 | 16 × 16 × 2 | |
| NConv | 3 | 16 × 16 × 2 | 16 × 16 × 2 | |
| Decoder | NN interpolation | 1 | 16 × 16 × 2 | 32 × 32 × 2 |
| Fusion | 1 | 32 × 32 × (2 + 2) | 32 × 32 × 2 | |
| NSVD | 1 | 32 × 32 × 2 | 32 × 32 × 2 | |
| NN interpolation | 1 | 32 × 32 × 2 | 64 × 64 × 2 | |
| Fusion | 1 | 64 × 64 × (2 + 2) | 64 × 64 × 2 | |
| NSVD | 1 | 64 × 64 × 2 | 64 × 64 × 2 | |
| NN interpolation | 1 | 64 × 64 × 2 | 128 × 128 × 2 | |
| Fusion | 1 | 128 × 128 × (2 + 2) | 128 × 128 × 2 | |
| NSVD | 1 | 128 × 128 × 2 | 128 × 128 × 2 | |
| NN interpolation | 1 | 128 × 128 × 2 | 256 × 256 × 2 | |
| Fusion | 1 | 256 × 256 × (2 + 2) | 256 × 256 × 2 | |
| NSVD | 1 | 256 × 256 × 2 | 256 × 256 × (1 + 1) (output depth + confidence feature) | |
| Output confidence estimator | UNet | 1 | 256 × 256 × 1 (confidence feature) | 256 × 256 × 1 (output confidence) |
| Module | Layer | Input Dimension (H × W × D) | Output Dimension (H × W × D) |
|---|---|---|---|
| Encoder | Conv-BN-ReLU | 256 × 256 × (1 + 3) | 256 × 256 × 64 |
| (sparse depth + RGB image) | |||
| Encoder | ResNet34-layer1 | 256 × 256 × 64 | 256 × 256 × 64 |
| Encoder | ResNet34-layer2 | 256 × 256 × 64 | 128 × 128 × 128 |
| Encoder | ResNet34-layer3 | 128 × 128 × 128 | 64 × 64 × 256 |
| Encoder | ResNet34-layer4 | 64 × 64 × 256 | 32 × 32 × 512 |
| Encoder | Conv-BN-ReLU | 32 × 32 × 512 | 16 × 16 × 512 |
| Decoder | Convt-BN-ReLU | 16 × 16 × 512 | 32 × 32 × 256 |
| Guidance | Conv-BN-ReLU | 32 × 32 × (256 + 512) | 32 × 32 × 64 |
| Conv-BN-ReLU | 32 × 32 × 64 | 32 × 32 × 9 | |
| Decoder | Convt-BN-ReLU | 32 × 32 × (256 + 512) | 64 × 64 × 128 |
| Guidance | Conv-BN-ReLU | 64 × 64 × (128 + 256) | 64 × 64 × 64 |
| Conv-BN-ReLU | 64 × 64 × 64 | 64 × 64 × 9 | |
| Decoder | Convt-BN-ReLU | 64 × 64 × (128 + 256) | 128 × 128 × 64 |
| Guidance | Conv-BN-ReLU | 128 × 128 × (64 + 128) | 128 × 128 × 64 |
| Conv-BN-ReLU | 128 × 128 × 64 | 128 × 128 × 9 | |
| Decoder | Convt-BN-ReLU | 128 × 128 × (64 + 128) | 256 × 256 × 64 |
| Guidance | Conv-BN-ReLU | 256 × 256 × (64 + 64) | 256 × 256 × 64 |
| Conv-BN-ReLU | 256 × 256 × 64 | 256 × 256 × 9 |
- The Root Mean Squared Error (RMSE):;
- The Mean Absolute Error (MAE):;
- The Root Mean Squared Error of the inverse depth (iRMSE):;
- The Mean Absolute Error of the inverse depth (iMAE):;
5.2. Main Results
| Method | Runtime | # Params. | RMSE | MAE | iRMSE | iMAE |
|---|---|---|---|---|---|---|
| (s) | (M) | (m) | (m) | (1/m) | (1/m) | |
| Sparse2dense | 0.010 | 42.82 | ||||
| NCONV | 0.003 | 0.670 | 0.1232 | 0.0491 | 0.0176 | 0.0067 |
| CSPN | 0.020 | 17.41 | 0.1183 | 0.0472 | 0.0183 | 0.0071 |
| NLSPN | 0.016 | 25.84 | ||||
| Proposed NSVDNet | 0.009 | 29.14 | 0.0908 | 0.0338 | 0.0129 | 0.0045 |
| Method | RMSE | MAE | iRMSE | iMAE |
|---|---|---|---|---|
| (mm) | (mm) | (1/km) | (1/km) | |
| Sparse2dense | 1299.851 | 350.326 | 4.073 | 1.576 |
| NCONV | 1009.258 | 238.692 | 2.917 | 1.007 |
| CSPN | 1019.64 | 279.46 | 2.932 | 1.151 |
| PENet | 757.197 | 209.001 | 2.222 | 0.923 |
| NLSPN | 741.685 | 199.594 | 1.994 | 0.845 |
| NSVDNet | 739.645 | 196.451 | 2.032 | 0.832 |
5.3. Data with Corruption
5.4. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dong, X.; Garratt, M.A.; Anavatti, S.G.; Abbass, H.A. Towards real-time monocular depth estimation for robotics: A survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16940–16961. [Google Scholar] [CrossRef]
- Fu, C.; Mertz, C.; Dolan, J.M. Lidar and monocular camera fusion: On-road depth completion for autonomous driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 273–278. [Google Scholar]
- Kahn, S. Reducing the gap between Augmented Reality and 3D modeling with real-time depth imaging. Virtual Real. 2013, 17, 111–123. [Google Scholar] [CrossRef]
- Nowak, M.K. WeaveNet: Solution for Variable Input Sparsity Depth Completion. Electronics 2022, 11, 2222. [Google Scholar] [CrossRef]
- El-Yabroudi, M.Z.; Abdel-Qader, I.; Bazuin, B.J.; Abudayyeh, O.; Chabaan, R.C. Guided Depth Completion with Instance Segmentation Fusion in Autonomous Driving Applications. Sensors 2022, 22, 9578. [Google Scholar] [CrossRef] [PubMed]
- Eldesokey, A.; Felsberg, M.; Holmquist, K.; Persson, M. Uncertainty-aware cnns for depth completion: Uncertainty from beginning to end. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12014–12023. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-LiDAR++: Accurate Depth for 3D Object Detection in Autonomous Driving. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Lu, Y.; Zhou, D.; Le, Q.V.; et al. Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Park, J.; Joo, K.; Hu, Z.; Liu, C.K.; So Kweon, I. Non-local spatial propagation network for depth completion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 120–136. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Ren, W.; Jin, N.; OuYang, L. Phase Space Graph Convolutional Network for Chaotic Time Series Learning. IEEE Trans. Ind. Inform. 2024, 20, 7576–7584. [Google Scholar] [CrossRef]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4796–4803. [Google Scholar]
- Zhao, S.; Gong, M.; Fu, H.; Tao, D. Adaptive context-aware multi-modal network for depth completion. IEEE Trans. Image Process. 2021, 30, 5264–5276. [Google Scholar] [CrossRef] [PubMed]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niebner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 667–676. [Google Scholar]
- Zeng, J.; Tong, Y.; Huang, Y.; Yan, Q.; Sun, W.; Chen, J.; Wang, Y. Deep surface normal estimation with hierarchical RGB-D fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6153–6162. [Google Scholar]
- Shlezinger, N.; Whang, J.; Eldar, Y.C.; Dimakis, A.G. Model-based deep learning. Proc. IEEE 2023, 111, 465–499. [Google Scholar] [CrossRef]
- Zeng, J.; Pang, J.; Sun, W.; Cheung, G. Deep graph Laplacian regularization for robust denoising of real images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant CNNs. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 11–20. [Google Scholar]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Rüther, M.; Bischof, H. Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 993–1000. [Google Scholar]
- Herrera, D.; Kannala, J.; Ladický, L.U.; Heikkilä, J. Depth map inpainting under a second-order smoothness prior. In Proceedings of the Scandinavian Conference on Image Analysis, Espoo, Finland, 17–20 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 555–566. [Google Scholar]
- Schneider, N.; Schneider, L.; Pinggera, P.; Franke, U.; Pollefeys, M.; Stiller, C. Semantically guided depth upsampling. In Proceedings of the German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 37–48. [Google Scholar]
- Huang, Z.; Fan, J.; Cheng, S.; Yi, S.; Wang, X.; Li, H. Hms-net: Hierarchical multi-scale sparsity-invariant network for sparse depth completion. IEEE Trans. Image Process. 2019, 29, 3429–3441. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Song, X.; Sun, J.; Lyu, X.; Li, L.; Liu, Y.; Zhang, L. MFF-Net: Towards Efficient Monocular Depth Completion With Multi-Modal Feature Fusion. IEEE Robot. Autom. Lett. 2023, 8, 920–927. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, X.; Poggi, M.; Zhu, Z.; Huang, G.; Mattoccia, S. CompletionFormer: Depth completion with convolutions and vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18527–18536. [Google Scholar]
- Zhou, W.; Yan, X.; Liao, Y.; Lin, Y.; Huang, J.; Zhao, G.; Cui, S.; Li, Z. BEV@ DC: Bird’s-Eye View Assisted Training for Depth Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9233–9242. [Google Scholar]
- Qiu, J.; Cui, Z.; Zhang, Y.; Zhang, X.; Liu, S.; Zeng, B.; Pollefeys, M. Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3313–3322. [Google Scholar]
- Chen, Y.; Yang, B.; Liang, M.; Urtasun, R. Learning joint 2d-3d representations for depth completion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10023–10032. [Google Scholar]
- Liu, S.; De Mello, S.; Gu, J.; Zhong, G.; Yang, M.H.; Kautz, J. Learning affinity via spatial propagation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Cheng, X.; Wang, P.; Yang, R. Depth estimation via affinity learned with convolutional spatial propagation network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–119. [Google Scholar]
- Cheng, X.; Wang, P.; Guan, C.; Yang, R. Cspn++: Learning context and resource aware convolutional spatial propagation networks for depth completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 10615–10622. [Google Scholar]
- Hu, M.; Wang, S.; Li, B.; Ning, S.; Fan, L.; Gong, X. PENet: Towards Precise and Efficient Image Guided Depth Completion. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Knutsson, H.; Westin, C.F. Normalized and differential convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 15–17 June 1993; IEEE: Piscataway, NJ, USA, 1993; pp. 515–523. [Google Scholar]
- Milanfar, P. A tour of modern image filtering: New insights and methods, both practical and theoretical. IEEE Signal Process. Mag. 2012, 30, 106–128. [Google Scholar] [CrossRef]
- Perona, P.; Malik, J. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Eldesokey, A.; Felsberg, M.; Khan, F.S. Confidence propagation through cnns for guided sparse depth regression. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2423–2436. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sun, W.; Zhu, Q.; Li, C.; Feng, R.; Zhou, S.; Jiang, J.; Yang, Q.; Loy, C.C.; Gu, J.; Hou, D.; et al. Mipi 2022 challenge on rgb+ tof depth completion: Dataset and report. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–20. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]





| Metrics | PNCNN + FC + OS-NSVD | PNCNN + FF + OS-NSVD | PNCNN + FF + MS-NSVD |
|---|---|---|---|
| MAE(m) | 0.0706 | 0.0677 | 0.0615 |
| RMSE(m) | 0.2704 | 0.2619 | 0.2447 |
| iMAE(1/m) | 0.0064 | 0.0061 | 0.0056 |
| iRMSE(1/m) | 0.0229 | 0.0221 | 0.0209 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, J.; Zhu, Q. NSVDNet: Normalized Spatial-Variant Diffusion Network for Robust Image-Guided Depth Completion. Electronics 2024, 13, 2418. https://doi.org/10.3390/electronics13122418
Zeng J, Zhu Q. NSVDNet: Normalized Spatial-Variant Diffusion Network for Robust Image-Guided Depth Completion. Electronics. 2024; 13(12):2418. https://doi.org/10.3390/electronics13122418
Chicago/Turabian StyleZeng, Jin, and Qingpeng Zhu. 2024. "NSVDNet: Normalized Spatial-Variant Diffusion Network for Robust Image-Guided Depth Completion" Electronics 13, no. 12: 2418. https://doi.org/10.3390/electronics13122418