0% found this document useful (0 votes)
74 viewsIntroduction To Neurons and Artificial Neural Networks
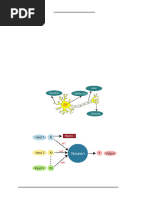
Artificial neural networks (ANNs) are composed of interconnected nodes that mimic the workings of the human brain. ANNs are made up of input, hidden, and output layers with nodes that are connected by weighted links. The nodes accept input data, perform simple math operations, and pass the results to other nodes. The network learns by adjusting the weights to minimize error between the actual and predicted outputs. Common activation functions used in ANNs include sigmoid, tanh, and ReLU, which introduce non-linearity. ANNs can learn complex patterns and perform tasks like classification and regression.
Uploaded by
Fahim MiddyaCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
74 viewsIntroduction To Neurons and Artificial Neural Networks
Artificial neural networks (ANNs) are composed of interconnected nodes that mimic the workings of the human brain. ANNs are made up of input, hidden, and output layers with nodes that are connected by weighted links. The nodes accept input data, perform simple math operations, and pass the results to other nodes. The network learns by adjusting the weights to minimize error between the actual and predicted outputs. Common activation functions used in ANNs include sigmoid, tanh, and ReLU, which introduce non-linearity. ANNs can learn complex patterns and perform tasks like classification and regression.
Uploaded by
Fahim MiddyaCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 34