

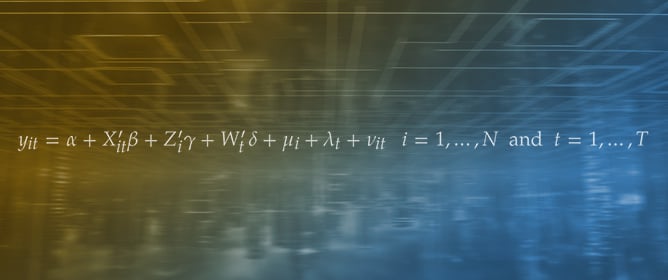
Econometrics 2024, 12(4), 27; https://doi.org/10.3390/econometrics12040027 - 26 Sep 2024
Abstract
This paper proposes an estimator for the endogenous switching regression models with fixed effects. The decision to switch from one regime to the other may depend on unobserved factors, which would cause the state, such as being credit constrained, to be endogenous. Our
[...] Read more.
This paper proposes an estimator for the endogenous switching regression models with fixed effects. The decision to switch from one regime to the other may depend on unobserved factors, which would cause the state, such as being credit constrained, to be endogenous. Our estimator allows for this endogenous selection and for conditional heteroscedasticity in the outcome equation. Applying our estimator to a dataset on the productivity in agriculture substantially changes the conclusions compared to earlier analysis of the same dataset. Intuitively, the reason that our estimate of the impact of switching between states is smaller than previously estimated is that we captured the selection issue: switching between being credit constrained and credit unconstrained may be endogenous to farm production. In particular, we find that being credit constant has the substantial effect of reducing yield by 11%, but not the previously estimated very dramatic effect of reducing yield by 26%.
Full article

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}