1. Introduction
Sleep studies and in-bed related conditions are in high demand for patient’s health supervision and can be improved through the use of Machine Learning (ML)-assisted systems with the ability to detect when a specific patient needs assistance. Features such as these allow reduction in the effort of healthcare professionals. However, systems that would allow such an easing of burden require trained datasets. As health-related systems require critical accuracy, the data included in these datasets are crucial and all their parameters are very important when developing systems in this field. In such a scenario, solutions that combine the Internet of Things (IoT) and ML can help monitor patients’ posture and can provide support to caregivers’ activities, avoiding unnecessary overburdening and/or caregiver burnout. Usually, these solutions rely on the use of some type of sensor-based solutions (e.g., beds equipped with sensors [
1], physiological signals and polysomnography [
2]), camera-based solutions [
3], or pressure mattresses [
4]. In this context, solutions based on pressure maps are not intrusive for patients and have been successfully used in numerous healthcare applications. Pressure maps represent the pressure distribution under in-bed patients’ body parts in different in-bed postures, and they are typically built using matrix-pressure-sensor sheets placed over the mattress. They have been used for in-bed body posture estimation [
5,
6], measurement of physiological signals (e.g., respiration [
7,
8]), pressure ulcer prevention [
9,
10,
11], sleep studies [
8,
12,
13], and bed-fall detection [
11]. However, to develop, train, and validate many of these solutions, datasets are required that include pressure maps of a significant number of participants, with different characteristics and in different body positions.
However, the construction of these datasets is not easy, and many researchers often resort to the existing datasets to aid their studies. Therefore, finding a quality dataset, or building a new dataset, is a decision that must be made and is a fundamental requirement to build and validate any posture recognition-based healthcare application.
The purpose of this review was to find datasets about lying people’s or bedded people’s positions and characterise the existing datasets with respect to the methods used for data collection, the fields considered in the datasets, and the result or their possible uses after collection. The foci for these approaches would then result in a set of research questions that describe not only what the datasets included but also how they were built, what they were, and what they could be used for. The data gathered would then be used to answer the following set of research questions:
RQ1: What was the purpose of using pressure datasets?
RQ2: What data were included in the dataset?
RQ3: How was the participant population distributed?
RQ4: How many poses were considered for the dataset?
RQ5: What was the size of the resulting dataset?
RQ6: What information is available regarding the pressure data?
The answers to these questions would help identify the most common and most important aspects and identify the essential attributes in a lying-posture dataset.
The review was organised according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement [
14]. This process included identifying the purpose and the intended goals of the review, searching for the literature, formulating the inclusion and exclusion criteria, data extraction and analysis, discussion, and writing of the review.
The remainder of this article is organised as follows. In
Section 2 we describe and apply the methodology chosen to perform this review, and we present the search strategy, the inclusion and exclusion criteria and the results, which are subsequently analyzed in
Section 3 and discussed in
Section 4. In
Section 5 we identify the strengths and limitations of this review and finally, in
Section 6, we draw some conclusions.
3. Analysis of Included Studies
With the list of studies to be included in this review decided, in this section, these studies were analysed in depth with respect to their content, focusing on the information required to answer the aforementioned research questions. The information displayed in
Table 1 answers most of the questions with each row representing one of the papers included in the review. The Dataset Title (Availability) column displays the title of the dataset and whether it is available for public use according to the authors of the specific paper.
For each of the papers listed in the table above, a small summary was created and is presented below in the same order as shown in the table. The major focus of the summary was to find the purpose of the work, the data used for achieving it, how those data were gathered and the participants’ distribution, the parameters chosen by the authors, and lastly, the results of the work.
With the consideration that the datasets developed and used in the studies analysed were used for recognition purposes using machine-learning algorithms, the resulting accuracy of the algorithms using the said datasets was included in the analysis of each work when available; this accuracy (represented as a percentage) displayed how likely the algorithm developed was of accurately predicting the position or posture of a certain bedded individual, having used a dataset for its training, which was analysed in detail for each of the papers considered in this review.
Simultaneously Collected Multimodal Lying Pose Dataset: Towards In-Bed Human Pose Monitoring under Adverse Vision Conditions [
15] intended to gather important data for pose estimation and monitoring for in-bed scenarios specifically, as the authors found that the existing datasets in the 2D human-pose datasets field had ambiguity issues. The data were gathered using multiple methods: through RGB imaging (pictures); thermal imaging; depth imaging; and pressure mapping. They were then paired with the relevant clinical data, including height, weight, sex, bust size, hip size, and limb sizes.
The authors presented a very complete dataset gathering data from 109 different individuals, with slightly distributed parameters throughout the data having 78 male and 31 female subjects ranging from 150 to 190 cm in height and from 30 to 120 kg in weight, implying that the resulting dataset had a good representation of different body types and led to better pose estimation.
This work considered 15 different poses for the data collection, evenly distributed between three main poses, namely supine, left facing, and right facing, having five random poses for each of these main poses. There were different samples taken for uncovered, covered with a thin sheet, and covered with a heavy blanket, resulting in 15,000 pose samples for in-bed study use.
The data were collected without a pillow, considering only the covers which did not affect the pressure maps. The hardware used for data collection was not specified in the paper, and the pressure maps specifically were collected with a pressure-sensing mat, but there was no information regarding the size of the mattress or the sensor count. The poses considered for this work were counted to be 15, but when it came to pose estimation, only three could be accounted for as there were five different poses for each of the three main poses, and they were chosen at random by the participant.
A pressure-map dataset for posture and subject analytics [
4] presented the development work for, according to the authors, the first publicly available dataset of lying-pose pressure maps. The data were collected in two different experiments by using two different pressure sensing mats; the first experiment used a mat consisting of a 64 × 32 pressure sensor matrix, and the second experiment used a smaller matrix mat with a 64 × 27 configuration.
The dataset was developed with the participation of 13 individuals, and their height, ranging from 169 to 186 cm; weight, ranging from 66 to 100 kg; and age, ranging from 19 to 34 years, were gathered as additional participant data, proven useful by the authors. The sex of the participants was not mentioned in the paper.
The postures were also gathered differently in the experiments, with the first experiment having eight postures considered, with some of them being variations of some of the main postures considered in the lying pressure-map field, namely supine, left facing, and right facing. The second experiment had only the three main postures included. In all of the frames captured, the participants had a standard pillow under their head.
The sampling was taken every second for around 2 min for each posture recorded, which generated a large sample size of 26,000, but some of them were repeats as the participants did not shift their position during the 2 min period. The authors of this paper decided to gather the participants’ age, which was not commonly found in other similar work, but the authors used the participant data in subject identification, attempting to classify the different subjects, according to their information and the pressure maps gathered, with satisfactory accuracy, thus proving that the authors gathered discriminative information.
Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data [
16] presented an interesting approach to the dataset collection methods used in pressure-map dataset-development. The authors created a dataset with computer-generated data, using a simulated environment where a 3D model of a human lay on a pressure mat. This approach solved the challenge of real data collection, which could be difficult at scale.
Without real participants, the dataset included different body shapes, and the weight, height, and gender were still considered parameters in the dataset. The weight and height ranges were not discussed in the paper.
The postures for this dataset were divided into five groups, having 20 different postures for supine positions, 20 for prone positions, 20 for each left and right facing, and finally, 19 postures acquired through human interaction, where a group of 10 male and 10 female participants were asked to lay comfortably in these 19 different positions.
The dataset had only one sample for each of the postures, having one for every 99 for every different simulated ‘subject’.
To test the usefulness of the dataset, the authors developed a posture-recognition system which obtained only the generated pressure maps and the subject’s gender as the input and attempted to create a 3D model of the predicted posture; the results showed an accurate prediction from the input data, which indicated the importance of the selected parameters.
A smart IoT system for detecting the position of a lying person using a novel textile pressure sensor [
17] aimed to assist bedded-patient healthcare providers with an IoT bedside system that detected whether the patient was lying in a specific position for long periods, so that the health staff could be warned accordingly and the patient could be turned. This system was proposed in some other papers as pointed out by the authors in [
23], but the authors in this study proposed an approach using only a pressure map of the individual’s torso for posture classification.
Included in this work was the development of a dataset which included data from 18 male and 3 female participants with weights ranging from 45 to 125 kg. The data considered for the dataset were the pressure maps, consisting of 8 × 8 matrices with values ranging from 0 to 140, and the participants gender and weight, although only the weight and pressure maps were used in the posture classification.
The postures considered for the dataset were supine, prone, left facing, and right facing, and the participants were asked to shift their position slightly 30 times for each posture, which in total resulted in 120 different samples taken for each participant.
The parameters taken from the individuals did not include height, which was taken into consideration for most work in the field; however, as the pressure maps were only of the individual’s upper body, the individual’s height might not have influenced the results of the posture classification system.
The result of the posture-classification algorithm on the collected dataset ended up with an overall accuracy score of 82.22%, which was mostly lowered by the difference in the participant’s body weight according to the authors, because of the weight range of the participants.
In-Bed Posture Classification Based on Sparse Representation in Redundant Dictionaries [
18] used pressure maps for posture classification without using other parameters such as height or weight, in an attempt to find the differences between using the classification systems known as sparse representation classification and standard classification methods.
The dataset used to demonstrate the authors’ work gathered 736 different pressure images of six test subjects of various weights and heights that were undescribed with respect to their range. The pressure maps used were obtained from a pressure-sensing mat consisting of a 30 × 11 pressure-sensor matrix.
Four postures were considered for this work, namely supine, prone, left lateral, and right lateral.
Although the authors decided against the use of other participant characteristics such as weight, the resulting posture classifier still showed promising results, although lower than similar applications that included individual parameter use such as weight.
The prediction of the body weight of a person lying on a smart mat under non-restraint and unconsciousness conditions [
19] had a different goal than that of most of the work found in the search, attempting to predict the weight of the bedded individual that the authors gathered pressure maps for, as well as the weight of the lying person.
The gathered dataset had only 60 samples, from 12 participants, whose only parameter stored was their weight; as the goal of the work was to predict the weight specifically, no other data were required. The weight of the participants ranged from 56 to 89 kg, averaging 73 kg. The pressure sensing mat used was developed by the authors and contained a matrix of 8 × 16 pressure sensors evenly distributed along a 2.05 m × 0.85 m mattress to simulate a hospital environment.
As the goal was only to predict an individual’s weight using only their pressure information, no other parameters were gathered, and the dataset only accounted for one lying position (supine). The limited data gathered for the dataset made it usable in a more finite range of studies as most of the available datasets have other relevant information and additional samples.
The authors did go on to test the applicability of the weight prediction algorithm on the dataset and concluded that the array size of the pressure sensing mat resulted in a number of ‘dead zones’ where no pressure was detected which caused errors in the predictions. Furthermore, the authors stated that the results of the algorithm could be improved by using a larger dataset.
Pressure Image Recognition of Lying Positions Based on Multi-Feature Value Regularised Extreme Learning Algorithm [
20] presents a lying-position recognition system that uses not only the pressure data from the participant’s torso but also geometric values such as the perimeter and area of the pressure image for increased accuracy.
For testing their algorithm, the authors gathered a dataset consisting of 1280 samples, taken from 20 (10 male and 10 female) participants, including the pressure maps, represented in a 16 × 16 matrix with the pressure values, and the individual parameters included height, ranging from 160 to 180 cm; weight, ranging from 45 to 80 kg; and age ranging from 20 to 27 years. The authors also included post-processing data in their dataset, calculated using the pressure maps, and recorded the perimeter and area of the pressured body area for later use.
Apart from the use of only the pressure image of the torso, the data gathered for this work were very complete as they included the parameters that were gathered for most work in the field. The dataset also considered four different positions, namely supine, prone, left facing, and right facing.
The purpose of this work was to precisely predict the lying posture for the prevention of possible sleep- or bed-related diseases, particularly for long-term bedded patients. By using the proposed algorithm (RELM algorithm), the authors could predict the individual’s lying position with a 98.75% accuracy, which according to the authors resulted from the use of the multiple parameters for the prediction, both pressure related and those related to the individuals.
Blanket Accommodative Sleep Posture Classification System Using an Infrared Depth Camera: A Deep Learning Approach with Synthetic Augmentation of Blanket Conditions [
21] had the objective of accurately classifying different sleeping postures by using thermal image data, irrespective of the cover on the individual.
The dataset used for training and testing the proposed method, gathered by the authors, consisted of 1400 sample images, taken from 66 (40 male and 26 female) participants, accounting for different parameters, including their age (averaging 35.7 years with a standard deviation of 17.4 years), height (averaging 167 cm with a standard deviation of 18 cm), and weight (averaging 63 kg with a standard deviation of 12.23 kg).
Each sample contained the participant’s information along with a thermal image of the patient in one of seven different positions and in four different cover or blanket conditions. The different lying positions considered were supine, prone (one with the head facing the right and another the left), log (left and right), and foetal (left and right). The blanket conditions indicated the type of blanket on the participant for that sample, varying in thickness and material.
Although the dataset described in this work did not have any pressure information included, the inclusion of the different postures was relevant to their findings and could be helpful in pressure-map studies.
The methods for classification used by the authors were then divided into two different sets: one for classifying the position out of the seven postures gathered, and the other for classifying only four postures (supine, prone, left facing, and right facing). The four-posture classifier exhibited excellent results with 97.1% accuracy; in contrast, the seven-posture classifier had 88.9% accuracy, leading to the conclusion that using a larger dataset would improve the outcome of this work.
Human Posture Recognition Using a Hybrid of Fuzzy Logic and Machine Learning Approaches [
22] had two main purposes: first, creating a posture recognition system capable of not only recognising the posture of a certain lying individual but also determining the position of their limbs; second, gathering a dataset that could be used for the training of a posture-recognition system and made available to other researchers.
The dataset presented in this paper contained 19,800 different samples taken from 32 (16 male and 16 female) participants; the samples included the individual’s gender and age (ranging from 21 to 57 years) along with the RGB and depth images of the participants in one of the 20 different postures.
The postures selected for this work was derived from the statistical analysis of lying patients in hospital beds and were the result of categorising more than 1800 possible postures into the 20 most common ones.
The dataset was very complete with respect to postures but lacked some of the parameters that other datasets made available such as height and weight. Although the data collected were not related to pressure, the number of postures was relevant to this work as were the results of the study.
The author’s methods of classification achieved 97.1% accuracy, which was impressive considering that unlike most other works included in this review, this work classified 20 different positions; these positions were mostly variations of the four main positions used in most works (namely supine, prone, left facing, and right facing) but were differentiated in the classification procedure. Other fine-grained works in the field did not obtain high results. The reason for the high accuracy might be the use of depth imaging over pressure mapping.
4. Discussion
As the analysis of the included studies followed the research questions, the discussion is also sub-divided into six different paragraphs, each representing the discussion regarding the information taken from the analysis results for the research questions.
For a better understanding of how the different studies included in the review answered the questions, they were compared, and to further clarify how the majority of the works were developed, they were presented using a quantitative representation (out of nine, with nine being the total number of studies included), grouping the studies according to the similarities found.
The purpose of using pressure datasets (RQ1), according to the studies included in the review, was mostly lying-posture recognition, with seven out of nine focusing on lying-posture classification. Out of these, two aimed to aid sleep quality studies with posture recognition, two were concerned with pressure-ulcer prevention, and four aimed to predict a lying person’s posture so it could be used later. Of the two studies that did not intend to classify lying postures, one focused on weight prediction using pressure data alone and the other focused mostly on the data-gathering procedure.
With respect to the data included in the datasets (RQ2), eight out of the nine included the participants’ weight, six out of the nine studies included their height, six out of the nine included the sex (gender) of the participants, four of the nine included studies also used the participants’ age, and one study used body measurements (e.g., waist width and thigh width) for their datasets. On the basis of this information, and particularly after analysing each paper, the authors concluded that none of these characteristics stood out as more important with respect to the lying-position classification as each work regarded the characteristics gathered, albeit different from one another, important for their specific study. However, as different studies used different parameters and all of them ended with highly accurate results, they did not seem imperative to the resulting classification algorithms’ precision. All of these should still be considered in the development of new datasets when their collection is possible, considering that other works might use them for different purposes, as in the work in [
19], which predicted body weight and therefore requireed weight data to be included in the dataset. The purposes of these datasets are, however, not limited to posture recognition, and some studies suggest the usage of other factors for different purposes; for example, the authors in [
24] mentioned the use of age and weight for their study, and the study published in [
25] concluded that there were noticeable differences in the pressures registered from the trochanteric zone (hip area) depending on anthropomorphic factors and the participants’ gender. Thus, the inclusion of various individual characteristics is recommended as it will allow new and more complete studies to emerge from it.
Participant population distribution characteristics (RQ3) also allow future researchers to inspect how representative the dataset is, as having no information regarding the participants’ different body parameters has use for classifier demonstration, but if the goal is health related, the algorithms cannot be expected to perform as well on different people. This implies that not only is the participant count relevant but how diverse their characteristics are is also relevant. The authors of the studies included accurately described the population of their dataset, although some did not include information on how representative it was, stating only the minimum and maximum for a specific characteristic.
The poses considered for the dataset (RQ4) were one of the most important aspects of the works included in this review, as the possibilities for a human position while lying on a bed could be endless depending on how finely grained the considered postures were. With respect to the different poses, most of the works in this review (six out of nine) considered a smaller number of poses, up to eight, mostly represented by the four main lying postures (supine, prone, left facing, and right facing); however, one work included 15 postures, another included 20, and lastly, the study that used computer-generated data considered 99 different poses. The works that included fewer poses in their posture classification tended to achieve higher precision than those aiming for a finer-grained classifier, but a higher number of poses might be important for different medical uses, where knowing the exact position of a lying person might determine how a system reacts.
The size of the dataset (RQ5) or the number of samples in one is important when used for training machine-learning algorithms such as classifiers. The datasets considered in this study varied in size with five having 2500 or less, and the other four datasets having more than 15,000 samples. The accuracy of the resulting classifiers was not noticeably lower for the studies using smaller datasets necessarily, but these had a lower number of postures, which led to the conclusion that the larger the number of postures considered in the classification was, the larger the number of samples needed to be.
With respect to the information available regarding pressure data (RQ6), one of the most important aspects of pressure maps is their resolution, and the resolutions considered in the studies included in this review ranged from 64 sensors displayed in an 8 × 8 resolution to 2048 sensors in a 64 × 32 resolution. The precision of the pressure maps and the algorithms trained using such pressure maps increased according to how high the resolution was; however, studies with lower resolutions achieved high accuracy classifiers, either by using different parameters (weight, height, etc.) or by gathering the pressure of a specific body part, usually the torso for posture recognition. Furthermore, regarding pressure maps, more specifically, the hardware used to gather them, the position of the sensor sheets is on top of the mattress or bed, directly below the participant or with a sheet covering it for all the studies included in this review because the weight distribution dissipates through mattresses or other soft surfaces.
Although all the works included answered the research questions thought of for this review, there were a few gaps found while analysing each of the studies, namely (in the order they are listed in
Section 3):
Lack of hardware specification: this information can be useful for future researchers, not only the ones using already developed datasets but also researchers developing new datasets, by knowing the hardware used for the data collection procedure. Information such as resolution (image or pressure matrix resolution) or hardware dimensions could lead to researchers making informed decisions on the hardware used.
Regarding pressure maps, some of the studies did not include information on the resolution of the pressure maps in the datasets. As some studies aim for finer-grained posture classification, they need a higher resolution for accurate results, and if this information is not displayed, researchers will have a hard time finding an adequate dataset.
The postures chosen for the datasets vary depending on how many postures the researchers are attempting to classify. However, after an analysis of the studies in this review, the postures included in the lying-people datasets should include at least the four postures that are mostly used, namely supine, prone, left facing, and right facing, as these are the most common lying positions found in medical studies.
All of the studies included in this review included participant characteristics in their datasets. However, some of them did not describe their range, stating only that they used the participants’ weight, for example, but not describing how they varied; the inclusion of this information is important for clinical applications, as they can display how accurate the resulting applications will be, considering different anatomic proportions. With respect to participant characteristics, the participant distribution as to the characteristics is not always taken into consideration, and as human bodies have a nigh infinite number of different proportions, datasets that can be used in the clinical field of study should have a representative distribution in mind.
Another gap found was the dataset size. Some authors consider the main reason for low accuracy of the classification algorithms to be the limited sample size of the datasets, and this is mostly because of the difficulty of finding willing participants for data collection. Although one of the papers suggested using computer-generated data, the usage of such data might not be suitable for clinical applications.
Furthermore, the physical setup of the data collection procedure could be described in studies that present a new dataset to demonstrate not only what material or equipment is required for new dataset development but also the techniques used for it, such as the use of a graphical user interface or how the participants are informed of what they need to do for the data-collection procedure.
The analysis of the studies included in this review help highlight the important factors when developing a dataset in the considered field or choosing one for lying-people-related research. With the use of the predefined research questions, the information gathered showed how the datasets were used, what data were considered in them, how many participants were included in the making of the datasets, and which of their characteristics had to be considered. With the overall analysis complete, the gaps found were also addressed with the intent of informing researchers on information that was sometimes left undiscussed and should be included for the reasons described above.
6. Final Remarks
By following the PRISMA methodology, this systematic review aimed to find studies on the development and usage of datasets that included pressure maps in their compositions, synthesising the ones found appropriate for the purposes of this review and analysing them in full to gather the most useful information from them.
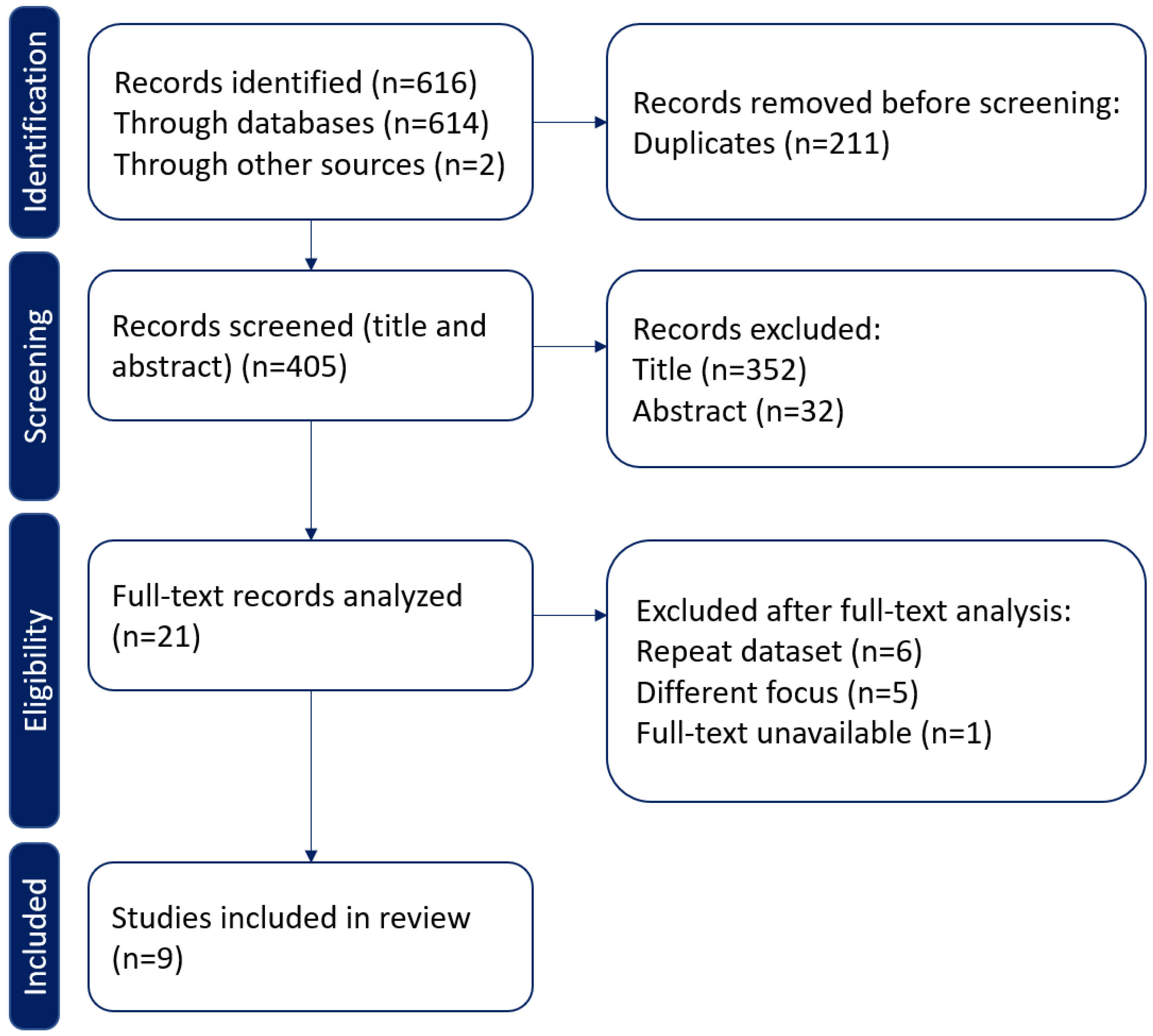
The literature search was conducted using three databases (Scopus, Web of Science, and PubMed), and after the literature search, 405 distinct studies were obtained, resulting in 21 studies after the application of inclusion and exclusion criteria. Finally, after the full-text evaluation of the remaining studies, 12 studies were excluded. The resulting list contained nine studies that were published between 2017 and 2022.
The results of this review revealed that most applications found for the field of pressure-map datasets were for posture recognition or simply pressure-level detection, which then would have numerous uses for clinical applications. The most commonly gathered participant parameters were analysed, and most studies seemed to include weight and height, but these parameters did not seem to make a relevant difference as the works that did not use them reported similar results. They should still be considered in the development of new datasets however, as they can be used for different studies. With these parameters, the population distribution can also be identified, which ensures that the resulting system will still function accordingly for different people.
The techniques used for gathering pressure data, such as the different poses considered, were analysed, and the results of the studies that included more postures tended to have greater difficulty in the posture-classification process, but considered the finer granularity to be worth the decrease in accuracy. Other parameters such as the sensor position, amount, and resulting resolution of the pressure maps were included, revealing many different approaches with all of them exhibiting high accuracy in the classification, albeit most had a low number of postures considered for recognition.
The dataset sizes were also included in the review, which is important for machine-learning algorithm-training, as more data usually results in a better model.
This review also made it possible to identify a set of gaps that, in some way, made a deeper analysis difficult, namely lack of information on hardware specification and on the physical setup of the data collection procedure, lack of information on the resolution of the pressure maps in the datasets, differences in the postures chosen for the datasets, lack of relevant information on participant characteristics, and, in some cases, a small number of participants in the dataset. It is therefore recommended that these gaps be analysed by future researchers in detail when developing new datasets or related work in the field.
The initial literature search resulted in a significant number of studies. However, after the application of inclusion and exclusion criteria, the final number of studies was relatively small. All of the analysed studies addressed the use of lying-people datasets, but they included various types of datasets. This might suggest that the availability of datasets for lying-people studies are not readily available and those that are available still vary in the type of data included, which might be an issue for researchers when using the datasets. Thus, the aim of this study was not only to conduct a review on pressure-map datasets to display the state-of-the-art datasets available, but also to give future researchers important information regarding the development of new datasets in the field of bedded or lying-people studies.







{kind=link}