

Abstract
Aiming at the problem of insignificant target morphological features, inaccurate detection and unclear boundary of small-target regions, and multitarget boundary overlap in multitarget complex image segmentation, combining the image segmentation mechanism of generative adversarial network with the feature enhancement method of nonlocal attention, a generative adversarial network fused with attention mechanism (AM-GAN) is proposed. The generative network in the model is composed of residual network and nonlocal attention module, which use the feature extraction and multiscale fusion mechanism of residual network, as well as feature enhancement and global information fusion ability of nonlocal spatial-channel dual attention to enhance the target features in the detection area and improve the continuity and clarity of the segmentation boundary. The adversarial network is composed of fully convolutional networks, which penalizes the loss of information in small-target regions by judging the authenticity of prediction and label segmentation and improves the detection ability of the generative adversarial model for small targets and the accuracy of multitarget segmentation. AM-GAN can use the GAN's inherent mechanism that reconstruct and repair high-resolution image, as well as the ability of nonlocal attention global receptive field to strengthen detail features, automatically learn to focus on target structures of different shapes and sizes, highlight salient features useful for specific tasks, reduce the loss of image detail features, improve the accuracy of small-target detection, and optimize the segmentation boundary of multitargets. Taking medical MRI abdominal image segmentation as a verification experiment, multitargets such as liver, left/right kidney, and spleen are selected for segmentation and abnormal tissue detection. In the case of small and unbalanced sample datasets, the class pixels' accuracy reaches 87.37%, the intersection over union is 92.42%, and the average Dice coefficient is 93%. Compared with other methods in the experiment, the segmentation precision and accuracy are greatly improved. It shows that the proposed method has good applicability for solving typical multitarget image segmentation problems such as small-target feature detection, boundary overlap, and offset deformation.
1. Introduction
Image multitarget segmentation is one of the hotspots in the field of image processing and artificial intelligence. Essentially, it can be expressed as pixel classification of multitarget with semantic labels, that is, segmenting and describing multitarget of interest in the image by using a set of object categories to classify and mark images at the pixel level [1, 2]. With the continuous development of image analysis theory and deep learning technology, researchers have proposed many effective multitarget image segmentation models and algorithms [3–5]. However, in some complex scenes, the image is affected by noise, offset deformation, gray value distortion, local position effect, and other factors, so the existing methods still have problems such as target omission, position offset, unclear boundary, and so on [6, 7]. At the same time, some image segmentation methods have good results for single-target segmentation, but still not applicable to the complex multitarget image segmentation. Especially, in multi-instance, the accurate detection and segmentation accuracy of small-size targets are difficult to guarantee [8, 9]. There are still challenges in the research of image multitarget detection and segmentation.
At present, image segmentation can be divided into two categories: traditional methods and deep learning methods. Traditional image segmentation algorithms mostly use gray-scale features to segment images [10]. Typical methods include threshold-based method [11], edge-based method [12], and region-based method [13]. However, there are problems such as susceptibility to the contrast of image gray features, poor segmentation of low-resolution and blurred images, and prone to oversegmentation of images. In general, traditional image segmentation methods are greatly affected by subjective factors, and the preprocessing process is complicated. For example, strong prior knowledge is needed to solve the problems such as the selection of seed points during segmentation and the selection of the threshold of the segmentation boundary. At the same time, small errors in the selection of key parameters have a greater impact on segmentation accuracy. These problems make traditional image segmentation algorithms still have many restrictions when applied to image semantic segmentation.
Deep convolutional network is an effective image feature extraction and analysis method, which has been widely used in image classification, image generative, and target detection. Many excellent algorithms have emerged, such as AlexNet [14], ResNet [15], Faster R-CNN [16], and so on. Although deep convolutional networks have powerful feature extraction capabilities, they still have many limitations when applied to image segmentation problems. Take multitarget segmentation of medical images as an example. Medical images intuitively reflect the 2D and 3D morphological characteristics of organs and tissues in specific areas of the human body. The human body has a relatively complex organ and tissue structure, and the anatomical structure of different human bodies is also different among individuals. At the same time, it is easy to be affected by factors such as noise, illumination, and local posture effect, and the image shape and various organ tissue regions are soft boundaries, showing regular or irregular dynamic periodicity with cardiac contraction or relaxation. These factors increase the difficulty of medical image feature differentiation, target detection, and segmentation [17, 18]. Moreover, the pooling layer in the convolutional neural network (CNN) will downsample the input image size and reduce the resolution of the image; the fully connected layer will turn the image features into vectors, destroying the spatial information of the image. Therefore, it still has inadequacy in solving the problem of complex image segmentation. Although these convolution-based methods have achieved certain segmentation results, they ignore the spatial correlation of medical images such as CT and MRI, which is easy to produce nonsmooth and discontinuous segmentation results [19].
In order to solve the limitations of the structure and information processing mechanism of traditional convolutional neural networks in image segmentation problems, Long et al. [20] proposed the fully convolutional network (FCN) model. FCN abandons the fully connected layer of CNN and replaces it with the fully convolution structure. At the same time, it uses the deconvolution operator to restore the image size and introduces a shortcut-connection structure to fuse the high-level characteristics of the network with the low-level features to optimize the segmentation results. At present, most of the deep learning models used in image segmentation are based on the idea of the FCN model. Ronneberger et al. [21] proposed the U-Net model, which retains the convolution and deconvolution structure of the FCN model, but changes the way of fusion of high-level feature map and low-level feature map. The encoding part and the decoding part of U-Net are completely symmetrical, and the connection is realized through channel splicing and then convolution. At present, there are many variants of U-Net models, such as 3D U-Net [22], Res U-Net [23], Dens U-Net [24], and Attention U-Net [25]. In addition, the SegNet model proposed by Badrinarayanan et al. [26] replaces the deconvolution of FCN with an up-pooling method, which makes the upsampling part no longer participate in training while ensuring the segmentation accuracy, reducing the computational complexity. The above methods and mechanisms effectively solve the principle and strategy problems of image segmentation, but in complex image segmentation with noise and content diversity, there are still problems of unstable segmentation effect on low-resolution and fuzzy images and low accuracy of target pixel classification [27].
In the research of low-resolution image high-definition processing, Zhang et al. [28] (2021) build a hierarchical correlation filters model based on the multilevel convolutional features, which can suppress interference of background and similar objects. Chen et al. [29] (2021) proposed an image super-resolution reconstruction method using attention mechanism with the feature map. It uses the information extraction block of feature map attention mechanism to adaptively adjust the channel characteristics, enhance the feature expression ability, and facilitate reconstruction from original low-resolution images to multiscale super-resolution images. For the image inpainting, Chen et al. [30] (2021) proposed a novel image embedding algorithm based on encoder and similarity constraint, which effectively solved the problem of joint context awareness loss in image inpainting and improved the utilization of features. The above works provide good support for fine segmentation of complex images. However, the proposed method will still be affected by obvious blur, and the training time required will also be longer. Then, Chen et al. [31] (2021) proposed image completion algorithm based on the improved total variation minimization method, which can solve the issue mismatching and structure disconnecting in exemplar-based image inpainting.
The generative adversarial network (GAN) proposed by Goodfellow et al. (2014) [32] is a deep learning method based on Nash equilibrium in game theory, including two parts: generator and discriminator. The generator in the GAN model, that is, the generator network model, is mainly used to generate target data. The typical generator structure is a neural network based on deconvolution, which restores the input image size through multiple deconvolution layers' upsampling and finally obtains generated image data. In image segmentation, the generator is essentially a segmentation model. For example, FCN [20], U-Net [21], and SegNet [26] can be selected as the generative network, which receives the input of the original image and takes the predictive segmentation as the output. The discriminator, that is, the adversarial network in GAN, usually uses CNNs as the basic model. Its inputs include the real data and the generator's generated data. The generated data are judged as false, and the real data are judged as true. Through the authenticity judgment, the game learning is performed to optimize the generator's ability to generate data. In mechanism, GAN can reconstruct low-resolution images into super-resolution high-definition images [33] and train the generative model based on the surrounding pixels of the missing part of the image to repair the complete image [34]. If applied to the image segmentation problems in the case of blur, offset, and small target, it can effectively improve the quality and accuracy of image segmentation. Attention mechanism is a target feature enhancement method that is widely studied and applied at present. It can be used as a module of the deep learning model to focus attention on objects of interest [35, 36]. However, most of the existing methods mainly focus on the local pixels of the target area and have low relevance to the image content with a large receptive field [37]. In order to capture the dependence of spatial long-distance information in the image, Wang et al. [38] proposed a nonlocal attention mechanism, the strategy of which is that the characteristic response value at a pixel is equal to the weighted average of the characteristic values at all receptive field points, that is, all points in the larger receptive field are connected to realize global information fusion. The nonlocal attention mechanism connects the understanding of global content with the semantics of local targets, which improves the enlightenment and restriction of target pixel classification. In complex image multiobject segmentation, if the image segmentation mechanism of GAN is combined with nonlocal attention feature enhancement method, it can effectively improve the accuracy of complex image multiobject segmentation and optimize segmentation boundary in mechanism.
Aiming at the poor accuracy of multitarget instance segmentation and small-scale target segmentation in complex images, a generative adversarial network fused with nonlocal attention mechanism is proposed in this paper. The generative network module of the GAN uses the residual network as the basic model for preliminary target segmentation. The nonlocal spatial-channel dual-attention mechanism is added to the output feature map of the residual network to capture the long-distance dependence information of each feature point on the output feature map. The adversarial network module is constructed based on CNNs, which performs masking operations on the original image with prediction segmentation and label segmentation, respectively, and inputs the masking result into the adversarial network. The adversarial network judges the mask result of the predicted segmentation as false, and the mask result of the label segmentation is judged as true. And the generative network judges the mask result of the predicted segmentation as true. Through the game learning between the generative network and the adversarial network, the image segmentation ability of the generative network is optimized. Specifically, firstly, a generative network module is constructed based on residual network and nonlocal attention mechanism for preliminary image segmentation. On this basis, masking operations on the original image with the prediction and label segmentation, respectively, are performed, and the results are input to the adversarial network to optimize the segmentation results. AM-GAN strengthens the extraction and fusion of multiscale features, as well as the distinguishing ability of each instance boundary pixels, to achieve the fine segmentation of multitarget instance regions in complex image and improve the accuracy of small-target segmentation.
Medical images are often blurred due to the influence of the imaging environment and detecting equipment. Meanwhile, the complexity of human organ and tissue structure, the differences of different individual anatomical structures, and the influence of local posture effect also increase the difficulty of medical image feature differentiation and segmentation. In this paper, taking the segmentation of abdominal MRI images as a verification experiment, multitarget tissues such as liver, left/right kidney, and spleen are selected for segmentation and abnormal detection to verify the effectiveness of the model and algorithm.
In this paper, the problems in image segmentation, such as insignificant morphological characteristics of the target image, easy to be affected by noise, gray value distortion and local position effect, and unclear boundary of the target region, are studied. The main motivation is to establish a novel image segmentation model, which can improve the accuracy of complex image fine segmentation in mechanism.
The novelty and main contributions of this paper are as follows:
A novel generative adversarial network fused with the attention mechanism (AM-GAN) multitarget image segmentation model is proposed. In mechanism, the image segmentation mechanism of GAN is organically combined with the feature enhancement method of nonlocal attention so that the model and algorithm can automatically learn to focus on the target structure with different shapes and sizes, highlighting the feature usefulness for specific tasks. It can effectively improve the problems of existing image segmentation methods, such as insufficient utilization of correlation information between image voxels, imprecise detection of small-target area, unclear boundary, and overlapping multitarget boundary, and effectively improve the accuracy of complex image multitarget segmentation.
The generative module of AM-GAN combines the feature enhancement of nonlocal attention with the feature fusion method of the residual network. In the generative network, the understanding of the global content is linked with the semantics of the local target, and the low-level and high-level feature maps are added through the shortcut-connection structure to achieve feature fusion. In mechanism, it can give play to the guidance and heuristics of target segmentation and refine the segmentation results.
In this paper, AM-GAN is proposed as the image multitarget segmentation model. In mechanism, it can use GAN's high-definition processing and repair capabilities to reduce the effects of noise, bias deformation, and gray value distortion. Through the information association and restriction of the nonlocal attention large receptive field to the local target, the continuity of target segmentation is maintained. Meanwhile, the Nash game strategy between generative network and adversarial network is adopted in AM-GAN algorithm to optimize the segmentation results and improve the continuity, smoothness, and accuracy of multitarget segmentation results.
In Section 1, the current challenges and current research status of the complex image multitarget segmentation are reviewed and analyzed. The ideas and algorithm strategies of a novel AM-GAN segmentation model established in this paper are pointed out. In Section 2, the AM-GAN model is established and its theoretical properties are analyzed. In Section 3, the comprehensive learning algorithm of AM-GAN is designed and proposed. In Section 4, multitarget segmentation experiments and result analysis are conducted based on medical images. Finally, the work of the paper is summarized, and the advantages and limitations are pointed out.
2. The Generative Adversarial Network Fused with the Dual-Attention Mechanism Segmentation Model
2.1. The Generative Adversarial Network Basic Model
The generative adversarial network (GAN) basic model in this paper includes two parts: generator and discriminator. The basic structure and information processing flow are shown in Figure 1.
Figure 1.

The generative adversarial network.
In Figure 1, the generative network module in GAN is mainly used to generate target data. The typical generative network generally is usually the neural network based on deconvolution, such as FCN, U-Net, and SegNet, which recovers to the size of the input image through sampling on multiple deconvolution layers and finally obtains the generated image data. For image segmentation, the generative network is used as an image segmentation model, which receives the input of the original image and takes the predictive segmentation as the output. The adversarial network in GAN usually adopts convolutional neural networks. Its input includes real data and generated data from the generator. Through authenticity judgment and game learning with the generator, the ability of the generator to generate data is optimized.
The gray value of the input image to generative network is recorded as the random variable x, the distribution it obeys is set to P(x), and the noise data z obeys the uniform distribution. The generator maps the noise data z to G(z), and the authenticity discrimination probability of the image random variable x is D(x).
In learning, GAN is optimized according to the principle that the generative model maximizes log D(x) and the discrimination model minimizes log(1 − D(G(z))). The objective function is defined as follows:
| (1) |
2.2. Nonlocal Attention Mechanism
The core idea of nonlocal attention mechanism is that the characteristic response value at a pixel is equal to the weighted average of the characteristic values at all points, that is, all points in the receptive field are connected, and the dependency relationship between pixels based on spatial distance is established to realize global information fusion. The calculation formula [38] is
| (2) |
where i represents the output position index, j represents any position of the input, x represents the input, y represents the output with the same size as x, f(·) is the similarity measurement function between pixels, g(·) represents the feature mapping of j, and C(x) is the normalization factor. (f) and g can be implemented in many ways. If g is a Gaussian function, its expression is
| (3) |
| (4) |
The operation in equation (3) represents the difference amplified exponentially after multiplying the two vector matrices, and equation (4) is the mathematical expression of the normalization function C(x).
Consider an extended form of equation (3). Firstly, the vector x is embedded into spatial mapping, that is, the two vectors are mapped to different feature spaces, and then, the Gaussian function is used to measure the similarity. The specific form is
| (5) |
The vector dot product of function f can be expressed as
| (6) |
Now, the normalization function C(x) is equal to N, and N is the number of positions of x.
Based on the paired function form in the relational network proposed by Santoro et al. [39], the function f can be expressed as a cascaded form:
| (7) |
where [,] represents cascade and wfT represents the weight vector that projects the cascade vector to the scalar.
The nonlocal attention mechanism is integrated into convolutional neural network to form a general nonlocal block. The module can be integrated into any neural network structure. The definition of nonlocal block is as follows:
| (8) |
where z is the output of the attention module, y is the output of equation (2), wz is the weight matrix of the number of restored input channels, and x is the input.
The structure of nonlocal block is shown in Figure 2.
Figure 2.

The structure of nonlocal block.
In Figure 2, the nonlocal block first performs feature mapping on the input matrix I(C × H × W) with a 1 × 1 convolution, that is, the mapping operation of the functions g, θ, and φ in (3) and (5), to get matrices wr, wk, and wv. Then, the matrix wk is deformed and transposed into a matrix Fk(HW × T), and wr is transformed into a matrix Fr(T × HW). Fk is multiplied by Fr and then normalized by Softmax to obtain the similarity measure matrix F(HW × HW). Then, multiply the deformed matrix Fv(T × HW) from wv and the matrix F to obtain the characteristic response matrix Fs(T × HW). Finally, Fs is deformed and multiplied by the convolution kernel wz to restore the original number of channels. The operation result is added to the input matrix I(C × H × W) to obtain the output O(C × H × W), and the final output feature map is a feature map with enhanced global information dependence.
2.3. Residual Generation Network Based on Dual-Attention Mechanism
In the complex images' multitarget segmentation, if the number of image instance targets is large and the difference of individual gray value is small, the neural network needs to have strong ability of feature extraction, fusion, and recognition. In this paper, the residual network is used as the main body of the image segmentation model, and the shortcut-connection structure is added between different convolution layers, that is, the input of the upper network is directly superimposed with the output of the lower network at the element level, so as to reduce the loss of feature information and realize feature fusion of different levels. In this way, the network can still maintain good convergence properties in the deep case. The residual structure is shown in Figure 3.
Figure 3.
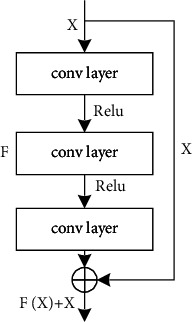
Residual structure.
At present, there are many classical residual network models, such as ResNet18, ResNet34, and ResNet50 [16]. In practice, the selection of the model is mainly based on the requirements of input image size, quality, and segmentation accuracy. Generally, the deeper the network, the stronger the feature extraction ability. In this paper, ResNet50 is selected as the basic model according to the problem of small-target region detection in complex image multitarget segmentation. The structure of segmentation model based on ResNet50 is shown in Figure 4.
Figure 4.

The segmentation model based on residual network.
In Figure 4, the segmentation model is divided into six parts. (1) 7 × 7 convolution with step size of 2 and the number of output image channels is 64. (2) The pooling operation with step size of 2 and the 3 × 3 sliding window cascades three residual blocks. Each residual block contains three convolution layers. The first and third are 1 × 1 convolution to adjust the number of channels of the feature maps. The second is 3 × 3 convolution with a step size of 1. Equations (3) to (5) are stacked residual blocks. The last one includes average pooling with a step size of 1 and 7 × 7 sliding window, as well as fully connection and Softmax classification. Extract the output from the second to the fifth part of the model, and then, upsample the four output feature maps for prediction segmentation.
In practice, only relying on the residual network to perform image multitarget segmentation will result in the blurring of the segmentation boundary and the loss of small-target information, that is, the residual network cannot make full use of the image feature information to segment the image. In this paper, based on the residual network, a nonlocal attention mechanism is introduced to construct a dual-attention mechanism model that can integrate spatial and channel attention. The structure is shown in Figure 5.
Figure 5.
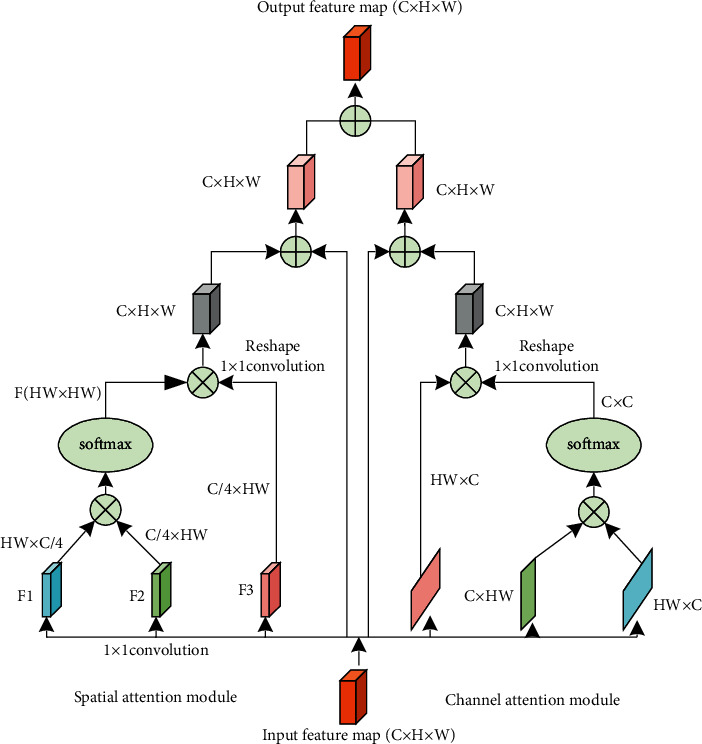
Dual-attention mechanism.
In Figure 5, the spatial-attention module is used on a nonlocal mechanism to strengthen the dependency between all pixels on the feature maps, which is represented by a similar weight matrix. In this module, the output feature map of the residual network first undergoes 1 × 1 convolution to obtain three feature maps F1, F2, and F3, which have the same width and height as the input image, but the number of channels is reduced to 1/4 of the original. On this basis, F1 is transposed and multiplied by F2 and then processed by Softmax normalization to obtain the interpixel similarity matrix F(HW × HW). F is multiplied by F3, and the original input is added to obtain the feature map after spatial feature optimization.
The channel-attention mechanism is used to capture the interdependence between any two channels and update the value in one channel by using the weighted average of all channels. Its implementation steps are similar to the spatial-attention module. The feature maps obtained by the spatial-attention module and the channel-attention module are added and fused to generate a segmented image strengthened by the attention mechanism.
In Figure 5, the mathematical expression of Softmax is
| (9) |
where zil represents the ith pixel value in the lth column of the feature map F. This formula normalizes the similarity measure matrix F by column so that the weight value of each column is within the interval [0,1].
The nonlocal attention mechanism is combined with the residual network model to construct the generator module in the GAN. The structure is shown in Figure 6.
Figure 6.
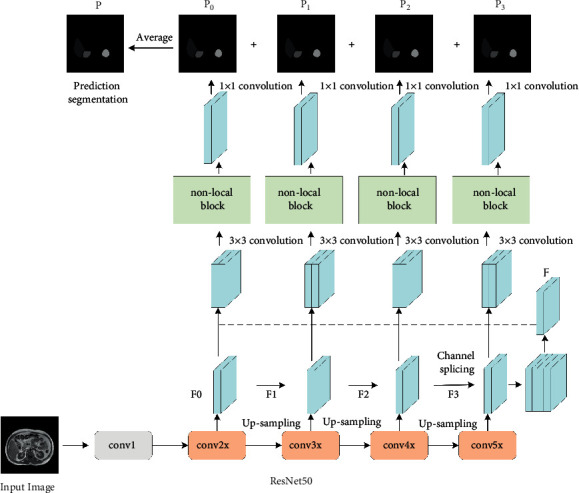
The generate network model.
In Figure 6, the generator module receives image data input, and the input image is extracted features by the ResNet50 network based on the dual-attention mechanism; four output feature maps at different levels are obtained, denoted as F0, F1, F2, and F3. The F1, F2, and F3 feature maps are upsampled to the same size as F0, and then, the four output feature map channels are spliced and 3 × 3 convolution is performed to obtain the fused feature map F. The fusion feature map F is spliced with F0, F1, F2, and F3 at channel level, respectively, and then, input into the self-attention mechanism module after 3 × 3 convolution to obtain four prediction segmentation maps. They are added and fused and averaged, and finally, the image multitarget prediction segmentation map is obtained.
2.4. The Adversarial Network Model Based on Convolutional Network
In GAN, the adversarial network module penalizes the lost details and small-size target information of the network through game learning, which makes the multitarget images segmented by the generative network more accurate. In this paper, the adversarial network module in GAN is constructed based on CNN, and its structure is shown in Figure 7.
Figure 7.
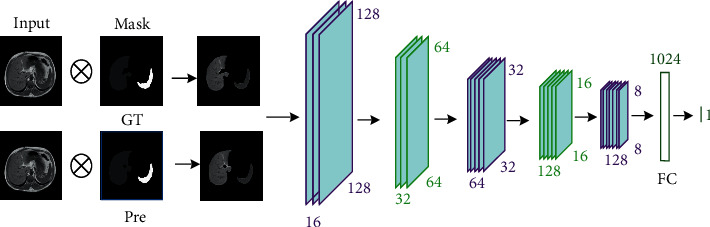
The adversarial network model.
In Figure 7, the adversarial network model includes two inputs: one is dot-product image of segmentation label and the original image, and the other is dot-product image of generative network and the original image. Dot-product operation is a mask operation on the original image to obtain the area of label and prediction segmentation on the original image. The adversarial network performs feature extraction on the obtained detection area, distinguishes whether the input is a real or predicted segmentation area, and optimizes the segmentation result through the adversarial learning with the generative network. In this paper, the CNN in the adversarial network model contains a total of 5 convolutional layers, 5 pooling layers, and two fully connected layers. The size of the convolution kernel is 3 × 3, and the step size is 1 × 1, that is, the convolution operation does not change the size of the input. The pooling layer is the maximum pooling with a size of 2 × 2, and the step size is 2 × 2, which reduces the input resolution by half. The ReLu function is selected as the activation function, and the Sigmoid function is used for classification operations.
2.5. The Generative Adversarial Network-Fused Attention Mechanism
In this paper, a generative adversarial network segmentation model fused with attention mechanism (AM-GAN) is proposed and the overall structure is shown in Figure 8.
Figure 8.

The overall structure of the generative adversarial network segmentation model.
In Figure 8, the gold standard is an accurate result of manual segmentation by experts. In AM-GAN, the generative network is composed of the ResNet50 model and the nonlocal dual-attention mechanism module. It takes the original image as input and the predicted segmentation as output. The adversarial network is composed of CNNs. Its inputs include the mask of the predicted segmentation and the original image and the mask of the gold standard and the original image. The mask of the predicted segmentation is judged as false (marked as 0), and the mask of the gold standard is judged to be true (marked as 1).
Combining the generative network based on the residual network and the nonlocal dual-attention mechanism with the adversarial network based on the CNNs to build a generative adversarial network model for the multitarget image segmentation. After AM-GAN is trained to reach the optimum, the model used for image segmentation is a generator network. The structure of the AM-GAN segmentation model is shown in Figure 9.
Figure 9.

The generative adversarial network segmentation model fused with attention mechanism.
As shown in Figure 9, in the generator network, the conv2x, conv3x, conv4x, and conv5x parts of the ResNet50 based on the dual-attention mechanism all have a prediction segmentation output, and the final prediction segmentation of the generator network is the average value of the prediction segmentation of these four parts. The input of the generator is subjected to feature extraction through the extended ResNet50 network, and the rough feature map is obtained by upsampling. The calculation formula of the upsampling output F1 of the conv3x part in the extended ResNet50 network is
| (10) |
where I represents the input image, conv3x(I) represents the convolution output of the conv3x part, w1 represents the 1 × 1 convolution, whose purpose is to reduce the number of channels of the convolution output, b1 represents the bias, BN(·) represents the batch normalization, Relu(·) is the activation function, and Umsample(·) is the interpolation upsampling. In this paper, the bilinear interpolation algorithm is used to upsample the feature map, and the output is F1. Using the same algorithm, the upsampled output F2 and F3 of the conv4x and conv5x parts can be obtained. The output F0 of the conv2x part does not need to be upsampled, and the sizes of F1, F2, and F3 are the same as F0. After feature extraction and upsampling of the input image, the output information of each part is fused. The calculation formula of the fusion feature map F is
| (11) |
where cat(·) represents the splicing operation of feature map channel, w2 is a 3 × 3 convolution, which is used to fuse the information between the four feature maps, w3 is a 1 × 1 convolution, which is used to reduce the number of channels of the fusion feature map, b2 and b3 are biases, and Relu(·) is the activation function. After the information of each part is fused, the feature map is input into the dual-attention mechanism module for feature enhancement. The calculation formula of the predicted output P1 of the conv3x module is
| (12) |
where pAttention(·) represents the spatial-attention mechanism module, cAttention(·) represents the channel-attention mechanism module, w4 represents 1 × 1 convolution, which is used to convert the number of channels into the number of classification categories, Upsample(·) represents a bilinear interpolation up-sampling operation, which is used to restore the size of output feature map to the size of the input image to obtain a predicted segmented image. Using the same method, the predicted output P0, P1, and P3 can be obtained. Finally, P0, P1, P2, and P3 are added and averaged to obtain the predicted segmented image. The calculation formula is
| (13) |
Equation (13) is the calculation expression for predicting segmentation P, where avg(·) represents the average operation.
In the GAN segmentation model established in this paper, the data processing capability of the ResNet50 extended based on the nonlocal dual-attention mechanism can mechanically ensure that the image multitarget features can be accurately extracted, while nonlocal attention mechanism also strengthens the output feature map of the ResNet50, which can further improve the accuracy of segmentation. The authenticity judgment of the adversarial network can guide the segmentation network to avoid the loss of detailed information as much as possible and optimize boundary segmentation and small-target segmentation.
3. The Learning Algorithm
3.1. The Loss Function
In the complex images' multitarget segmentation, it is necessary to calculate classification errors of multiclass pixel. In this paper, the multiclassification cross-entropy loss [40] is used as the loss function of the generative network, which is defined as follows:
| (14) |
Equation (14) represents the multiclassification cross-entropy loss of the label image x and the predicted segmentation y, where (H, W, C) represents the length, width, and number of channels of the image.
In the AM-GAN segmentation model, the adversarial network uses the authenticity loss to perform game learning with the generative network, which is essentially a binary classification problem. Therefore, the two-classification cross-entropy loss [41] is used as the loss function of the adversarial network, which is defined as follows:
| (15) |
Equation (15) represents the two-classification cross-entropy loss, where x represents the classification label and y represents the classification probability output of the adversarial network.
The loss function of the generative network is defined as follows:
| (16) |
where xn is the input image, yn is the label segmentation, and θg is the training parameter set of the generative network. According to equation (16), the loss of generative network is composed of two parts, that is, the multiclassification cross-entropy loss of prediction segmentation and label segmentation and the loss of adversarial network which predict segmentation. The hyperparameter λ is used to balance these two losses. When optimizing the generative network, we minimize the objective function.
The loss function of the adversarial network is defined as
| (17) |
where θ d represents the training parameter set of the adversarial network. From (17), the loss function of the adversarial network consists of two parts. The first is the two-classification cross-entropy loss of the mask map of input image xn and the label segmentation yn, which is judged to be true (that is, the value is 1). The second is the two-classification cross-entropy loss of the mask map of input image xn and the label segmentation g(xn), which is judged to be false (that is, the value is 0). When optimizing the adversarial network, we minimize the loss function.
The loss function of GAN is composed of the loss of the generative network and the loss of the adversarial network. The calculation expression is
| (18) |
3.2. The Training Process
AM-GAN adopts the method of alternate training of generative network and adversarial network. In order to ensure the stability of training, the training times of the discriminating module are generally more than that of the generative module. In this paper, the minibatch gradient descent (MBGD) algorithm is used for AM-GAN training. The specific process is as follows:
-
(1)
Randomly sample n samples zn from noise samples, and n samples xn from real samples.
-
(2)Gradient ascent algorithm is used to update the adversarial network:
(19) -
(3)
Repeat steps (1) and (2) k times to update the adversarial network k times.
-
(4)Sampling n generated samples from the noise samples, and we update the generative network once using gradient descent algorithm:
(20) -
(5)
Sequentially, we repeat the above steps until the model training is stable and optimal.
The specific algorithm implementation is as follows:
Step 1: determine and initialize the GAN training parameter set. The training parameter set of the generated network is θg=(w0, w1,…, wm, b0, b1,…, bm, g, θ, φ, wz, wc), where (w0, w1,…, wm) is the set of convolution kernel weight of extended ResNet50 network, (b0, b1,…, bm) is the set of biases, g, θ, φ, and wz are 1 × 1 convolution kernel weights of spatial-attention mechanism, and wc is 1 × 1 convolution kernel weights of channel-attention mechanism. The training parameter set of the adversarial network is θ d=(w0, w1,…, wn, b0, b1,…, bn), where (w0, w1,…, wn) is the set of convolution kernel weights of CNN, and (b0, b1,…, bn) is the set of biases.
Step 2: randomly select N image samples xn from the sample set, and select corresponding N label segmentation samples yn.
Step 3: calculate the loss of the adversarial network: ∇L(θ d)=1/N∑n=1N[Lbec(d(xn, yn, θ d), 1)+Lbec(d((xn, g(xn), θ d)), 0)].
Step 4: calculate the training parameter gradient according to the chain rule, ai=σ(zi)=σ(wiai−1+bi). σ is the activation function, ai is the input feature map of the ith layer, zi is the feature map of the ith layer after convolution, wi is the weight of the ith layer, and bi is the bias of the ith layer.
- The formula for calculating the weight gradient using the chain rule is
(21) where σ′(·) is the derivative of the activation function and (·)T represents the matrix transpose.
- The formula for calculating the bias gradient using the chain rule is
(22) - Step 5: use the MBGD optimizer to update the convolution weights and biases of the adversarial network:
(23) (24) Step 6: repeat Step 2 Step 5 k times.
Step 7: randomly select N image samples xn, and select corresponding N label segmentation samples yn.
- Step 8: calculate the loss ∇L(θg) of the generative network:
(25) Step 9: use the MBGD optimizer to update the parameters θg of the generation network.
Step 10: if the network converges to the optimal, then the training ends; otherwise, it returns to Step 2.
The epoch of training is set to 200 and the batch size is 10. According to the above algorithm process, the pseudocode of the training algorithm is shown in Algorithm 1.
Algorithm 1.

The AM-GAN training algorithm.
4. The Experiment and Result Analysis
4.1. The Experiment Dataset
The dataset comes from the Combined Healthy Abdominal Organ Segmentation (CHAOS) competition dataset [42]. The CHAOS dataset contains the abdomen MRI images. In the experiment, the abdominal MRI abdominal images containing the label information of the liver, left/right kidney, and spleen were selected as the sample set. The typical abdomen image and label segmentation image are shown in Figure 10.
Figure 10.

Data sample from CHAOS.
The experimental dataset contains 38 groups of abdominal MRI images, and each group has 26 slices with a size of 256 × 256, totaling 988 slices. The dataset is divided into a training set, a validation set, and a test set. The training set includes 30 groups of slices, the validation set includes 2 groups of slices, and the test set includes 6 groups of slices. Due to the small number of samples in the dataset, random rotation, mirroring, and other operations are used to enhance the data in the experiment. The final number of slices in the training set is expanded to 3120, the verification set is expanded to 104, and the test set is expanded to 312. The sample distribution of dataset is shown in Table 1.
Table 1.
Experimental dataset.
| Slice type | Training set | Validation set | Test set | Total |
|---|---|---|---|---|
| Original slice | 780 | 52 | 156 | 988 |
| Extended slice | 2340 | 52 | 156 | 2548 |
| Total | 3120 | 104 | 312 | 3536 |
4.2. The Model Structure and Parameter Settings
The training strategy of the AM-GAN is to alternate training between the generative network and the adversarial network. In order to ensure the stability of training, the ratio of the training times of the generative network and the adversarial network is set to 1 : 6, that is, the adversarial network training is performed 6 times first, and then, the generative network is trained once.
The size of the convolution kernel of the extended ResNet50 in the generative network is all 3 × 3, the step size of the downsampling is 2 × 2, and the other step size is 1 × 1. The activation function adopts the ReLu function, and the balance coefficient λ of the loss function of generative network is set to 0.2. The adversarial network includes 5 convolutional layers, 5 pooling layers, and 2 fully connected layers. The convolution kernel size of the convolutional layer is set to 3 × 3, and the step size is 1 × 1. The pooling window size of the pooling layer is set to 2 × 2, and the step size is 2 × 2. The Sigmoid function is used as the classification function. The learning rate of the MBGD optimizer is set to 0.01, and the weight parameters are initialized with truncated normal distribution. The number of training iterations is 200, and the batch of one training is 10. The experimental environment is Linux system with NVIDIA GeForce RTX 2080Ti GPU.
4.3. The Experiment Result and Analysis
The AM-GAN training is carried out according to the algorithm strategy in Section 3 and the model structure and parameter setting in Section 4.2. Multitarget image segmentation is performed by generative network. Recall rate, precision, F1-score, accuracy, and Dice similarity coefficient are used to evaluate the properties of the segmentation model. The image segmentation experiment results of the test set are shown in Figure 11, and the index evaluation results are shown in Table 2.
Figure 11.
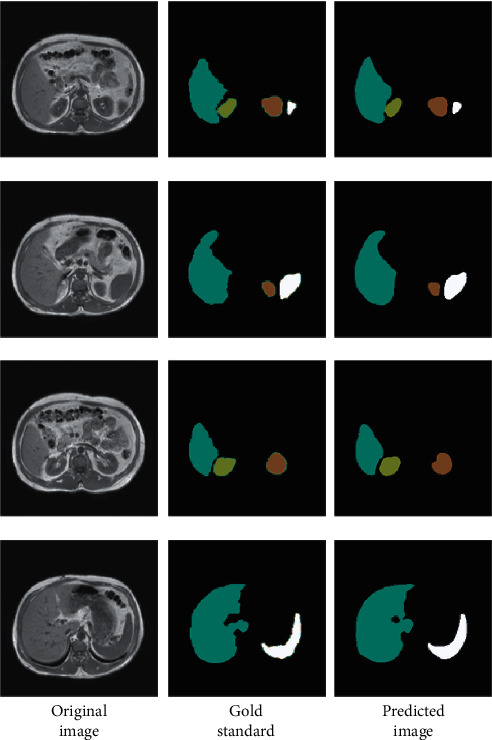
Comparison of model prediction segmentation and gold standard.
Table 2.
The evaluation results of AM-GAN.
| Recall (%) | Precision (%) | F1-score (%) | Accuracy (%) |
|---|---|---|---|
| 90.3 | 92.1 | 91.2 | 92.3 |
In Figure 11, from left to right, there is the original abdominal image, the gold standard, that is, the image manually segmented by the expert, and the predicted segmented image by network. From Figure 11, the segmentation results of the GAN are clear and smooth. Whether it is a large-sized organ such as the liver or a small-sized organ such as the kidney and pancreas, the GAN can distinguish them more accurately, which shows that the proposed method has good applicability.
For analyzing the properties of the learning algorithm, the curves of the Dice coefficient indicators of four organs and tissues, including liver, left kidney, right kidney, and spleen changing with iteration, and the confusion matrix of the validation set are recorded. The results are shown in Figure 12 and Table 3.
Figure 12.
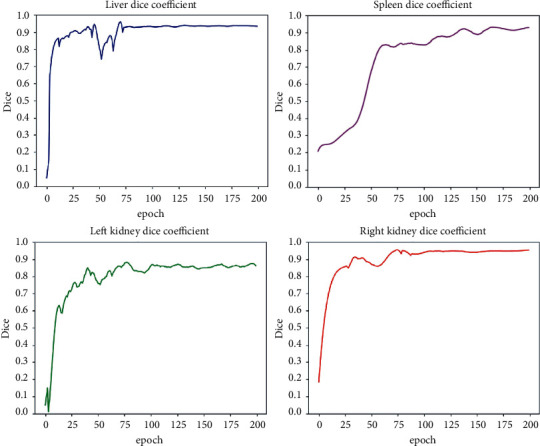
Variation curve of Dice coefficient of the segmented organ.
Table 3.
Model numerical confusion matrix.
| Type | Background | Liver | Left kidney | Right kidney | Spleen |
|---|---|---|---|---|---|
| Background | 99.32% | 0.59% | 0.02% | 0.02% | 0.05% |
| Liver | 1.89% | 97.55% | 0.24% | 0.14% | 0.18% |
| Left kidney | 9.28% | 7.73% | 82.39% | 0.29% | 0.31% |
| Right kidney | 4.72% | 0% | 0% | 92.68% | 2.6% |
| Spleen | 4.71% | 0% | 0% | 1.17% | 94.12% |
In Figure 12, the Dice similarity coefficient training curves of the liver, left kidney, right kidney, and spleen are shown. The Dice curve of the liver converges quickly and is relatively stable in the later iterations. This is because its size is relatively large compared to other organs, which causes the segmentation network to be more inclined to learn the classification of the liver area pixels in the early stage. The left kidney, right kidney, and spleen organs are smaller in size than the liver, and the segmentation network has a deeper level, which leads to easy loss of information and large fluctuations in the training. In the later stage of training, the average Dice coefficient of liver, left kidney, right kidney, and spleen on the training set is 0.92, which shows that the overall effect of model segmentation is good, and it has good applicability to small-target segmentation.
From Table 3, the segmentation accuracy of liver organs is the highest, 97.55%. This is because the size of liver organs is relatively large, and the network tends to learn their pixel weights of liver organs. The spatial location of the left kidney and the liver area is relatively close, and the boundary tissues overlap, leading to the segmentation error of the left kidney mainly from the liver and background. The right kidney and spleen organs are close in space, leading to mutual influence. The right kidney and spleen are small-target organs, and there is no boundary overlap, so the segmentation is less affected than the left kidney. From the confusion matrix, the accuracy of left kidney segmentation was 82.39%, while that of right kidney segmentation was 92.68% and that of spleen segmentation was 94.12%. It shows that the method in this paper has a good ability to identify and distinguish the features of complex image pixel categories.
4.4. Comparative Experiment and Analysis
In order to verify the performance improvement of AM-GAN brought by the nonlocal attention mechanism, a ResNet-GAN model was constructed in the comparative experiment. This model removes the nonlocal attention mechanism in AM-GAN, and other structures are the same as the AM-GAN. In addition, current mainstream, AM-FCN [43] embedded based on attention, Attention U-Net [44] fused on attention in both encoder and decoder, DANet [45] embedded based on dual attention, and SEVNet [46] fused on SE module are selected as comparison models. The four index values of accuracy, recall, precision, and F1-score are used for comparative evaluation. In order to avoid misleading the performance evaluation by high background indicators, all evaluation indicators do not include the value of background indicators. The specific results are shown in Table 4.
Table 4.
Comparison of results of different models.
| Model | Recall (%) | Precision (%) | F1-score (%) | Accuracy (%) |
|---|---|---|---|---|
| FCN | 85.4 | 86.2 | 83.5 | 85.6 |
| U-net | 87.1 | 87.4 | 87.2 | 86.9 |
| DANet | 91.7 | 90.3 | 91.0 | 91.2 |
| ResNet-GAN | 89.2 | 91.5 | 90.1 | 91.2 |
| SEVNet | 86.5 | 87.6 | 86.8 | 87.1 |
| Proposed | 90.3 | 92.1 | 91.2 | 92.3 |
From Table 4, the four indexes of AM-FCN and Attention U-Net are lower than the proposed model. This is because it organically integrates GAN's inherent ability to process and repair low-resolution images, and the global to local content association and feature enhancement mechanism of nonlocal attention improves the accuracy of multitarget segmentation results. Except for the recall rate, other indexes of DANet are lower than that of the proposed model, which shows that the nonlocal attention mechanism used in this model can gather the receptive field from global to local target area to realize information context correlation. In addition, GAN can optimize the segmentation results in mechanism and improve the segmentation properties of the model, and the model and algorithm are relatively robust. Compared with ResNet-GAN, the accuracy of proposed model is 1.1% higher, which shows that the nonlocal attention can effectively realize the information association from global to local. Combined with GAN's probability exploration mechanism, the segmentation accuracy of the model is comprehensively improved. Compared with the SEVNet, due to the inherent high-definition processing and repairing capabilities of the GAN for noise images and the use of a game strategy, the optimization of the segmentation results is realized, and the accuracy, continuity, and smoothness of the segmentation results are comprehensively improved. Based on the above analysis, it shows that the method in this paper has comprehensive advantages when performing image target segmentation with insignificant structural features and achieves a better segmentation effect.
5. Conclusion
In this paper, aiming at the fine segmentation of multitarget complex images, a generative adversarial network model fused with attention mechanism is proposed. In mechanism, the AM-GAN can use the ability to process and restore high-definition images of GAN to effectively reduce the effects of noise, offset distortion, and gray value distortion. Nonlocal spatial-channel dual attention is introduced to realize the information association and constraint of large receptive field content on local targets and maintain the continuity of segmentation results. At the same time, the Nash game strategy of the generative network and the adversarial network is adopted, which reduces the algorithm's loss of detailed features and effectively improves the accuracy of small-target segmentation. In terms of information processing mechanism, this method comprehensively realizes the context correlation of image information, the feature fusion of different levels and scales, the high-definition processing and repair of high-noise images, and the optimization of segmentation results. The experimental results show that the multitarget segmentation method proposed in this paper has good applicability for both small-size and large-size targets. Compared with the other methods, each evaluation index has been greatly improved. AM-GAN comprehensively utilizes the advantages of nonlocal attention mechanism and generative adversarial network, which can finely segment multi-instance targets in complex images. It has good applicability in mechanism to solve the image segmentation problem of insignificant morphological features and weak spatial information relevance. It improves the limitations and deficiencies of the comparison method in solving the above problems, provides a novel deep learning method for image segmentation, and has great application value and a good prospect for promotion. However, the information processing mechanism and algorithm process of the method in this paper are more complicated, and the image semantic knowledge and structural features are less used. From the experimental results, the proportion of image background pixels compared with target area pixels is too large, and the number of samples in the dataset is unbalanced, which still has a certain impact on the segmentation accuracy of this method. How to optimize the model and algorithm, improve the discrimination ability of the local target image and the background image, and embed the scene semantic feature knowledge into the segmentation model, which will be an important work in the next stage of research.
Acknowledgments
This work was supported by the Shandong University of Science and Technology Research Fund, under Grant 2019TDJH102.
Data Availability
The data that support the findings of this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Supplementary Materials
The AM-GAN model combines the generative network based on the residual network and the nonlocal dual-attention mechanism with the adversarial network based on the CNNs to build a generative adversarial network model for the multitarget image segmentation. After AM-GAN is trained to reach the optimum, the model used for image segmentation is a generator network.
References
- 1.Minaee S., Boykov Y. Y., Porikli F., Plaza A. J., Kehtarnavaz N., Terzopoulos D. Image segmentation using deep learning: a survey. IEEE Transactions on Pattern Analysis and Machine Intelligence . 2020;15 doi: 10.1109/TPAMI.2021.3059968. [DOI] [PubMed] [Google Scholar]
- 2.Chen C., Qin C., Qiu H., et al. Deep learning for cardiac image segmentation: a review. Frontiers in Cardiovascular Medicine . 2020;7:p. 25. doi: 10.3389/fcvm.2020.00025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Zhou Z., Rahman Siddiquee M. M., Tajbakhsh N., Liang J. Unet++: a nested u-net architecture for medical image segmentation. Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support . 2018;28:3–11. doi: 10.1007/978-3-030-00889-5_1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Gu Z., Cheng J., Fu H., et al. CE-net: context encoder network for 2D medical image segmentation. IEEE Transactions on Medical Imaging . 2019;38(10):2281–2292. doi: 10.1109/tmi.2019.2903562. [DOI] [PubMed] [Google Scholar]
- 5.Milletari F., Navab N., Ahmadi S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV); October 2016; Stanford, CA, USA. IEEE; pp. 565–571. [Google Scholar]
- 6.Hesamian M. H., Jia W., He X., Kennedy P. Deep learning techniques for medical image segmentation: achievements and challenges. Journal of Digital Imaging . 2019;32(4):582–596. doi: 10.1007/s10278-019-00227-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Razzak M. I., Naz S., Zaib A. Deep learning for medical image processing: overview, challenges and the future. Lecture Notes in Computational Vision and Biomechanics . 2018;24:323–350. doi: 10.1007/978-3-319-65981-7_12. [DOI] [Google Scholar]
- 8.Liu D., Wang S., Huang D., Deng G., Zeng F., Chen H. Medical image classification using spatial adjacent histogram based on adaptive local binary patterns. Computers in Biology and Medicine . 2016;72:185–200. doi: 10.1016/j.compbiomed.2016.03.010. [DOI] [PubMed] [Google Scholar]
- 9.Zhang Y., Liu Y., Cheng H., Li Z., Liu C. Fully multi-target segmentation for breast ultrasound image based on fully convolutional network. Medical, & Biological Engineering & Computing . 2020;58(9):2049–2061. doi: 10.1007/s11517-020-02200-1. [DOI] [PubMed] [Google Scholar]
- 10.Tian Y., Dehghan A., Shah M. On detection, data association and segmentation for multi-target tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence . 2018;41(9):2146–2160. doi: 10.1109/TPAMI.2018.2849374. [DOI] [PubMed] [Google Scholar]
- 11.Dinghan W., Guilan F., Xiong W., Yufeng W., Maohua D. Research on image segmentation algorithm based on features of venous gray value. Opto-Electronic Engineering . 2018;45(12):180066–180071. [Google Scholar]
- 12.Makandar A., Halalli B. Threshold based segmentation technique for mass detection in mammography. Journal of Computers . 2016;11(6):472–478. doi: 10.17706/jcp.11.6.463-4712. [DOI] [Google Scholar]
- 13.Gupta D., Anand R. S. A hybrid edge-based segmentation approach for ultrasound medical images. Biomedical Signal Processing and Control . 2017;31:116–126. doi: 10.1016/j.bspc.2016.06.012. [DOI] [Google Scholar]
- 14.Kashyap R., Gautam P. Modified region based segmentation of medical images. Proceedings of the 2015 International Conference on Communication Networks (ICCN); November 2015; Gwalior, India. IEEE; pp. 209–216. [DOI] [Google Scholar]
- 15.Krizhevsky A., Sutskever I., Hinton G. E. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems . 2012;25:1097–1105. [Google Scholar]
- 16.He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; June 2016; Las Vegas, NV, USA. pp. 770–778. [DOI] [Google Scholar]
- 17.Ren S., He K., Girshick R., Sun J. Faster r-cnn: towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems . 2015;28:91–99. [Google Scholar]
- 18.Wang J., Zhu H., Wang S.-H., Zhang Y.-D. A review of deep learning on medical image analysis. Mobile Networks and Applications . 2021;26(1):351–380. doi: 10.1007/s11036-020-01672-7. [DOI] [Google Scholar]
- 19.Despotović I., Goossens B., Philips W. Mri segmentation of the human brain: challenges, methods, and applications, computational and mathematical methods in medicine. 2015. [DOI] [PMC free article] [PubMed]
- 20.Long J., Shelhamer E., Darrell T. Fully convolutional networks for semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; June 2015; Boston, MA, USA. pp. 3431–3440. [DOI] [PubMed] [Google Scholar]
- 21.Ronneberger O., Fischer P., Brox T., U-net U-net: convolutional networks for biomedical image segmentation. Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; October 2015; Munich, Germany. pp. 234–241. [DOI] [Google Scholar]
- 22.Çiçek Ö., Abdulkadir A., Lienkamp S. S., Brox T., Ronneberger O. 3d u-net: learning dense volumetric segmentation from sparse annotation. Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016 . 2016;32:424–432. doi: 10.1007/978-3-319-46723-8_49. [DOI] [Google Scholar]
- 23.Zhang Q., Cui Z., Niu X., Geng S., Qiao Y. Image segmentation with pyramid dilated convolution based on resnet and u-net. Neural Information Processing . 2017;44:364–372. doi: 10.1007/978-3-319-70096-0_38. [DOI] [Google Scholar]
- 24.Nguyen D., Jia X., Sher D., et al. 3d radiotherapy dose prediction on head and neck cancer patients with a hierarchically densely connected u-net deep learning architecture. Physics in Medicine and Biology . 2019;64(6) doi: 10.1088/1361-6560/ab039b.065020 [DOI] [PubMed] [Google Scholar]
- 25.Oktay O., Schlemper J., Folgoc L. L., et al. Attention U-net: learning where to look for the pancreas. 2013. https://arxiv.org/abs/1804.03999 .
- 26.Badrinarayanan V., Kendall A., Cipolla R. Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence . 2017;39(12):2481–2495. doi: 10.1109/tpami.2016.2644615. [DOI] [PubMed] [Google Scholar]
- 27.Chen Y., Tao J., Liu L., et al. Research of improving semantic image segmentation based on a feature fusion model. Journal of Ambient Intelligence and Humanized Computing . 2020;7:1–13. doi: 10.1007/s12652-020-02066-z. [DOI] [Google Scholar]
- 28.Zhang J., Liu Y., Liu H., Wang J., Zhang Y. Distractor-aware visual tracking using hierarchical correlation filters adaptive selection. Applied Intelligence . 2021;16:1–19. [Google Scholar]
- 29.Chen Y., Liu L., Phonevilay V., et al. Image super-resolution reconstruction based on feature map attention mechanism. Applied Intelligence . 2021;14:1–14. [Google Scholar]
- 30.Chen Y., Zhang H., Liu L., et al. Research on image inpainting algorithm of improved total variation minimization method. Journal of Ambient Intelligence and Humanized Computing . 2021;22:1–10. doi: 10.1007/s12652-020-02778-2. [DOI] [Google Scholar]
- 31.Chen Y., Liu L., Tao J., et al. The improved image inpainting algorithm via encoder and similarity constraint. The Visual Computer . 2021;37(7):1691–1705. doi: 10.1007/s00371-020-01932-3. [DOI] [Google Scholar]
- 32.Goodfellow I., Pouget-Abadie J., Mirza M., et al. Generative adversarial nets. Advances in Neural Information Processing Systems . 2013;27 [Google Scholar]
- 33.Upadhyay U., Awate S. P. A mixed-supervision multilevel gan framework for image quality enhancement. Proceeedigs of the International Conference on Medical Image Computing and Computer-Assisted Intervention; October 2019; Athens, Greece. pp. 556–564. [DOI] [Google Scholar]
- 34.Chen Y., Zhang H., Liu L., et al. Research on image inpainting algorithm of improved gan based on two-discriminations networks. Applied Intelligence . 2021;51(6):3460–3474. doi: 10.1007/s10489-020-01971-2. [DOI] [Google Scholar]
- 35.Niu Z., Zhong G., Yu H. A review on the attention mechanism of deep learning. Neurocomputing . 2021;452:48–62. doi: 10.1016/j.neucom.2021.03.091. [DOI] [Google Scholar]
- 36.Yan C., Tu Y., Wang X., et al. Stat: spatial-temporal attention mechanism for video captioning. IEEE Transactions on Multimedia . 2019;22(1):229–241. [Google Scholar]
- 37.Xu R., Tao Y., Lu Z., Zhong Y. Attention-mechanism-containing neural networks for high-resolution remote sensing image classification. Remote Sensing . 2018;10(10):p. 1602. doi: 10.3390/rs10101602. [DOI] [Google Scholar]
- 38.Wang X., Girshick R., Gupta A., He K. Non-local neural networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; June 2018; Salt Lake City, UT, USA. pp. 7794–7803. [DOI] [Google Scholar]
- 39.Santoro A., Faulkner R., Raposo D., et al. Relational recurrent neural networks. 2016. https://arxiv.org/abs/1806.01822 .
- 40.Liu J.-W., Wang Y.-F., Lu R.-K., Luo X.-L. Multi-view non-negative matrix factorization discriminant learning via cross entropy loss. Proceedings of the 2020 Chinese Control and Decision Conference (CCDC); June 2020; Kunming, China. pp. 3964–3971. [DOI] [Google Scholar]
- 41.Ramos D., Franco-Pedroso J., Lozano-Diez A., Gonzalez-Rodriguez J. Deconstructing cross-entropy for probabilistic binary classifiers. Entropy . 2018;20(3):p. 208. doi: 10.3390/e20030208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Kavur A. E., Gezer N. S., Barış M., et al. CHAOS Challenge - combined (CT-MR) healthy abdominal organ segmentation. Medical Image Analysis . 2021;69 doi: 10.1016/j.media.2020.101950.101950 [DOI] [PubMed] [Google Scholar]
- 43.Yue Z., Gao F., Xiong Q., Wang J., Hussain A., Zhou H. A novel attention fully convolutional network method for synthetic aperture radar image segmentation. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing . 2020;13:4585–4598. doi: 10.1109/jstars.2020.3016064. [DOI] [Google Scholar]
- 44.Islam M., Vibashan V., Jose V. J. M., Wijethilake N., Utkarsh U., Ren H. Brain Tumour segmentation and survival prediction using 3d attention unet. Proceedings of the International MICCAI Brainlesion Workshop; September 2019; Strasbourg, France. pp. 262–272. [Google Scholar]
- 45.Fu J., Liu J., Tian H., et al. Dual attention network for scene segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019; Long Beach, CA, USA. pp. 3146–3154. [DOI] [Google Scholar]
- 46.Zhao Y., Chen J., Xu X., Lei J., Zhou W. Sev-net: residual network embedded with attention mechanism for plant disease severity detection. Concurrency and Computation: Practice and Experience . 2021;33(10) doi: 10.1002/cpe.6161.e6161 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The AM-GAN model combines the generative network based on the residual network and the nonlocal dual-attention mechanism with the adversarial network based on the CNNs to build a generative adversarial network model for the multitarget image segmentation. After AM-GAN is trained to reach the optimum, the model used for image segmentation is a generator network.
Data Availability Statement
The data that support the findings of this study are available upon request from the corresponding author.