Implementation of Substitution Technique: Experiment-1
Implementation of Substitution Technique: Experiment-1
Download as docx, pdf, or txt
At a glance
Powered by AI
The key takeaways are about implementing various substitution cipher techniques like the Caesar cipher, monoalphabetic cipher, and analyzing techniques like brute force and frequency analysis attacks.
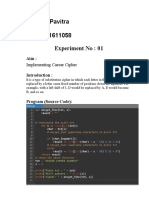
The code implements the Caesar cipher for encryption and decryption as well as a monoalphabetic cipher. It also shows a brute force attack on the Caesar cipher.
A brute force attack on the Caesar cipher tries every possible key on the ciphertext until the original plaintext is recovered. It shifts each character by the tested key and checks if it reveals an intelligible message.
You might also like
- Cryptography Lab Manual-FinalDocument36 pagesCryptography Lab Manual-FinalPraveen TPNo ratings yet
- Tutorial 2Document7 pagesTutorial 2VineetSinghNo ratings yet
- WireGuard: Next Generation Kernel Network TunnelDocument20 pagesWireGuard: Next Generation Kernel Network TunnelIanTayYiYan100% (1)
- Implementation of Substitution Technique: Experiment-1Document8 pagesImplementation of Substitution Technique: Experiment-1Sonam GuptaNo ratings yet
- Final ReportDocument27 pagesFinal ReportMihir DesaiNo ratings yet
- Ins Journal All PracsDocument19 pagesIns Journal All PracsShejal PalNo ratings yet
- Cryptographic AlgorithmDocument15 pagesCryptographic AlgorithmDainikMitraNo ratings yet
- CSS Exp1Document8 pagesCSS Exp1dhruva2322No ratings yet
- CryptographyDocument6 pagesCryptographybehailuNo ratings yet
- CSCL ReportDocument38 pagesCSCL Reportbm3573630No ratings yet
- hack N1Document4 pageshack N1panaghiotidismatthieuNo ratings yet
- Delhi Technological UniversityDocument19 pagesDelhi Technological UniversityPratham AgarwalNo ratings yet
- IS EX_1_TO_10Document35 pagesIS EX_1_TO_10ryuvraj0707No ratings yet
- Cyber Security Lab - Symmetric Key Encryption TechniquesDocument17 pagesCyber Security Lab - Symmetric Key Encryption TechniquesRama KrishnaNo ratings yet
- CNS C ManualDocument45 pagesCNS C Manualnandini230804No ratings yet
- CSS EXP1 MergedDocument55 pagesCSS EXP1 MergedVidhi ArtaniNo ratings yet
- CSB451 Ca3Document9 pagesCSB451 Ca3terminator1942013No ratings yet
- Ngo Van Thang 19 It 196Document5 pagesNgo Van Thang 19 It 196lequochuy.10112000No ratings yet
- INS File 2Document45 pagesINS File 2sanskar ojhaNo ratings yet
- CO 405 Information and Network Security Practical FileDocument47 pagesCO 405 Information and Network Security Practical FileAvneesh TyagiNo ratings yet
- CNS PDFDocument49 pagesCNS PDFhazirasultana444No ratings yet
- Security Lab RecordDocument43 pagesSecurity Lab RecordkarthikNo ratings yet
- Five Ways To Crack A Vigenere CipherDocument8 pagesFive Ways To Crack A Vigenere CipherluxidatorNo ratings yet
- Caesar Cipher Implementation in C LanguageDocument9 pagesCaesar Cipher Implementation in C LanguageBanGush KanNo ratings yet
- Cryptography File 2023 24Document26 pagesCryptography File 2023 24Abhay PratapNo ratings yet
- Practical - 1: About Caesar CipherDocument20 pagesPractical - 1: About Caesar CipherMubassir PatelNo ratings yet
- tp1 Security - IpynbDocument5 pagestp1 Security - Ipynbmonta ssarNo ratings yet
- Information Security Lab Manual PagesDocument21 pagesInformation Security Lab Manual PagesSuman pranav TuduNo ratings yet
- Information Security Lab ManualDocument79 pagesInformation Security Lab ManualSuman pranav TuduNo ratings yet
- Cryptogyaphy LabDocument85 pagesCryptogyaphy LabprathamNo ratings yet
- Lab 2Document9 pagesLab 2Aaron AbrahamNo ratings yet
- Panipat Institute of Engineering & Technology Samalkha Computer Science & Engineering DepartmentDocument36 pagesPanipat Institute of Engineering & Technology Samalkha Computer Science & Engineering Departmentramandubey69No ratings yet
- Assignment_2Document6 pagesAssignment_2Vamsi AsaNo ratings yet
- Is 1Document20 pagesIs 1chinmaynaik02No ratings yet
- Exp - No: 1 Caeser Cipher Date: AimDocument22 pagesExp - No: 1 Caeser Cipher Date: AimGnana SekharNo ratings yet
- Index: SR No. Date Practical SignDocument21 pagesIndex: SR No. Date Practical Signkaranaade103No ratings yet
- CPT LabDocument9 pagesCPT LabinduNo ratings yet
- 2021 Uam 2107Document8 pages2021 Uam 2107asimkingleNo ratings yet
- Ins FileDocument31 pagesIns Filekartikaysinghco20b446No ratings yet
- INS NewDocument14 pagesINS NewgiryahaiNo ratings yet
- CombinedDocument70 pagesCombinedchirag yadavNo ratings yet
- Implementation of Product Cipher Using Substitution and Transposition TechniqueDocument5 pagesImplementation of Product Cipher Using Substitution and Transposition TechniqueSonam GuptaNo ratings yet
- Cyber PracticalDocument8 pagesCyber PracticalPrabhakar ReddyNo ratings yet
- Encryption: To Study and Implement Columnar Transposition CipherDocument4 pagesEncryption: To Study and Implement Columnar Transposition CipherSoham PatyaneNo ratings yet
- CNS IDocument30 pagesCNS IRushil BeladiyaNo ratings yet
- CodeDocument6 pagesCodeVanshika GuptaNo ratings yet
- CSCLDocument26 pagesCSCLpravesh koiralaNo ratings yet
- CCS Practical Lab ManualDocument34 pagesCCS Practical Lab Manualrrrmovie12No ratings yet
- Experiment No: 7: Name: Rhugved Satardekar Roll No: 17141208Document4 pagesExperiment No: 7: Name: Rhugved Satardekar Roll No: 17141208Pallavi BhartiNo ratings yet
- Implement A Caesar Cipher Encryption and Decryption Algorithm For The Given Pseudo FunctionDocument8 pagesImplement A Caesar Cipher Encryption and Decryption Algorithm For The Given Pseudo FunctionNishan HamalNo ratings yet
- Practical-1: AIM: Implement A Program Which Can Decrypt The Original Message From The GivenDocument65 pagesPractical-1: AIM: Implement A Program Which Can Decrypt The Original Message From The GivenprogrammerNo ratings yet
- p2 Python ProjectDocument3 pagesp2 Python ProjectDaniella VargasNo ratings yet
- Project AlternativeDocument7 pagesProject Alternativehpj60163No ratings yet
- CSS Shruti Experiment No. 01Document6 pagesCSS Shruti Experiment No. 01ShrutiNo ratings yet
- Cryptography Lab ManualDocument18 pagesCryptography Lab ManualDhruv SanganiNo ratings yet
- Ins Lab FileDocument30 pagesIns Lab Filesanskar ojhaNo ratings yet
- Programming Project 05: Assignment OverviewDocument4 pagesProgramming Project 05: Assignment OverviewPrateekNo ratings yet
- Caesar CipherDocument12 pagesCaesar Cipherbride junior tchuensuNo ratings yet
- Is Lab ManualDocument24 pagesIs Lab ManualAbhilashPadmanabhanNo ratings yet
- Caesar CipherDocument6 pagesCaesar CipherSahilNo ratings yet
- Exp-1 DevOpsLabDocument6 pagesExp-1 DevOpsLabSonam Gupta100% (1)
- Exp 7 DevOpsLabDocument5 pagesExp 7 DevOpsLabSonam Gupta100% (1)
- Agile Processes: Scrum: - Khushboo ChaudhariDocument31 pagesAgile Processes: Scrum: - Khushboo ChaudhariSonam GuptaNo ratings yet
- Name: Sonam Gupta Roll No.: 201903015 (14) Subject: Devops LabDocument8 pagesName: Sonam Gupta Roll No.: 201903015 (14) Subject: Devops LabSonam Gupta100% (1)
- CSS AnimationsDocument18 pagesCSS AnimationsSonam GuptaNo ratings yet
- JavascriptDocument158 pagesJavascriptSonam GuptaNo ratings yet
- CH3 - Software Estimation SchedulingDocument55 pagesCH3 - Software Estimation SchedulingSonam GuptaNo ratings yet
- Implementation of Product Cipher Using Substitution and Transposition TechniqueDocument8 pagesImplementation of Product Cipher Using Substitution and Transposition TechniqueSonam GuptaNo ratings yet
- Web Programming FundamentalsDocument105 pagesWeb Programming FundamentalsSonam GuptaNo ratings yet
- Extensible Markup LanguageDocument38 pagesExtensible Markup LanguageSonam GuptaNo ratings yet
- Implementation of Advanced Encryption Technique and Public Key EncryptionDocument10 pagesImplementation of Advanced Encryption Technique and Public Key EncryptionSonam GuptaNo ratings yet
- Implementation of Playfair Cipher: Experiment-3Document5 pagesImplementation of Playfair Cipher: Experiment-3Sonam GuptaNo ratings yet
- Implementation of Playfair Cipher: Experiment-3Document5 pagesImplementation of Playfair Cipher: Experiment-3Sonam GuptaNo ratings yet
- Implementation of Product Cipher Using Substitution and Transposition TechniqueDocument5 pagesImplementation of Product Cipher Using Substitution and Transposition TechniqueSonam GuptaNo ratings yet
- IR Best PracticeDocument66 pagesIR Best Practicerudi paserNo ratings yet
- Cyber Security Model Question Papers 2023Document3 pagesCyber Security Model Question Papers 2023ModijiNo ratings yet
- Blockchain QADocument5 pagesBlockchain QASuman SahooNo ratings yet
- 517 Crunchyroll AccDocument44 pages517 Crunchyroll AccYugavarth ReddyNo ratings yet
- OneSpan Ebook Social Engineering Attacks Banking TransactionsDocument17 pagesOneSpan Ebook Social Engineering Attacks Banking TransactionsMugdha MNo ratings yet
- Fortiauthenticator™: User Identity Management and Single Sign-OnDocument6 pagesFortiauthenticator™: User Identity Management and Single Sign-OnDragan LončarskiNo ratings yet
- PYQ-Qs (CNS, PLC, IDB)Document12 pagesPYQ-Qs (CNS, PLC, IDB)heathcliff5792No ratings yet
- MCQ Chapter 9Document4 pagesMCQ Chapter 9technicalgamerz895No ratings yet
- CNS Lecture NotesDocument153 pagesCNS Lecture NotesMudadla.PoornimaNo ratings yet
- Instant Download Understanding Cryptography From Established Symmetric and Asymmetric Ciphers To Post Quantum Algorithms 2nd Edition Christof Paar - Jan Pelzl - Tim Güneysu PDF All ChapterDocument84 pagesInstant Download Understanding Cryptography From Established Symmetric and Asymmetric Ciphers To Post Quantum Algorithms 2nd Edition Christof Paar - Jan Pelzl - Tim Güneysu PDF All Chapterdzakpomarjz100% (10)
- Abstract. This Paper Presents A 64-Bit Lightweight Block Cipher TWINEDocument24 pagesAbstract. This Paper Presents A 64-Bit Lightweight Block Cipher TWINEاليزيد بن توهاميNo ratings yet
- How To AD LDAP ConfigurationDocument3 pagesHow To AD LDAP ConfigurationRaveesh P NairNo ratings yet
- After Work For Home 28-05-20Document32 pagesAfter Work For Home 28-05-20NamloveySmileNo ratings yet
- Resultat SnusbaseDocument3 pagesResultat Snusbasemanku.zt0No ratings yet
- Car Insurance Management System ERDDocument1 pageCar Insurance Management System ERDFares MohamedNo ratings yet
- Data Privacy and SecurityDocument13 pagesData Privacy and Securityrityalonare21No ratings yet
- Network SecurityDocument49 pagesNetwork Securityhidiyah marthiyaNo ratings yet
- SR Computer Instructor Posting OrderDocument7 pagesSR Computer Instructor Posting OrderGaurav KumarNo ratings yet
- 10 Cloud Risks CISO WhitepaperDocument7 pages10 Cloud Risks CISO WhitepapersumairianNo ratings yet
- SOLUTION Question 1 - LLDocument1 pageSOLUTION Question 1 - LLypyccypyNo ratings yet
- Information Technology - Remote Access - SOPDocument4 pagesInformation Technology - Remote Access - SOPKaitlyn PawlowskiNo ratings yet
- WhatsApp Security WhitepaperDocument10 pagesWhatsApp Security WhitepaperCrystal ClarkNo ratings yet
- StoryresposeindiaDocument27 pagesStoryresposeindiaYenyenNo ratings yet
- Hack2Secure Web Application Security Testing Workshop Reference GuideDocument9 pagesHack2Secure Web Application Security Testing Workshop Reference GuideJavvedNo ratings yet
- Screen Name Test Title Test Script # Test Objectives:: Login Page LM Test Functionality of Login LM Access LP - LM - 001Document8 pagesScreen Name Test Title Test Script # Test Objectives:: Login Page LM Test Functionality of Login LM Access LP - LM - 001sadim22No ratings yet
- SecurityDocument364 pagesSecurityalbertirtyNo ratings yet
- Create Your Google Account: One Account Is All You NeedDocument2 pagesCreate Your Google Account: One Account Is All You NeedTerra BrettNo ratings yet
- Steganography in C++Document15 pagesSteganography in C++888chandu0% (1)
- Availaible at VTU HUB (Android App) : Module-3 Elliptic Curves, Key Management and DistributionDocument5 pagesAvailaible at VTU HUB (Android App) : Module-3 Elliptic Curves, Key Management and DistributionAdarsha SNo ratings yet