An Efficient Multi-Level 2D DWT Architecture for Parallel Tile Block Processing with Integrated Quantization Modules


Abstract
:1. Introduction
2. Refinements to DWT and Quantization Formulas
2.1. Algorithm of Lifting-Based 2D DWT
2.2. Integration of Quantization and Scaling Formulas
3. Proposed Architecture for Multi-Level 2D DWT
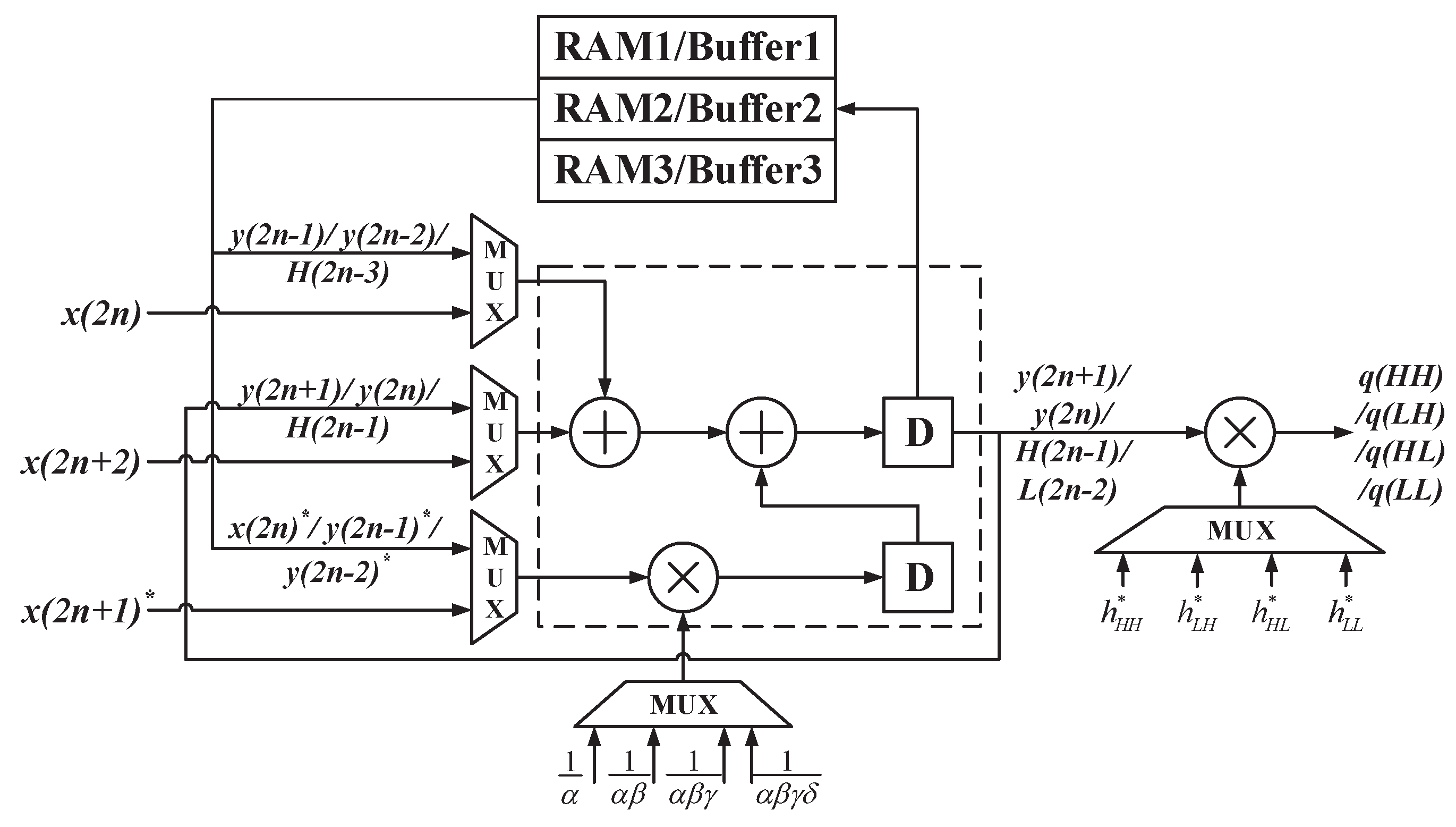
3.1. Folded and Unfolded Architecture
3.2. Data Input Method
3.3. Overall DWT Hardware Architecture
3.4. Simplified Control Module
3.5. Transposing Module
4. Results
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Christopoulos, C.; Skodras, A.; Ebrahimi, T. The JPEG2000 still image coding system: An overview. IEEE Trans. Consum. Electron. 2000, 46, 1103–1127. [Google Scholar] [CrossRef]
- Li, B.F.; Dou, Y.; Shao, Q. Efficient Memory Subsystem for High Throughput JPEG2000 2D-DWT Encoder. In Proceedings of the 2008 Congress on Image and Signal Processing, Sanya, China, 27–30 May 2008; Volume 1, pp. 529–533. [Google Scholar] [CrossRef]
- Jain, N.; Singh, M.; Mishra, B. Image Compression Using 2D-Discrete Wavelet Transform on a Light Weight Reconfigurable Hardware. In Proceedings of the 2018 31st International Conference on VLSI Design and 2018 17th International Conference on Embedded Systems (VLSID), Pune, India, 6–10 January 2018; pp. 61–66. [Google Scholar] [CrossRef]
- Karthigaikumar, P.; Anumol; Baskaran, K. FPGA Implementation of High Speed Low Area DWT Based Invisible Image Watermarking Algorithm. Procedia Eng. 2012, 30, 266–273. [Google Scholar] [CrossRef]
- Hajjaji, M.A.; Gafsi, M.; Ben Abdelali, A.; Mtibaa, A. FPGA Implementation of Digital Images Watermarking System Based on Discrete Haar Wavelet Transform. Secur. Commun. Networks 2019, 2019, 17. [Google Scholar] [CrossRef]
- Oweiss, K.G.; Mason, A.; Suhail, Y.; Kamboh, A.M.; Thomson, K.E. A Scalable Wavelet Transform VLSI Architecture for Real-Time Signal Processing in High-Density Intra-Cortical Implants. IEEE Trans. Circuits Syst. I Regul. Pap. 2007, 54, 1266–1278. [Google Scholar] [CrossRef]
- Kotteri, K.; Bell, A.; Carletta, J. Design of multiplierless, high-performance, wavelet filter banks with image compression applications. IEEE Trans. Circuits Syst. I Regul. Pap. 2004, 51, 483–494. [Google Scholar] [CrossRef]
- Taubman, D.S.; Marcellin, M.W. JPEG2000 Image Compression Fundamentals, Standards and Practice; Kluwer Academic Publishers: New York, NY, USA, 2002; pp. 429–430. [Google Scholar]
- Wu, P.C.; Chen, L.G. An efficient architecture for two-dimensional discrete wavelet transform. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 536–545. [Google Scholar] [CrossRef]
- George, A.; P, J.E. Hardware-Efficient DWT Architecture for Image Processing in Visual Sensors Networks. IEEE Sens. J. 2023, 23, 5382–5390. [Google Scholar] [CrossRef]
- Cheng, C.; Parhi, K.K. High-Speed VLSI Implementation of 2-D Discrete Wavelet Transform. IEEE Trans. Signal Process. 2008, 56, 393–403. [Google Scholar] [CrossRef]
- Naseer, R.A.; Nasim, M.; Sohaib, M.; Younis, C.J.; Mehmood, A.; Alam, M.; Massoud, Y. VLSI architecture design and implementation of 5/3 and 9/7 lifting Discrete Wavelet Transform. Integration 2022, 87, 253–259. [Google Scholar] [CrossRef]
- Zhang, W.; Jiang, Z.; Gao, Z.; Liu, Y. An Efficient VLSI Architecture for Lifting-Based Discrete Wavelet Transform. IEEE Trans. Circuits Syst. II Express Briefs 2012, 59, 158–162. [Google Scholar] [CrossRef]
- Tian, X.; Wu, L.; Tan, Y.H.; Tian, J.W. Efficient Multi-Input/Multi-Output VLSI Architecture for Two-Dimensional Lifting-Based Discrete Wavelet Transform. IEEE Trans. Comput. 2011, 60, 1207–1211. [Google Scholar] [CrossRef]
- Mohanty, B.K. Approximate Lifting 2-D DWT Hardware Design for Image Encoder of Wireless Visual Sensors. IEEE Sens. J. 2023, 23, 7868–7878. [Google Scholar] [CrossRef]
- Darji, A.; Agrawal, S.; Oza, A.; Sinha, V.; Verma, A.; Merchant, S.N.; Chandorkar, A.N. Dual-Scan Parallel Flipping Architecture for a Lifting-Based 2-D Discrete Wavelet Transform. IEEE Trans. Circuits Syst. II Express Briefs 2014, 61, 433–437. [Google Scholar] [CrossRef]
- Bharadwaja, P. Efficient FPGA Implementations of Lifting based DWT using Partial Reconfiguration. In Proceedings of the 2023 36th International Conference on VLSI Design and 2023 22nd International Conference on Embedded Systems (VLSID), Hyderabad, India, 8–12 January 2023; pp. 319–324. [Google Scholar] [CrossRef]
- Xiong, C.Y.; Tian, J.W.; Liu, J. Efficient high-speed/low-power line-based architecture for two-dimensional discrete wavelet transform using lifting scheme. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 309–316. [Google Scholar] [CrossRef]
- Kotteri, K.; Barua, S.; Bell, A.; Carletta, J. A comparison of hardware implementations of the biorthogonal 9/7 DWT: Convolution versus lifting. IEEE Trans. Circuits Syst. II: Express Briefs 2005, 52, 256–260. [Google Scholar] [CrossRef]
- Mohanty, B.K.; Meher, P.K. Memory Efficient Modular VLSI Architecture for Highthroughput and Low-Latency Implementation of Multilevel Lifting 2-D DWT. IEEE Trans. Signal Process. 2011, 59, 2072–2084. [Google Scholar] [CrossRef]
- Wu, C.; Zhang, W.; Jia, Q.; Liu, Y. Hardware efficient multiplier-less multi-level 2D DWT architecture without off-chip RAM. IET Image Process. 2017, 11, 362–369. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, C.; Zhang, P.; Liu, Y. An Internal Folded Hardware-Efficient Architecture for Lifting-Based Multi-Level 2-D 9/7 DWT. Appl. Sci. 2019, 9, 4635. [Google Scholar] [CrossRef]
- Hu, Y.; Jong, C.C. A Memory-Efficient High-Throughput Architecture for Lifting-Based Multi-Level 2-D DWT. IEEE Trans. Signal Process. 2013, 61, 4975–4987. [Google Scholar] [CrossRef]
- Chaker, A.; Kaaniche, M.; Benazza-Benyahia, A.; Antonini, M. An efficient statistical-based retrieval approach for JPEG2000 compressed images. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 1830–1834. [Google Scholar] [CrossRef]
- Moreno-Escobar, J.J.; Morales-Matamoros, O.; Tejeida-Padilla, R. SQbSN: JPEG2000 scalar quantizer implemented by means a statistical normalization. In Proceedings of the 2017 Intelligent Systems Conference (IntelliSys), London, UK, 7–8 September 2017; pp. 576–584. [Google Scholar] [CrossRef]
- Huang, C.T.; Tseng, P.C.; Chen, L.G. Flipping structure: An efficient VLSI architecture for lifting-based discrete wavelet transform. IEEE Trans. Signal Process. 2004, 52, 1080–1089. [Google Scholar] [CrossRef]
- Bartrina-Rapesta, J.; Aulí-Llinàs, F. Cell-Based Two-Step Scalar Deadzone Quantization for High Bit-Depth Hyperspectral Image Coding. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1893–1897. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subband | h | |
|---|---|---|
| HH1 | 1.040466 | 0.008674635 |
| HL1 | 1.011230 | 0.002468401 |
| LH1 | 1.011230 | 0.002468401 |
| HH2 | 1.934753 | 0.016130537 |
| HL2 | 1.997070 | 0.004874826 |
| LH2 | 1.997070 | 0.004874826 |
| HH3 | 4.160461 | 0.034686842 |
| HL3 | 4.183838 | 0.010212703 |
| LH3 | 4.183838 | 0.010212703 |
| HH4 | 8.605042 | 0.071742466 |
| HL4 | 8.542175 | 0.020851355 |
| LH4 | 8.542175 | 0.020851355 |
| HH5 | 17.392761 | 0.145007958 |
| HL5 | 17.173950 | 0.041921423 |
| LH5 | 17.173950 | 0.041921423 |
| LL5 | 16.995850 | 0.012146502 |
| LL1-LL4 | 1 | 0.000714675 |
| cnt3[3:0] | cnt4[1:0] | cnt5[1:0] | Level | Module |
|---|---|---|---|---|
| 0–3 | x | x | 3 | 1 |
| 4–7 | x | x | 3 | 2 |
| 8–11 | x | x | 3 | 3 |
| 9–12 | 1 | x | 4 | 1 |
| 9–12 | 2 | x | 4 | 2 |
| 9–12 | 3 | x | 4 | 3 |
| 9–12 | 4 | 1 | 5 | 1 |
| 9–12 | 4 | 2 | 5 | 2 |
| 9–12 | 4 | 3 | 5 | 3 |
| 9–12 | 4 | 4 | N | N |
| Level | Multiplier | Adder | Register | Temporal RAM | Parallelism |
|---|---|---|---|---|---|
| 1 | 10 | 16 | 26 | S | |
| 2 | 3 | 4 | 16 | S | |
| 3 | 3 | 4 | 40 | ||
| 3, 4, 5 | 3 | 4 | 112 | ||
| 1–5 | 42 | 64 | 238 |
| Architecture | Multiplier | Adder | Register | Internal Memory | Input Memory | Throughout Rate | CPD | TC | ACT | TDP |
|---|---|---|---|---|---|---|---|---|---|---|
| [10] | 195 | 270 | 540 | x | x | x | x | x | ||
| [12] | 0 | 330 | x | x | x | x | x | x | ||
| [14] | 60 | 120 | 3567 | 12,310 | 1152 | 25.71 | 2730.67 | 84.53 | ||
| [20] | 43 | 76 | 1410 | 128 | 896 | 7.16 | 2730.67 | 23.55 | ||
| [22] | 56 | 88 | 318 | 816 | 896 | 5.75 | 5461.33 | 18.90 | ||
| [23] | 46 | 76 | 90 | 527 | 1664 | 5.06 | 2730.67 | 12.47 | ||
| Proposed | 42 | 64 | 238 | 2392 | 1152 | 6.47 | 2730.67 | 10.63 |
| Architecture | N | S | Level | DAT (ns) | Area (m2) | Power (mw) | ADP (m2) | EPI (J) |
|---|---|---|---|---|---|---|---|---|
| [14] | 512 | 8 | 3 | 42.66 | 3,377,870.70 | 24.45 | 3098.72 | 26.28 |
| [20] | 512 | 8 | 3 | 45.58 | 3,104,371.05 | 22.59 | 2318.29 | 18.50 |
| [22] | 512 | 8 | 3 | 27.70 | 1,362,035.87 | 12.94 | 618.14 | 10.60 |
| Proposed | 512 | 8 | 3 | 26.74 | 999,231.90 | 23.70 | 433.35 | 19.42 |
| Proposed | 128 | 3 | 5 | 14.62 | 409,442.04 | 16.66 | 16.35 | 2.27 |
| Architecture | Device | S | Level | Fmax (MHz) | Registers | LUTs |
|---|---|---|---|---|---|---|
| [4] | XC6VSX315T | 1 | 2 | 344.34 | 3922 | 4708 |
| [5] | XC5VLX330T | 1 | 2 | 224.00 | 1536 | 2092 |
| [17] | XC7Z020CLG484 | 1 | 1 | 34.83 | 327 | 1121 |
| Proposed | XC6VSX315T | 1 | 2 | 165.75 | 1173 | 1679 |
| XC5VLX330T | 1 | 2 | 188.89 | 1179 | 1631 | |
| XC7Z020CLG484 | 1 | 1 | 143.70 | 629 | 602 | |
| XC6VSX315T | 3 | 5 | 149.12 | 6974 | 11,379 | |
| XC5VLX330T | 3 | 5 | 156.92 | 7064 | 11,546 | |
| XC7Z020CLG484 | 3 | 5 | 130.14 | 6974 | 11,378 | |
| XC7K325T | 3 | 5 | 169.27 | 6978 | 11,378 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Zhang, W.; Wu, Z.; Dai, Y.; Liu, Y. An Efficient Multi-Level 2D DWT Architecture for Parallel Tile Block Processing with Integrated Quantization Modules. Electronics 2024, 13, 4668. https://doi.org/10.3390/electronics13234668
Li Q, Zhang W, Wu Z, Dai Y, Liu Y. An Efficient Multi-Level 2D DWT Architecture for Parallel Tile Block Processing with Integrated Quantization Modules. Electronics. 2024; 13(23):4668. https://doi.org/10.3390/electronics13234668
Chicago/Turabian StyleLi, Qitao, Wei Zhang, Zhuolun Wu, Yuzhou Dai, and Yanyan Liu. 2024. "An Efficient Multi-Level 2D DWT Architecture for Parallel Tile Block Processing with Integrated Quantization Modules" Electronics 13, no. 23: 4668. https://doi.org/10.3390/electronics13234668
APA StyleLi, Q., Zhang, W., Wu, Z., Dai, Y., & Liu, Y. (2024). An Efficient Multi-Level 2D DWT Architecture for Parallel Tile Block Processing with Integrated Quantization Modules. Electronics, 13(23), 4668. https://doi.org/10.3390/electronics13234668