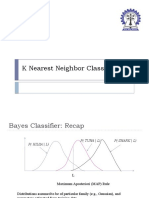
CpE646 8v3 PDF
CpE646 8v3 PDF
Download as pdf or txt
You might also like
- II Puc Maths MCQ (Part - A)Document44 pagesII Puc Maths MCQ (Part - A)Vansh Gupta100% (3)
- Some Special Discrete Probability DistributionsDocument20 pagesSome Special Discrete Probability DistributionsMalathiVelu0% (1)
- Gaussian Processes in Machine Learning TutorialDocument55 pagesGaussian Processes in Machine Learning Tutorialsakya_dasguptaNo ratings yet
- 20180723161729D4730 - Pert18 - K-Nearest NeighborDocument22 pages20180723161729D4730 - Pert18 - K-Nearest NeighborJihan NabilaNo ratings yet
- K Nearest Neighbor ClassificationDocument32 pagesK Nearest Neighbor ClassificationRanjan0% (1)
- CpE646 7v3 PDFDocument40 pagesCpE646 7v3 PDFGurpreet SinghNo ratings yet
- Foundations of Machine Learning: Part A: Probability BasicsDocument75 pagesFoundations of Machine Learning: Part A: Probability Basicsnilayesh.bhattacharyaNo ratings yet
- Math 1060 - Lecture 4Document12 pagesMath 1060 - Lecture 4John LeeNo ratings yet
- Probability Distributions in RDocument42 pagesProbability Distributions in RNaski KuafniNo ratings yet
- Lecture 4: Random Variables and DistributionsDocument31 pagesLecture 4: Random Variables and DistributionsJBANo ratings yet
- Review 2 SummaryDocument4 pagesReview 2 Summarydinhbinhan19052005No ratings yet
- L2 Basic MathematicsDocument32 pagesL2 Basic Mathematicsaarshiya kcNo ratings yet
- Lecture Notes, FormulasDocument79 pagesLecture Notes, FormulasLourence Kate TumaliuanNo ratings yet
- Nonparametric Density Estimation Nearest Neighbors, KNNDocument31 pagesNonparametric Density Estimation Nearest Neighbors, KNNiam_eckoNo ratings yet
- Lecture 7 Random Variable Confidence IntervalDocument52 pagesLecture 7 Random Variable Confidence Intervalmariloh6102No ratings yet
- Random Variables: Petter Mostad 2005.09.19Document24 pagesRandom Variables: Petter Mostad 2005.09.19liteepanNo ratings yet
- s2 Revision NotesDocument5 pagess2 Revision NotesAlex KingstonNo ratings yet
- Practical 5Document4 pagesPractical 5rtchuidjangnanaNo ratings yet
- MIT18 05S14 Cl5cont Slides PDFDocument12 pagesMIT18 05S14 Cl5cont Slides PDFMoMoNo ratings yet
- Week 7 Nearest NeighboursDocument21 pagesWeek 7 Nearest NeighbourszeliawillscumbergNo ratings yet
- Lecture 7Document108 pagesLecture 7Sourabh DandareNo ratings yet
- Probability and Randomized AlgorithmsDocument14 pagesProbability and Randomized Algorithmsamirali55No ratings yet
- Non ParametricDocument42 pagesNon ParametricstcaseNo ratings yet
- Machine Learning: DR Ajey S.N.RDocument123 pagesMachine Learning: DR Ajey S.N.RSai Satya Krishna PathuriNo ratings yet
- Lectures 8-9 DraftDocument44 pagesLectures 8-9 DraftKiki123No ratings yet
- Stat 535 C - Statistical Computing & Monte Carlo Methods: Arnaud DoucetDocument23 pagesStat 535 C - Statistical Computing & Monte Carlo Methods: Arnaud DoucetTalvany Luis de BarrosNo ratings yet
- ECE523 Engineering Applications of Machine Learning and Data Analytics - Bayes and Risk - 1Document7 pagesECE523 Engineering Applications of Machine Learning and Data Analytics - Bayes and Risk - 1wandalexNo ratings yet
- Probability CheatsheetDocument4 pagesProbability CheatsheetYassine MsaddakNo ratings yet
- DBSCANDocument42 pagesDBSCANY SAHITHNo ratings yet
- Christian Notes For Exam PDocument9 pagesChristian Notes For Exam Proy_getty100% (1)
- Statistical Undecidability - SSRN-Id1691165Document4 pagesStatistical Undecidability - SSRN-Id1691165adeka1No ratings yet
- Chapter 2Document26 pagesChapter 2praveenm026No ratings yet
- Rakhlin Mathstat sp22Document108 pagesRakhlin Mathstat sp22vvddupNo ratings yet
- Formula Sheet 2024Document25 pagesFormula Sheet 2024Amy Tint MyatNo ratings yet
- Sampling Distributions & Standard Error: Lesson 7Document20 pagesSampling Distributions & Standard Error: Lesson 7Lorena TeofiloNo ratings yet
- Lecture 17 - KNNDocument18 pagesLecture 17 - KNNraoseshuNo ratings yet
- BIOSTAT Random Variables & Probability DistributionDocument37 pagesBIOSTAT Random Variables & Probability DistributionAnonymous Xlpj86laNo ratings yet
- Thirteen 19240 PDFDocument17 pagesThirteen 19240 PDFRam Bhagat SoniNo ratings yet
- P (X) - N! - X! (N-X) ! P (1-p) : FormulaDocument6 pagesP (X) - N! - X! (N-X) ! P (1-p) : FormulaSofiaNo ratings yet
- Lecture 5Document127 pagesLecture 5Sourabh DandareNo ratings yet
- R300 Advanced Econometrics Methods Lecture SlidesDocument362 pagesR300 Advanced Econometrics Methods Lecture SlidesMarco BrolliNo ratings yet
- Discrete Distributions: Bernoulli Random VariableDocument27 pagesDiscrete Distributions: Bernoulli Random VariableThapelo SebolaiNo ratings yet
- w5 ClassificationDocument34 pagesw5 ClassificationSwastik SindhaniNo ratings yet
- Random VariableDocument39 pagesRandom Variablersgtd dhdfjdNo ratings yet
- A 18-Page Statistics & Data Science Cheat SheetsDocument18 pagesA 18-Page Statistics & Data Science Cheat SheetsAniket AggarwalNo ratings yet
- S6 Normal DistributionDocument26 pagesS6 Normal Distributionwaiwaichoi112No ratings yet
- Formula Sheet SBDocument17 pagesFormula Sheet SBkirisugutokisadaNo ratings yet
- Unit 2 P&SDocument82 pagesUnit 2 P&Sduaankush2004No ratings yet
- Instance Based LearningDocument20 pagesInstance Based Learningd sandeepNo ratings yet
- Data Analysis For Social Scientists (14.1310x)Document12 pagesData Analysis For Social Scientists (14.1310x)SebastianNo ratings yet
- Lecture Two (2)Document13 pagesLecture Two (2)Costantine Andrew Jr.No ratings yet
- Discrete Structures/MathematicsDocument46 pagesDiscrete Structures/MathematicsjojoNo ratings yet
- Sam Roweis ProbxDocument12 pagesSam Roweis ProbxJingkui WangNo ratings yet
- Bayesian TheoryDocument66 pagesBayesian TheoryPaul WalkerNo ratings yet
- Distributions 1Document18 pagesDistributions 1Paarsa KhanNo ratings yet
- BusMath-FormulasDocument3 pagesBusMath-FormulascastrojaniemNo ratings yet
- Asymptotic Statistics (By Changliang ZOU)Document115 pagesAsymptotic Statistics (By Changliang ZOU)b8vg52h8ywNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Mathematical Foundations of Information TheoryFrom EverandMathematical Foundations of Information TheoryRating: 3.5 out of 5 stars3.5/5 (9)
- STA642 Short Notes Written by Mahar Afaq Safdar MuhammadiDocument13 pagesSTA642 Short Notes Written by Mahar Afaq Safdar MuhammadiMuhammad AlamNo ratings yet
- Qpaper - Ignou - June 2018 - MathsDocument3 pagesQpaper - Ignou - June 2018 - MathsbinalamitNo ratings yet
- Math H - 7-10Document15 pagesMath H - 7-10Jared FradejasNo ratings yet
- UPSC Civil Services Main 1996 - Mathematics Algebra: Sunder LalDocument3 pagesUPSC Civil Services Main 1996 - Mathematics Algebra: Sunder LalRishabh SareenNo ratings yet
- Symmetries of An Equilateral TriangleDocument23 pagesSymmetries of An Equilateral TriangleSarah Seunarine100% (1)
- Grade 11 Series AssessmentDocument5 pagesGrade 11 Series AssessmentKEVIN OKECHNo ratings yet
- S4 09-10 Half Yearly Paper IDocument16 pagesS4 09-10 Half Yearly Paper IAlex LamNo ratings yet
- Syllabus WWU 204Document6 pagesSyllabus WWU 204Melisa EstesNo ratings yet
- MAT1320 - Lecture11Document6 pagesMAT1320 - Lecture11mmashNo ratings yet
- Chapter 2.9-3.1-3.2-3.3Document49 pagesChapter 2.9-3.1-3.2-3.3haloNo ratings yet
- 12th Maths EM Quarterly Exam 2023 Original Question Paper Thenkasi District English Medium PDF DownloadDocument4 pages12th Maths EM Quarterly Exam 2023 Original Question Paper Thenkasi District English Medium PDF Downloadabinavediyappan0103No ratings yet
- The Mean Value TheoremDocument5 pagesThe Mean Value TheoremMoetassem SarayaNo ratings yet
- List of Important MathematiciansDocument8 pagesList of Important MathematiciansEris Sodalite100% (1)
- Mathematicaleconomics PDFDocument84 pagesMathematicaleconomics PDFSayyid JifriNo ratings yet
- A Unified Formula For The NTH Derivative and The NTH Anti-Derivative of The Bessel Function of Real OrdersDocument5 pagesA Unified Formula For The NTH Derivative and The NTH Anti-Derivative of The Bessel Function of Real OrdersRounak BasuNo ratings yet
- Revit FormulasDocument6 pagesRevit FormulasMaxwell100% (2)
- 2006Document4 pages2006Jubeth PalerNo ratings yet
- Cse 5-3Document4 pagesCse 5-3Riya PatilNo ratings yet
- If The IRS Had Discovered The Quadratic FormulaDocument1 pageIf The IRS Had Discovered The Quadratic FormulaJeff PrattNo ratings yet
- Finite Element Implementation of Incompressible, Transversely Isotropic HyperelasticityDocument22 pagesFinite Element Implementation of Incompressible, Transversely Isotropic HyperelasticityManuelNo ratings yet
- Chapter 2 SOLVING NONLINEAR EQUATION 2Document20 pagesChapter 2 SOLVING NONLINEAR EQUATION 2muhammad iqbalNo ratings yet
- Numerical Methods For Hamilton-Jacobi-Bellman EquationsDocument68 pagesNumerical Methods For Hamilton-Jacobi-Bellman EquationsbobmezzNo ratings yet
- A Level Formula SheetDocument1 pageA Level Formula SheetstudierNo ratings yet
- GenMath First Summative TestDocument3 pagesGenMath First Summative TestAngelie Limbago CagasNo ratings yet
- NOTES #1 in MATH 01 - BASIC STATISTICS) - MCTDocument9 pagesNOTES #1 in MATH 01 - BASIC STATISTICS) - MCTKaryfe Von OrtezaNo ratings yet
- g11 Maths p1 KZN Nov 2023Document9 pagesg11 Maths p1 KZN Nov 2023in luv w moneyNo ratings yet
- Bachelor of Science (B.SC.) Semester-I Examination Mathematics (Algebra and Trigonometry) Optional Paper-1Document3 pagesBachelor of Science (B.SC.) Semester-I Examination Mathematics (Algebra and Trigonometry) Optional Paper-1Swapnil KamdiNo ratings yet
- Mathematics Class IXDocument9 pagesMathematics Class IXKulachi Hansraj Model School91% (11)