

Stats 2024, 7(3), 1066-1083; https://doi.org/10.3390/stats7030063 - 23 Sep 2024
Abstract
Heart failure is a major global health concern, especially in Ethiopia. Numerous studies have analyzed heart failure data to inform decision-making, but these often struggle with limitations to accurately capture death dynamics and account for within-cluster dependence and heterogeneity. Addressing these limitations, this
[...] Read more.
Heart failure is a major global health concern, especially in Ethiopia. Numerous studies have analyzed heart failure data to inform decision-making, but these often struggle with limitations to accurately capture death dynamics and account for within-cluster dependence and heterogeneity. Addressing these limitations, this study aims to incorporate dependence and analyze heart failure data to estimate survival time and identify risk factors affecting patient survival. The data, obtained from 497 patients at Jimma University Medical Center in Ethiopia were collected between July 2015 and January 2019. Residence was considered as the clustering factor in the analysis. We employed the Bayesian accelerated failure time (AFT), and Bayesian AFT shared gamma frailty models, comparing their performance using the Deviance Information Criterion (DIC) and Watanabe–Akaike Information Criterion (WAIC). The Bayesian log-normal AFT shared gamma frailty model had the lowest DIC and WAIC, with well-capturing cluster dependency that was attributed to unobserved heterogeneity between patient residences. Unlike other methods that use Markov-Chain Monte-Carlo (MCMC), we applied the Integrated Nested Laplace Approximation (INLA) to reduce computational load. The study found that 39.44% of patients died, while 60.56% were censored, with a median survival time of 34 months. Another interesting finding of this study is that adding frailty into the Bayesian AFT models boosted the performance in fitting the heart failure dataset. Significant factors reducing survival time included age, chronic kidney disease, heart failure history, diabetes, heart failure etiology, hypertension, anemia, smoking, and heart failure stage.
Full article
(This article belongs to the Section Survival Analysis)
►
Show Figures

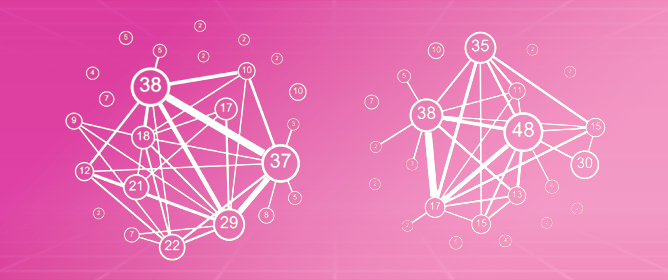
Figure 1




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}