0% found this document useful (0 votes)
51 viewsUsing LINEST in Excel
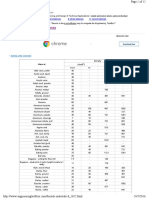
This document discusses using the LINEST function in Excel to fit polynomials to data by generating columns for X, X^2, X^3, etc. and entering them into the LINEST function. It provides an example of fitting both quadratic and linear polynomials to sample data and interpreting the results. It also notes that the Analysis Toolpak can be used for polynomial regression. Finally, it discusses some biases that exist in measures like R-squared and the Pearson correlation coefficient.
Uploaded by
______.________Copyright
© © All Rights Reserved
Available Formats
Download as XLS, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
51 viewsUsing LINEST in Excel
This document discusses using the LINEST function in Excel to fit polynomials to data by generating columns for X, X^2, X^3, etc. and entering them into the LINEST function. It provides an example of fitting both quadratic and linear polynomials to sample data and interpreting the results. It also notes that the Analysis Toolpak can be used for polynomial regression. Finally, it discusses some biases that exist in measures like R-squared and the Pearson correlation coefficient.
Uploaded by
______.________Copyright
© © All Rights Reserved
Available Formats
Download as XLS, PDF, TXT or read online on Scribd
/ 4