Spss
Spss
Download as docx, pdf, or txt
You might also like
- Fundamentals of Business Communication by Dr. Sherry J. Roberts PH.D., Terry RoachDocument6 pagesFundamentals of Business Communication by Dr. Sherry J. Roberts PH.D., Terry RoachMark Jovin RomNo ratings yet
- Chapter 6 Short Exercise SolutionsDocument11 pagesChapter 6 Short Exercise Solutionsbaseballjunker4100% (1)
- Corporate Finance NPV and IRR SolutionsDocument3 pagesCorporate Finance NPV and IRR SolutionsMark HarveyNo ratings yet
- Suggested Solutions Chapter 5Document5 pagesSuggested Solutions Chapter 5hayat0150% (2)
- Assignment 1Document2 pagesAssignment 1Elston DsouzaNo ratings yet
- Simulation: Chapter - 13Document10 pagesSimulation: Chapter - 13JankiNo ratings yet
- Finance Practice File 1 With SolutionsDocument18 pagesFinance Practice File 1 With Solutionsdscgool1232100% (2)
- The Arden County Busing ProblemDocument1 pageThe Arden County Busing Problemlyndy1969No ratings yet
- Activity 3 7Document7 pagesActivity 3 7api-306786165No ratings yet
- Solusi Soal Bab 4Document9 pagesSolusi Soal Bab 4SatriaNo ratings yet
- Tutorial 02 QuestionsDocument2 pagesTutorial 02 QuestionsAamir ShaikNo ratings yet
- Chapter 1Document15 pagesChapter 1GpeexpoNo ratings yet
- Stock Valuation Practice QuestionsDocument3 pagesStock Valuation Practice QuestionsMillat Equipment Ltd Pakistan0% (1)
- Exercise NumericalsDocument21 pagesExercise NumericalsSardar Ghayoor ZaheenNo ratings yet
- Problem Set-Bond Valuation ProblemsasdadDocument4 pagesProblem Set-Bond Valuation ProblemsasdadJerauld BucolNo ratings yet
- Bond Valuation ProblemsDocument2 pagesBond Valuation ProblemsChloeNo ratings yet
- RR Problems SolutionsDocument5 pagesRR Problems SolutionsShaikh FarazNo ratings yet
- Special Probability Distributions: Presented By: Juanito S. ChanDocument37 pagesSpecial Probability Distributions: Presented By: Juanito S. ChanGelli AgustinNo ratings yet
- Chapter 7: Production and Cost in The FirmDocument3 pagesChapter 7: Production and Cost in The FirmemilianodelgadoNo ratings yet
- Mixi - Facebook Case AnalysisDocument11 pagesMixi - Facebook Case AnalysisAbriel Bumatay100% (1)
- CFF 3 Im 04Document33 pagesCFF 3 Im 04AL SeneedaNo ratings yet
- Bond Solution ProblemsDocument7 pagesBond Solution ProblemsNojoke1No ratings yet
- Financial Ratios - Top 28 Financial Ratios (Formulas, Type)Document7 pagesFinancial Ratios - Top 28 Financial Ratios (Formulas, Type)farhadcse30No ratings yet
- Abubaker Muhammad Haroon 55127Document4 pagesAbubaker Muhammad Haroon 55127Abubaker NathaniNo ratings yet
- An Overview of Financial Management: Multiple Choice: ConceptualDocument15 pagesAn Overview of Financial Management: Multiple Choice: ConceptualJully GonzalesNo ratings yet
- Group 1-Capital Budgeting Case Study 2Document8 pagesGroup 1-Capital Budgeting Case Study 2JohnNo ratings yet
- George Foster Financial Statement AnalysisDocument2 pagesGeorge Foster Financial Statement AnalysisdnesudhudhNo ratings yet
- PM T1Document4 pagesPM T1SiewChenSohNo ratings yet
- 2011-02-03 230149 ClarkupholsteryDocument5 pages2011-02-03 230149 ClarkupholsteryJesus Cardenas100% (1)
- Lesson: 7 Cost of CapitalDocument22 pagesLesson: 7 Cost of CapitalEshaan ChadhaNo ratings yet
- Organizational BehaviourDocument16 pagesOrganizational BehaviourctgboyNo ratings yet
- Cocacola Case SolutionDocument2 pagesCocacola Case SolutionRajaram IyengarNo ratings yet
- Chapter 10 - Aggregate Demand IDocument30 pagesChapter 10 - Aggregate Demand IwaysNo ratings yet
- Chap 008Document16 pagesChap 008van tinh khucNo ratings yet
- Growth of Corporation Occurs Through 1. Internal Expansion That Is Growth 2. MergersDocument8 pagesGrowth of Corporation Occurs Through 1. Internal Expansion That Is Growth 2. MergersFazul Rehman100% (1)
- ME Lecture5Document33 pagesME Lecture5Song YueNo ratings yet
- A Term Paper On Financing Mix and Choices, Dividend Policy, Analyzing Cash Return To Stockholders and Beyond Cash DividendsDocument20 pagesA Term Paper On Financing Mix and Choices, Dividend Policy, Analyzing Cash Return To Stockholders and Beyond Cash DividendsRakibul Rony100% (1)
- Bond ValuationsDocument42 pagesBond ValuationsΠαναγιώτης ΚαλαμποκάςNo ratings yet
- Chap 7 and 8 QuizDocument3 pagesChap 7 and 8 QuizWelshfyn ConstantinoNo ratings yet
- Cost Accounting and Management AccountingDocument11 pagesCost Accounting and Management AccountingCollins AbereNo ratings yet
- Accounting Assignment 3 - FinalDocument21 pagesAccounting Assignment 3 - FinalMiia SiddiqiNo ratings yet
- Chapter 1&2 - Questions and AnswerDocument16 pagesChapter 1&2 - Questions and AnswerPro TenNo ratings yet
- Equity Securities - Answer Key PDFDocument5 pagesEquity Securities - Answer Key PDFVikaNo ratings yet
- Ross 9e FCF SMLDocument425 pagesRoss 9e FCF SMLAlmayaya100% (1)
- Making Investment Decisions With The Net Present Value Rule: Principles of Corporate FinanceDocument25 pagesMaking Investment Decisions With The Net Present Value Rule: Principles of Corporate FinanceSalehEdelbiNo ratings yet
- Written AssignmentDocument3 pagesWritten AssignmentParul TandonNo ratings yet
- Declare Time Variable Using VAR in Stata: How To Perform Granger Causality Test in STATA?Document1 pageDeclare Time Variable Using VAR in Stata: How To Perform Granger Causality Test in STATA?AselNo ratings yet
- SJCC Final Exam Soc Sci 2Document1 pageSJCC Final Exam Soc Sci 2Jonalyn LodorNo ratings yet
- Artical Review For WeekendDocument18 pagesArtical Review For WeekendHabte DebeleNo ratings yet
- Chapter 14 PDFDocument27 pagesChapter 14 PDFRobby HakamNo ratings yet
- Value Chain Management Capability A Complete Guide - 2020 EditionFrom EverandValue Chain Management Capability A Complete Guide - 2020 EditionNo ratings yet
- Speaking Stata: Making It Count: 7, Number 1, Pp. 117-130Document14 pagesSpeaking Stata: Making It Count: 7, Number 1, Pp. 117-130Mariia SungatullinaNo ratings yet
- An Introduction To JASP: A Free and User-Friendly Statistics PackageDocument13 pagesAn Introduction To JASP: A Free and User-Friendly Statistics PackageGianni BasileNo ratings yet
- Module 2 Introduction To SPSS - WordDocument17 pagesModule 2 Introduction To SPSS - WordJordine UmayamNo ratings yet
- Spss Coursework HelpDocument8 pagesSpss Coursework Helpfzdpofajd100% (2)
- Lab1-1 - Basic Data ProcessingDocument16 pagesLab1-1 - Basic Data ProcessingAlan SerranoNo ratings yet
- (Ebook PDF) - Statistics. .Spss - TutorialDocument15 pages(Ebook PDF) - Statistics. .Spss - TutorialMASAIER4395% (19)
- Experimental WorksheetDocument8 pagesExperimental WorksheetAlPHA NiNjANo ratings yet
- Pcs - 2Document2 pagesPcs - 28n4wfs4zzbNo ratings yet
- Getting Started With IBM SPSS Statistics For Windows: A Training Manual For BeginnersDocument56 pagesGetting Started With IBM SPSS Statistics For Windows: A Training Manual For Beginnersbenben08No ratings yet
- Department of Education: Republic of The PhilippinesDocument2 pagesDepartment of Education: Republic of The PhilippinesGlenn OthersNo ratings yet
- Raegel Jones C. Besin Janella CZL R. Lastimosa Elaine Kate L. Jocson Ahbie Grace B. Gendive Keziah Marie H. BajaroDocument27 pagesRaegel Jones C. Besin Janella CZL R. Lastimosa Elaine Kate L. Jocson Ahbie Grace B. Gendive Keziah Marie H. BajaroGlenn OthersNo ratings yet
- Detailed Research Lesson Plan Grade Level Quarter/Domain Week &day No. Page NoDocument10 pagesDetailed Research Lesson Plan Grade Level Quarter/Domain Week &day No. Page NoGlenn OthersNo ratings yet
- ANNEX N - Psychosocial TrainingDocument1 pageANNEX N - Psychosocial TrainingGlenn OthersNo ratings yet
- Lecture 8Document22 pagesLecture 8AritroNo ratings yet
- AP Statistics Problems #13Document2 pagesAP Statistics Problems #13ldlewisNo ratings yet
- R Handout Statistics and Data Analysis Using RDocument91 pagesR Handout Statistics and Data Analysis Using Rtele6No ratings yet
- Levelling of Geochemical Surveys - GrunskyDocument44 pagesLevelling of Geochemical Surveys - GrunskyedNo ratings yet
- Computer Simulations of Optical Turbulence in The Weak - and Strong - Scattering RegimeDocument10 pagesComputer Simulations of Optical Turbulence in The Weak - and Strong - Scattering RegimePippoNo ratings yet
- Advanced StatisticsDocument40 pagesAdvanced StatisticsKarlstein Foñollera DiaoNo ratings yet
- Construction and Building Materials: A.C. Raposeiras, J. Rojas-Mora, E. Piffaut, D. Movilla-Quesada, D. Castro-FresnoDocument10 pagesConstruction and Building Materials: A.C. Raposeiras, J. Rojas-Mora, E. Piffaut, D. Movilla-Quesada, D. Castro-FresnoAdelin StirbNo ratings yet
- Lecture 2-Statistics The Normal Distribution and The Central Limit TheoremDocument73 pagesLecture 2-Statistics The Normal Distribution and The Central Limit TheoremDstormNo ratings yet
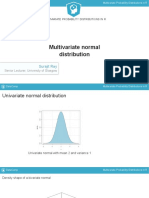
- Multivariate Normal DistributionDocument51 pagesMultivariate Normal DistributionMarvi HarsiNo ratings yet
- 04 Mahalanobis Distance in R MV PDFDocument9 pages04 Mahalanobis Distance in R MV PDFEduardoPacaNo ratings yet
- Bootstrap Regression With R: Histogram of KPLDocument5 pagesBootstrap Regression With R: Histogram of KPLWinda Mabruroh ZaenalNo ratings yet
- StatLearning2r PDFDocument267 pagesStatLearning2r PDFBruno CasellaNo ratings yet
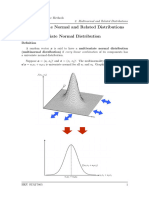
- Chap2 Multivariate Normal and Related DistributionsDocument18 pagesChap2 Multivariate Normal and Related DistributionschanpeinNo ratings yet
- Statgraphics Centurion XV User Manual: Statpoint, IncDocument295 pagesStatgraphics Centurion XV User Manual: Statpoint, IncHugo LopezNo ratings yet
- Waste Water Flow Rates SectionDocument14 pagesWaste Water Flow Rates SectionChiranjaya HulangamuwaNo ratings yet
- MTPDF3 - Main Module PDF Hydropower EngineeringDocument35 pagesMTPDF3 - Main Module PDF Hydropower EngineeringEunnice PanaliganNo ratings yet
- Assignment No:-01: Name:-Snehal - Satyavrat.Yadav ROLL - NO:-42Document12 pagesAssignment No:-01: Name:-Snehal - Satyavrat.Yadav ROLL - NO:-42poojaNo ratings yet
- Be Computer Engineering Ai, DS, ML Third Year Te Semester 5 6 Rev 2019 C SchemeDocument81 pagesBe Computer Engineering Ai, DS, ML Third Year Te Semester 5 6 Rev 2019 C SchemegopalprajapatimovieNo ratings yet
- At-Site and Regional Flood Frequency Analysis of The Upper Awash Sub Basin in The Ethiopian PlateauDocument15 pagesAt-Site and Regional Flood Frequency Analysis of The Upper Awash Sub Basin in The Ethiopian PlateauRahulKumarSinghNo ratings yet
- MVN Packages RDocument9 pagesMVN Packages RRifki MaulanaNo ratings yet
- Testing For Normality Using SPSSDocument12 pagesTesting For Normality Using SPSSGazal GuptaNo ratings yet
- Unit 4Document30 pagesUnit 4Anirudh RNo ratings yet
- Introduction To RDocument20 pagesIntroduction To Rseptian_bbyNo ratings yet
- 2012 - Questionnaire Evaluation FactAnalysis PDFDocument11 pages2012 - Questionnaire Evaluation FactAnalysis PDFLuis AnunciacaoNo ratings yet
- FIN 5309 Homework 9 Solution Fall 2018: InstructionsDocument16 pagesFIN 5309 Homework 9 Solution Fall 2018: InstructionsOntime BestwritersNo ratings yet
- Test For Normality PDFDocument30 pagesTest For Normality PDFShejj PeterNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Fundamentals of Probability, Random Processes and StatisticsDocument38 pagesFundamentals of Probability, Random Processes and Statisticsab cNo ratings yet
- Arvind 2017 IOP Conf. Ser. Earth Environ. Sci. 80 012067Document10 pagesArvind 2017 IOP Conf. Ser. Earth Environ. Sci. 80 012067wileNo ratings yet