Trends in Using IoT with Machine Learning in Health Prediction System


Abstract
:1. Introduction
2. ML Algorithms and Classification
2.1. Data in ML
2.2. Machine Learning Algorithm Classification
2.2.1. Supervised Learning
2.2.2. Unsupervised Learning
2.2.3. Semisupervised Learning
3. Commonly Used Machine Learning Methods
3.1. K-Nearest Neighbor (K-NN)
3.2. Naïve Bayes Classification (NBC)
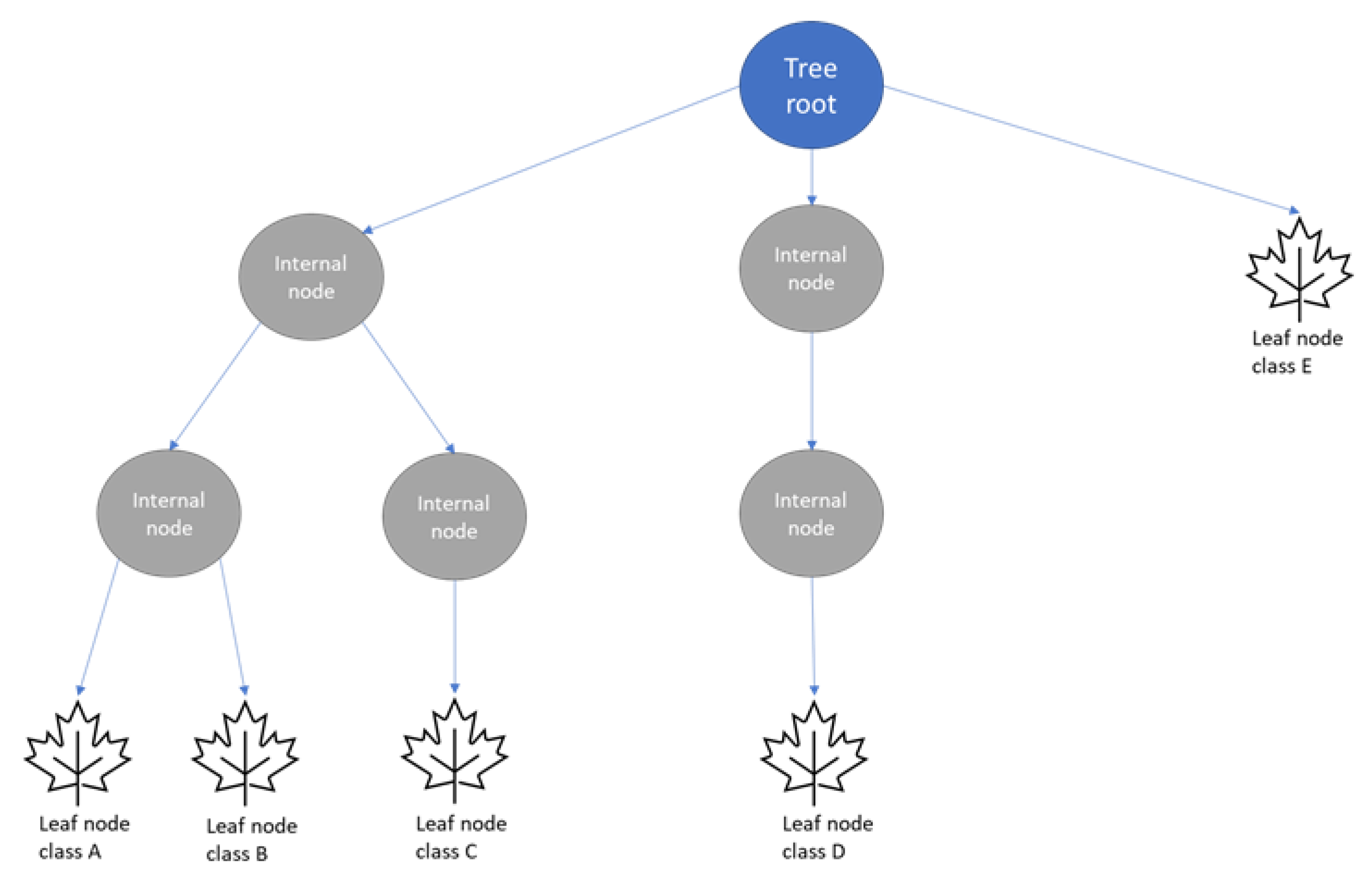
3.3. Decision Tree (DT) Classification
3.4. Random Forest
3.5. Gradient-Boosted Decision Trees
3.6. Support Vector Machines (SVMs)
3.7. Neural Networks
4. Machine Learning Applications
4.1. Medical Imaging
4.2. Diagnosis of Disease
4.3. Behavioural Modification or Treatment
4.4. Clinical Trial Research
4.5. Smart Electronic Health Records
4.6. Epidemic Outbreak Prediction
4.7. Heart Disease Prediction
4.8. Diagnostic and Prognostic Models for COVID-19
4.9. Personalized Care
5. IoT and Machine Learning Applications in Healthcare Systems to Predict Future Trends
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mtonga, K.; Kumaran, S.; Mikeka, C.; Jayavel, K.; Nsenga, J. Machine Learning-Based Patient Load Prediction and IoT Integrated Intelligent Patient Transfer Systems. Future Internet 2019, 11, 236. [Google Scholar] [CrossRef] [Green Version]
- Mosenia, A.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Wearable Medical Sensor-Based System Design: A Survey. IEEE Trans. Multi-Scale Comput. Syst. 2017, 3, 124–138. [Google Scholar] [CrossRef]
- Iqbal, N.; Jamil, F.; Ahmad, S.; Kim, D. A Novel Blockchain-Based Integrity and Reliable Veterinary Clinic Information Management System Using Predictive Analytics for Provisioning of Quality Health Services. IEEE Access 2021, 9, 8069–8098. [Google Scholar] [CrossRef]
- Wu, T.; Wu, F.; Redoute, J.-M.; Yuce, M.R. An Autonomous Wireless Body Area Network Implementation towards IoT Connected Healthcare Applications. IEEE Access 2017, 5, 11413–11422. [Google Scholar] [CrossRef]
- Birje, M.N.; Hanji, S.S. Internet of things based distributed healthcare systems: A review. J. Data Inf. Manag. 2020, 2, 149–165. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.-C. Towards a Secure Thermal-Energy Aware Routing Protocol in Wireless Body Area Network Based on Blockchain Technology. Sensors 2020, 20, 3604. [Google Scholar] [CrossRef]
- Kumar, P.M.; Gandhi, U.D. A novel three-tier Internet of Things architecture with machine learning algorithm for early detection of heart diseases. Comput. Electr. Eng. 2018, 65, 222–235. [Google Scholar] [CrossRef]
- Yuvaraj, N.; SriPreethaa, K.R. Diabetes prediction in healthcare systems using machine learning algorithms on Hadoop cluster. Clust. Comput. 2017, 22, 1–9. [Google Scholar] [CrossRef]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep learning for healthcare: Review, opportunities and challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef]
- Shahbazi, Z.; Byun, Y.-C. Improving Transactional Data System Based on an Edge Computing–Blockchain–Machine Learning Integrated Framework. Processes 2021, 9, 92. [Google Scholar] [CrossRef]
- Sohaib, O.; Lu, H.; Hussain, W. Internet of Things (IoT) in E-commerce: For people with disabilities. In Proceedings of the 2017 12th IEEE Conference on Industrial Electronics and Applications (ICIEA), Siem Reap, Cambodia, 18–20 June 2017; pp. 419–423. [Google Scholar]
- Gao, H.; Qin, X.; Barroso, R.J.D.; Hussain, W.; Xu, Y.; Yin, Y. Collaborative Learning-Based Industrial IoT API Recommendation for Software-Defined Devices: The Implicit Knowledge Discovery Perspective. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 1–11. [Google Scholar] [CrossRef]
- Rajkomar, A.; Hardt, M.; Howell, M.D.; Corrado, G.; Chin, M.H. Ensuring Fairness in Machine Learning to Advance Health Equity. Ann. Intern. Med. 2018, 169, 866–872. [Google Scholar] [CrossRef]
- Jamil, F.; Ahmad, S.; Iqbal, N.; Kim, D.-H. Towards a remote monitoring of patient vital signs based on IoT-based blockchain integrity management platforms in smart hospitals. Sensors 2020, 20, 2195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jadhav, S.; Kasar, R.; Lade, N.; Patil, M.; Kolte, S. Disease Prediction by Machine Learning from Healthcare Communities. Int. J. Sci. Res. Sci. Technol. 2019, 29–35. [Google Scholar] [CrossRef]
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable Machine Learning in Healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 24–29 August 2018; pp. 559–560. [Google Scholar]
- Panch, T.; Szolovits, P.; Atun, R. Artificial intelligence, machine learning and health systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef] [PubMed]
- Jamil, F.; Hang, L.; Kim, K.; Kim, D. A Novel Medical Blockchain Model for Drug Supply Chain Integrity Management in a Smart Hospital. Electronics 2019, 8, 505. [Google Scholar] [CrossRef] [Green Version]
- Wiens, J.; Shenoy, E.S. Machine Learning for Healthcare: On the Verge of a Major Shift in Healthcare Epidemiology. Clin. Infect. Dis. 2018, 66, 149–153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hung, C.-Y.; Chen, W.-C.; Lai, P.-T.; Lin, C.-H.; Lee, C.-C. Comparing deep neural network and other machine learning algorithms for stroke prediction in a large-scale population-based electronic medical claims database. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Jeju Island, Korea, 11–15 July 2017; pp. 3110–3113. [Google Scholar]
- Ngiam, K.Y.; Khor, W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Dike, H.U.; Zhou, Y.; Deveerasetty, K.K.; Wu, Q. Unsupervised Learning Based on Artificial Neural Network: A Review. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2018; pp. 322–327. [Google Scholar]
- Osisanwo, F.; Akinsola, J.; Awodele, O.; Hinmikaiye, J.; Olakanmi, O.; Akinjobi, J. Supervised machine learning algorithms: Classification and comparison. Int. J. Comput. Trends Technol. 2017, 48, 128–138. [Google Scholar]
- Praveena, M.; Jaiganesh, V. A Literature Review on Supervised Machine Learning Algorithms and Boosting Process. Int. J. Comput. Appl. 2017, 169, 32–35. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning (No. 10); Springer Series in Statistics: New York, NY, USA, 2001. [Google Scholar]
- Golub, G.H.; Heath, M.; Wahba, G. Generalized Cross-Validation as a Method for Choosing a Good Ridge Parameter. Technometrics 1979, 21, 215. [Google Scholar] [CrossRef]
- Tambuskar, D.; Narkhede, B.; Mahapatra, S.S. A flexible clustering approach for virtual cell formation considering real-life production factors using Kohonen self-organising map. Int. J. Ind. Syst. Eng. 2018, 28, 193–215. [Google Scholar] [CrossRef]
- Ben Ali, J.; Saidi, L.; Harrath, S.; Bechhoefer, E.; Benbouzid, M. Online automatic diagnosis of wind turbine bearings progressive degradations under real experimental conditions based on unsupervised machine learning. Appl. Acoust. 2018, 132, 167–181. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2019, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]
- Hussain, W.; Sohaib, O. Analysing Cloud QoS Prediction Approaches and Its Control Parameters: Considering Overall Accuracy and Freshness of a Dataset. IEEE Access 2019, 7, 82649–82671. [Google Scholar] [CrossRef]
- Hussain, W.; Hussain, F.K.; Hussain, O.K.; Chang, E. Provider-Based Optimized Personalized Viable SLA (OPV-SLA) Framework to Prevent SLA Violation. Comput. J. 2016, 59, 1760–1783. [Google Scholar] [CrossRef] [Green Version]
- Hussain, W.; Sohaib, O.; Naderpour, M.; Gao, H. Cloud Marginal Resource Allocation: A Decision Support Model. Mob. Netw. Appl. 2020, 25, 1418–1433. [Google Scholar] [CrossRef]
- Hussain, W.; Hussain, F.K.; Hussain, O.; Bagia, R.; Chang, E. Risk-based framework for SLA violation abatement from the cloud service provider’s perspective. Comput. J. 2018, 61, 1306–1322. [Google Scholar] [CrossRef]
- Kaur, G.; Oberoi, A. Novel Approach for Brain Tumor Detection Based on Naïve Bayes Classification. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelbarg, Germany, 2020; pp. 451–462. [Google Scholar]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? In International Workshop on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Ye, J.; Chow, J.-H.; Chen, J.; Zheng, Z. Stochastic gradient boosted distributed decision trees. In Proceedings of the 18th ACM conference on Information and knowledge management—CIKM’09, Hong Kong, China, 2–6 November 2009; pp. 2061–2064. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Bisong, E. Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Olmedo, M.T.C.; Paegelow, M.; Mas, J.-F.; Escobar, F. Geomatic Approaches for Modeling Land Change Scenarios; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Chauhan, R.; Ghanshala, K.K.; Joshi, R.C. Convolutional Neural Network (CNN) for Image Detection and Recognition. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Kolkata, India, 22–23 November 2018; pp. 278–282. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Aliberti, A.; Bagatin, A.; Acquaviva, A.; Macii, E.; Patti, E. Data Driven Patient-Specialized Neural Networks for Blood Glucose Prediction. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.-J.; Kim, N. Deep Learning in Medical Imaging. Neurospine 2019, 16, 657–668. [Google Scholar] [CrossRef]
- Desai, S.B.; Pareek, A.; Lungren, M.P. Deep learning and its role in COVID-19 medical imaging. Intell. Med. 2020, 3, 100013. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Xue, K.; Zhang, K. Current status and future trends of clinical diagnoses via image-based deep learning. Theranostics 2019, 9, 7556–7565. [Google Scholar] [CrossRef]
- Battineni, G.; Sagaro, G.G.; Chinatalapudi, N.; Amenta, F. Applications of Machine Learning Predictive Models in the Chronic Disease Diagnosis. J. Pers. Med. 2020, 10, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Michie, S.; Thomas, J.; John, S.-T.; Mac Aonghusa, P.; Shawe-Taylor, J.; Kelly, M.P.; Deleris, L.A.; Finnerty, A.N.; Marques, M.M.; Norris, E.; et al. The Human Behaviour-Change Project: Harnessing the power of artificial intelligence and machine learning for evidence synthesis and interpretation. Implement. Sci. 2017, 12, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cahyadi, A.; Razak, A.; Abdillah, H.; Junaedi, F.; Taligansing, S.Y. Machine Learning Based Behavioral Modification. Int. J. Eng. Adv. Technol. 2019, 8, 1134–1138. [Google Scholar]
- Shah, P.; Kendall, F.; Khozin, S.; Goosen, R.; Hu, J.; Laramie, J.; Ringel, M.; Schork, N. Artificial intelligence and machine learning in clinical development: A translational perspective. NPJ Digit. Med. 2019, 2, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Zame, W.R.; Bica, I.; Shen, C.; Curth, A.; Lee, H.-S.; Bailey, S.; Weatherall, J.; Wright, D.; Bretz, F.; Van Der Schaar, M. Machine learning for clinical trials in the era of COVID-19. Stat. Biopharm. Res. 2020, 12, 506–517. [Google Scholar] [CrossRef]
- Lin, W.-C.; Chen, J.S.; Chiang, M.F.; Hribar, M.R. Applications of Artificial Intelligence to Electronic Health Record Data in Ophthalmology. Transl. Vis. Sci. Technol. 2020, 9, 13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, S.; Pathak, J.; Zhang, Y. Using Electronic Health Records and Machine Learning to Predict Postpartum Depression. Stud. Health Technol. Inform. 2019, 264, 888–892. [Google Scholar]
- Solares, J.R.A.; Raimondi, F.E.D.; Zhu, Y.; Rahimian, F.; Canoy, D.; Tran, J.; Gomes, A.C.P.; Payberah, A.H.; Zottoli, M.; Nazarzadeh, M.; et al. Deep learning for electronic health records: A comparative review of multiple deep neural architectures. J. Biomed. Inform. 2020, 101, 103337. [Google Scholar] [CrossRef]
- Chae, S.; Kwon, S.; Lee, D. Predicting Infectious Disease Using Deep Learning and Big Data. Int. J. Environ. Res. Public Health 2018, 15, 1596. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, N.; Akhir, N.S.M.; Hassan, F.H. Predictive analysis effectiveness in determining the epidemic disease infected area. AIP Conf. Proc. 2017, 1891, 20064. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Zhang, J.-W.; Zang, G.-Y.; Pu, J. The primary use of artificial intelligence in cardiovascular diseases: What kind of potential role does artificial intelligence play in future medicine? J. Geriatr. Cardiol. JGC 2019, 16, 585–591. [Google Scholar]
- Almustafa, K.M. Prediction of heart disease and classifiers’ sensitivity analysis. BMC Bioinform. 2020, 21, 278. [Google Scholar] [CrossRef] [PubMed]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.J.; Dahly, D.L.; Damen, J.A.; Debray, T.P.A.; et al. Prediction models for diagnosis and prognosis of covid-19: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zoabi, Y.; Deri-Rozov, S.; Shomron, N. Machine learning-based prediction of COVID-19 diagnosis based on symptoms. NPJ Digit. Med. 2021, 4, 1–5. [Google Scholar] [CrossRef]
- Wilkinson, J.; Arnold, K.F.; Murray, E.J.; van Smeden, M.; Carr, K.; Sippy, R.; de Kamps, M.; Beam, A.; Konigorski, S.; Lippert, C.; et al. Time to reality check the promises of machine learning-powered precision medicine. Lancet Digit. Health 2020, 2, e677–e680. [Google Scholar] [CrossRef]
- Ahmed, Z.; Mohamed, K.; Zeeshan, S.; Dong, X. Artificial intelligence with multi-functional machine learning platform development for better healthcare and precision medicine. Database J. Biol. Databases Curation 2020, 2020. [Google Scholar] [CrossRef] [PubMed]
- Vanani, I.R.; Amirhosseini, M. IoT-Based Diseases Prediction and Diagnosis System for Healthcare. In Internet of Things for Healthcare Technologies; Springer: Berlin/Heidelberg, Germany, 2021; pp. 21–48. [Google Scholar]
- Wang, M.-H.; Chen, H.-K.; Hsu, M.-H.; Wang, H.-C.; Yeh, Y.-T. Cloud Computing for Infectious Disease Surveillance and Control: Development and Evaluation of a Hospital Automated Laboratory Reporting System. J. Med. Internet Res. 2018, 20, e10886. [Google Scholar] [CrossRef] [PubMed]
- Shahzad, A.; Lee, Y.S.; Lee, M.; Kim, Y.-G.; Xiong, N. Real-Time Cloud-Based Health Tracking and Monitoring System in Designed Boundary for Cardiology Patients. J. Sens. 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Mocnik, F.-B.; Raposo, P.; Feringa, W.; Kraak, M.-J.; Köbben, B. Epidemics and pandemics in maps–the case of COVID-19. J. Maps 2020, 16, 144–152. [Google Scholar] [CrossRef]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef] [PubMed]
- Shinozaki, A. Electronic Medical Records and Machine Learning in Approaches to Drug Development. In Artificial Intelligence in Oncology Drug Discovery and Development; IntechOpen: London, UK, 2020; p. 51. [Google Scholar]
- Datilo, P.M.; Ismail, Z.; Dare, J. A Review of Epidemic Forecasting Using Artificial Neural Networks. Int. J. Epidemiol. Res. 2019, 6, 132–143. [Google Scholar] [CrossRef]
- Yahaya, L.; Oye, N.D.; Garba, E.J. A Comprehensive Review on Heart Disease Prediction Using Data Mining and Machine Learning Techniques. Am. J. Artif. Intell. 2020, 4, 20. [Google Scholar] [CrossRef]
- Alharbi, R.; Almagwashi, H. The Privacy requirments for wearable IoT devices in healthcare domain. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Istanbul, Turkey, 26–28 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 18–25. [Google Scholar]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated Learning for Healthcare Informatics. J. Health Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terminology | Alternative Word |
|---|---|
| Datapoint | Input, observation, and sample |
| Label | Output, response, feature, and dependent variable |
| Learning Class | Data Type | Usage Type | Output Accuracy/ Performance | Affected by Missing Data | Scalable | Cost |
|---|---|---|---|---|---|---|
| Supervised | Labelled | Classification Regression | High | Yes | Yes, but we need to label large volumes of data automatically. | Expensive |
| Unsupervised | Unlabelled | Clustering Transformations | Low | No | Yes, but we need to verify the accuracy of the predicted output. | Inexpensive |
| Semi-Supervised | Both Labelled and unlabelled | Classification Clustering | Moderate | No | It is not recommended. | Moderately priced |
| Algorithm Name | Learning Type | Used for | Commonly Used Method | Positives | Negatives |
|---|---|---|---|---|---|
| K-Nearest Neighbor (K-NN) | Supervised | Classification, Regression | Continuous variables (Euclidean distance) Categorical variables (Hamming distance) | Nonparametric approach. Intuitive to understand. Easy to implement. Does not require explicit training. Can be easily adapted to changes simply by updating its set of labelled observations. | Takes a long time to calculate the similarity between the datasets. The performance is degraded because of imbalanced datasets. The performance is sensitive to the choice of hyperparameter (K value). The information might be lost, so we need to use homogeneous features. |
| Naïve Bayes (NB) | Supervised | Probabilistic classification | Continuous variables (Maximum likelihood) | Scanning of data by looking at each feature individually. Collecting simple per-class statistics from each feature helps with increasing the assumptions’ accuracy. | Requires only a small amount of training data. Determines only the variances of the variables for each class. |
| Decision Trees (DTs) | Supervised | Prediction, Classification | Continuous Target Variable (Reduction in Variance) Categorical Target Variable (Gini Impurity) | Easy to implement. Can handle categorical and continuous attributes. Requires little to no data preprocessing. | Sensitive to the imbalanced dataset and noise in the training dataset. Expensive, and needs more memory. Must select the depth of the node carefully to avoid variance and bias. |
| Random Forest | Supervised | Classification, Regression | Bagging | Lower correlations across the decision trees. Improves the DT’s performance. | Does not work well on high-dimensional, sparse data. |
| Gradient Boosted Decision Trees | Supervised | Classification, Regression | Strong prepruning | Improves the prediction performance iteratively. | Requires careful tuning of the parameters and may take a long time to train. Does not work well on high-dimensional, sparse data. |
| Support Vector Machine (SVM) | Supervised | Binary classification, Nonlinear classification | Decision boundary, Soft margin, Kernel trick | More effective in high-dimensional space. Using the kernel trick is the real strength of SVM. | Selecting the best hyperplane and kernel trick is not easy. |
| Reference | Application Name | Brief Description | ML Algorithms | Issues Addressed | Current Challenges | Future Work | Comparison with Existing Reviews |
|---|---|---|---|---|---|---|---|
| [45] | Medical imaging | Medical imaging is largely manual today as it entails a health professional examining images to determine abnormalities. However, machine learning algorithms can be used to automate this process and enhance the accuracy of the imaging process. | Artificial neural networks (ANNs) and convolutional neural networks (CNNs) | The use of machine learning addresses the issues of accuracy and efficiency when imaging is done manually. | High dependency on the quality and amount of training sets. Ethical and legal issues concerning the use of ML in healthcare. It is often difficult to explain the outputs of deep learning techniques logically. | Improving the quality of training datasets to improve accuracy and patient-centredness. | Existing reviews on medical imaging, such as [68], published in 2019, focus on providing a broad overview of the advances being made in this area of ML. The proposed review intends to offer an updated assessment of medical imaging ML algorithms and their application. |
| [47] | Diagnosis of diseases | Clinical diagnosis can benefit from machine learning by improving the quality and efficiency of decision-making. | Image-based deep learning | Wrong patient diagnoses result in inappropriate interventions and adverse outcomes. | The lack of sound laws and regulations defining the utilization of ML in healthcare. Obtaining well-annotated data forsupervised learning is challenging. | Integrating ML into electronic medical records to support timely and accurate disease diagnoses. | Reviews on clinical diagnoses tend to focus on a specific disease type or group. For example, Schaefer et al. (2020) focused on rare diseases [52]. The proposed review hopes to continue in this vein but add on an in-depth examination of the application of these ML algorithms in practical environments and the potential benefits. |
| [49] | Behaviour modification or treatment | The integration of machine learning into behavioural change programs can help with determining what works and what does not. | Various machine learning and reasoning methods, including natural language processing | The inability to synthesize and deliver evidence on behavioural change interventions to user need and context to improve the usefulness of evidence. | The lack of a behavioural change intervention knowledge system consisting of an ontology, process, and resources for annotating reports, an automated annotator, ML and reasoning algorithms, and user interface. | The utilization of evidence from machine learning programs to guide behavioural change interventions. | Based on the researcher’s exploration, there are no reviews systematically examining behavioural modification or treatment machine learning algorithms. Accordingly, these applications of ML ought to be assessed. |
| [51] | Clinical trial research | There is a need to develop machine learning algorithms capable for continual learning from clinical data. | Deep learning techniques | The difficulty of drawing insights from vast amounts of clinical data using human capabilities. | The problem of utilizing deep learning models on complex medical datasets. The need for high volumes of well-labelled training datasets. Ethical issues surrounding machine learning. | The continued collection of training datasets to improve the applicability of deep learning in clinical research trials. | Some review studies in this area exist. For example, Zame et al. (2020) reviewed the application of ML in clinical trials in the current COVID-19 setting [52]. The proposed research will examine ML applications in different clinical trial efforts. |
| [53] | Smart electronic health records | The inclusion of machine learning in electronic health records creates smart systems with the capability to perform disease diagnosis, progression prediction, and risk assessment. | Deep learning, natural language processing, and supervised machine learning | Current electronic health records store clinical data but do not support clinical decision-making. | Preparing data before they are fed into a machine learning algorithm remains a challenging task. Additionally, it is difficult to incorporate patient-specific factors in machine learning models. | The widespread adoption of smart electronic health records to support the management of different conditions or diseases. | Reviews assessing the incorporation of ML into electronic health records are few. Shinozaki (2020) reviewed the inclusion of ML in electronic health records to aid drug development [69]. However, additional research is required to determine whether ML can help further patient-centred care, improve the quality of care, and enhance efficiency. The proposed review hopes to address these components. |
| [56] | Epidemic outbreak prediction | Disease surveillance can benefit from machine learning as it allows for the prediction of epidemics, hence enabling the implementation of appropriate safeguards. | Deep neural network (DNN), long short-term memory (LSTM) learning, and the autoregressive integrated moving average (ARIMA) | The difficulty of preparing for and dealing with infectious diseases due to a lack of knowledge or forecasts. | The low accuracy of predictive models. The challenge of choosing parameters to utilize with the machine learning models. | The use of predictive models to forecast a range of infectious diseases. | There have been studies reviewing the application of ML to disease outbreak prediction. Philemon et al. (2019) reviewed the utilization of ANN to predict outbreaks [70]. The proposed review intends to further the review efforts and examine ways of enhancing the predictive accuracy of the ML algorithms created. |
| [58] | Heart disease prediction | AI can be utilized to predict heart disease, hence enabling patients and health providers to implement preventive measures. | Deep learning and artificial neural networks | There is a need for accurate prediction of cardiovascular diseases, as well as the implementation of effective treatments to improve patient outcomes. | The lack of ethical guidelines to direct the adoption of heart disease prediction algorithms. Machine learning algorithms cannot solve highly abstract reasoning problems. | Extending the utilization of ML in clinical decision-making to include patient-centred predictive analytics. | In this area, current and comprehensive reviews have been performed [71]. Therefore, the objective of the planned review is to report the findings and suggest areas of further research. |
| [60] | Diagnostic and prognostic models for COVID-19 | This study examined the prediction models for COVID-19 and found that they are poorly designed. | Deep learning models | The need to review prediction models for the diagnosis and prognosis of COVID-19 to support their use to guide decision-making. | The developed models are problematic due to the poor training datasets used. | Collect high-volume and quality datasets to train COVID-19 prediction models. | Systematic reviews assessing the application of ML for COVID-19 diagnosis and prognosis have been conducted [60]. As knowledge of the disease continues to improve, better and more effective models can emerge, hence the need for continual reviews. |
| [63] | Personalized care | Machine learning algorithms provide an avenue for offering person-centred care. | Deep neural networks, deep learning, supervised and unsupervised learning, and many others | The inability to provide personalized care despite the increasing accumulation of personal data. | There is a need for the continued accumulation of high-quality training datasets. | Creating systems that can be integrated into electronic health records to promote personalized medicine. | Fröhlich et al. (2018) reviewed the application of ML to enable personalized care. The study identified some of the challenges associated with this endeavor. As such, the proposed review hopes to explore how subsequent studies have addressed these challenges. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldahiri, A.; Alrashed, B.; Hussain, W. Trends in Using IoT with Machine Learning in Health Prediction System. Forecasting 2021, 3, 181-206. https://doi.org/10.3390/forecast3010012
Aldahiri A, Alrashed B, Hussain W. Trends in Using IoT with Machine Learning in Health Prediction System. Forecasting. 2021; 3(1):181-206. https://doi.org/10.3390/forecast3010012
Chicago/Turabian StyleAldahiri, Amani, Bashair Alrashed, and Walayat Hussain. 2021. "Trends in Using IoT with Machine Learning in Health Prediction System" Forecasting 3, no. 1: 181-206. https://doi.org/10.3390/forecast3010012