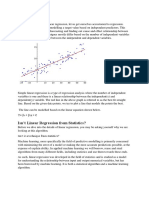
WLR
WLR
Download as doc, pdf, or txt
You might also like
- Class BSC Book Statistics All Chpter Wise NotesDocument128 pagesClass BSC Book Statistics All Chpter Wise Notesrahil saddique67% (49)
- Condition Number - WikipediaDocument7 pagesCondition Number - Wikipediatsvmpm1765No ratings yet
- Direct Linear Transformation: Practical Applications and Techniques in Computer VisionFrom EverandDirect Linear Transformation: Practical Applications and Techniques in Computer VisionNo ratings yet
- Numericke Metode U Inzenjerstvu Predavanja 2Document92 pagesNumericke Metode U Inzenjerstvu Predavanja 2TonyBarosevcicNo ratings yet
- RegressionDocument45 pagesRegressionamrutamhetre9No ratings yet
- Describe The Structure of Mathematical Model in Your Own WordsDocument10 pagesDescribe The Structure of Mathematical Model in Your Own Wordskaranpuri6No ratings yet
- Conjugate Gradient Method - WikipediaDocument15 pagesConjugate Gradient Method - WikipediawisNo ratings yet
- ModakDocument22 pagesModakflgrhnNo ratings yet
- Consistency, Stability and ConvergenceDocument4 pagesConsistency, Stability and ConvergencesaugatpandeyNo ratings yet
- Non Parametrical Estimation of The Regression Used in Economic AnalysesDocument6 pagesNon Parametrical Estimation of The Regression Used in Economic AnalysesLoredana GheorgheNo ratings yet
- Chapter 3 SummaryDocument8 pagesChapter 3 Summaryimran khanNo ratings yet
- Condition NumberDocument4 pagesCondition NumberDeep JoshiNo ratings yet
- Least Square MethodDocument2 pagesLeast Square MethodgknindrasenanNo ratings yet
- Simplex Algorithm - WikipediaDocument20 pagesSimplex Algorithm - WikipediaGalata BaneNo ratings yet
- Dependent Independent Variable (S) : Regression: What Is RegressionDocument15 pagesDependent Independent Variable (S) : Regression: What Is Regressionitsnithin_tsNo ratings yet
- Everything You Need To Know About Linear RegressionDocument19 pagesEverything You Need To Know About Linear RegressionRohit Umbare100% (1)
- Simplex AlgorithmDocument10 pagesSimplex AlgorithmGetachew MekonnenNo ratings yet
- Numerical Analysis PDFDocument15 pagesNumerical Analysis PDFaauppalNo ratings yet
- Unit1 - Data Science - SPPUDocument15 pagesUnit1 - Data Science - SPPUburgulameyNo ratings yet
- An Introduction To Gradient Descent and Linear RegressionDocument8 pagesAn Introduction To Gradient Descent and Linear RegressionabolfazlNo ratings yet
- Solution of Discretized EquationsDocument26 pagesSolution of Discretized EquationsSandeep KadamNo ratings yet
- A) The Least-Squares MethodDocument19 pagesA) The Least-Squares MethodKalyan MajjiNo ratings yet
- Models PDFDocument86 pagesModels PDFAnkit KumarNo ratings yet
- A3 110006223Document7 pagesA3 110006223Samuel DharmaNo ratings yet
- Curve FittingDocument5 pagesCurve Fittinguser2127No ratings yet
- UNIt-3 TYDocument67 pagesUNIt-3 TYPrathmesh Mane DeshmukhNo ratings yet
- Advice: sciences/business/economics/kit-baum-workshops/Bham13P4slides PDFDocument11 pagesAdvice: sciences/business/economics/kit-baum-workshops/Bham13P4slides PDFAhmad Bello DogarawaNo ratings yet
- ML - Mid2Document24 pagesML - Mid2cutevenkyputtiNo ratings yet
- Bs (It) Al Habib Group of Colleges: Assignment AlgorithmDocument5 pagesBs (It) Al Habib Group of Colleges: Assignment AlgorithmusmanaltafNo ratings yet
- Isn't Linear Regression From Statistics?Document4 pagesIsn't Linear Regression From Statistics?umang rajanNo ratings yet
- Everything You Need To Know About Linear RegressionDocument19 pagesEverything You Need To Know About Linear RegressiondbsgloballoNo ratings yet
- Sparse Implementation of Revised Simplex Algorithms On Parallel ComputersDocument8 pagesSparse Implementation of Revised Simplex Algorithms On Parallel ComputersKaram SalehNo ratings yet
- 1306 4622Document4 pages1306 4622sudhialamandaNo ratings yet
- Aravind Rangamreddy 500195259 cs3Document8 pagesAravind Rangamreddy 500195259 cs3Aravind Kumar ReddyNo ratings yet
- NuMeths (Unit1)Document34 pagesNuMeths (Unit1)kathrin_jazz26No ratings yet
- Linear Programming and The Simplex Method: David GaleDocument6 pagesLinear Programming and The Simplex Method: David GaleRichard Canar PerezNo ratings yet
- DA Unit-3Document11 pagesDA Unit-3KaataRanjithkumarNo ratings yet
- Gaussian IntegralDocument7 pagesGaussian IntegralChristopher MendezNo ratings yet
- Lec28 CFD SreenivasJayantiDocument15 pagesLec28 CFD SreenivasJayantiElhadramy AhmedNo ratings yet
- Graphical Analysis and Errors - MBLDocument7 pagesGraphical Analysis and Errors - MBLclaimstudent3515No ratings yet
- Linear Least SquaresDocument10 pagesLinear Least Squareswatson191No ratings yet
- Linear Regression in Machine Learning MY NOTESDocument21 pagesLinear Regression in Machine Learning MY NOTESdakc.cseNo ratings yet
- Describe in Brief Different Types of Regression AlgorithmsDocument25 pagesDescribe in Brief Different Types of Regression AlgorithmsRajeshree JadhavNo ratings yet
- Simple Linear RegressionDocument25 pagesSimple Linear RegressionhelderfoxNo ratings yet
- Numerical Methods II - Polynomial ApproximationDocument91 pagesNumerical Methods II - Polynomial ApproximationEmil HDNo ratings yet
- Numerical IntegrationDocument8 pagesNumerical Integration丨ㄒ丂ᐯ乇ᗪ卂几ㄒNo ratings yet
- Advanced Linear Programming: DR R.A.Pendavingh September 6, 2004Document82 pagesAdvanced Linear Programming: DR R.A.Pendavingh September 6, 2004Ahmed GoudaNo ratings yet
- Linear - Regression & Evaluation MetricsDocument31 pagesLinear - Regression & Evaluation Metricsreshma acharyaNo ratings yet
- Summary of The Reflection Method For The Numerical Solution of Linear Systems AstDocument3 pagesSummary of The Reflection Method For The Numerical Solution of Linear Systems AstLEGENDARY uploaderNo ratings yet
- Assignment-Based Subjective Questions/AnswersDocument3 pagesAssignment-Based Subjective Questions/AnswersrahulNo ratings yet
- Numerical AnalysisDocument7 pagesNumerical Analysisoxyde blogyNo ratings yet
- New Microsoft Word Document (5) تقرير تحليلات 11 PDFDocument16 pagesNew Microsoft Word Document (5) تقرير تحليلات 11 PDFمحمد مNo ratings yet
- Assignment-Based Subjective Questions/AnswersDocument3 pagesAssignment-Based Subjective Questions/AnswersrahulNo ratings yet
- Module 1 NotesDocument73 pagesModule 1 Notes20EUIT173 - YUVASRI KB100% (1)
- RegressionDocument9 pagesRegressionRaghavendra SwamyNo ratings yet
- Machine Learning AlgorithmDocument20 pagesMachine Learning AlgorithmSiva Gana100% (2)
- Understanding Vector Calculus: Practical Development and Solved ProblemsFrom EverandUnderstanding Vector Calculus: Practical Development and Solved ProblemsNo ratings yet
- Bundle Adjustment: Optimizing Visual Data for Precise ReconstructionFrom EverandBundle Adjustment: Optimizing Visual Data for Precise ReconstructionNo ratings yet
- SPSS IcaDocument1 pageSPSS IcaYunikeNo ratings yet
- AAMS2613 Tut 1-9Document18 pagesAAMS2613 Tut 1-9TzionNo ratings yet
- BRM CH 20Document20 pagesBRM CH 20Adeniyi AleseNo ratings yet
- Isye 6421: Biostatistics: Analysis of Variance (Anova) Pairwise Comparison For Confidence IntervalsDocument10 pagesIsye 6421: Biostatistics: Analysis of Variance (Anova) Pairwise Comparison For Confidence IntervalsoutlierNo ratings yet
- Quantitative Analysis in FootballDocument19 pagesQuantitative Analysis in FootballTamarai Selvi ArumugamNo ratings yet
- Math 301 CH 9 Estimation (One and Two SamplesDocument42 pagesMath 301 CH 9 Estimation (One and Two SamplesJustice LeagueNo ratings yet
- Combined AnalysisDocument7 pagesCombined AnalysisKuthubudeen T MNo ratings yet
- Data Preparation & Descriptive Statistics: Oscar Torres-ReynaDocument50 pagesData Preparation & Descriptive Statistics: Oscar Torres-ReynaOmar HabibNo ratings yet
- poLCA An R Package For Polytomous Variable LatentDocument29 pagespoLCA An R Package For Polytomous Variable LatentBluedenWaveNo ratings yet
- Paired T-Test: A Project Report OnDocument19 pagesPaired T-Test: A Project Report OnTarun kumarNo ratings yet
- HSC - Finance Banking and Insurance 1Document4 pagesHSC - Finance Banking and Insurance 1Khokon AhmedNo ratings yet
- Passing-Bablok Regression For Method ComparisonDocument9 pagesPassing-Bablok Regression For Method Comparisondata4.phtNo ratings yet
- Empcode First Name Last Name Dept Region - Code Branch Hiredate SalaryDocument23 pagesEmpcode First Name Last Name Dept Region - Code Branch Hiredate SalaryAbhinav srivastavaNo ratings yet
- Lecture Plan BBA504ADocument2 pagesLecture Plan BBA504ASayan MajumderNo ratings yet
- Lecture 4 PDFDocument9 pagesLecture 4 PDFQuoc KhanhNo ratings yet
- VAR Models With Exogenous VariablesDocument6 pagesVAR Models With Exogenous VariablesAbhishek PuriNo ratings yet
- Lampiran 4 (Output SPSS)Document14 pagesLampiran 4 (Output SPSS)rosmeini banureaNo ratings yet
- Jurnal PEM 6Document17 pagesJurnal PEM 6Raghnal FayzalNo ratings yet
- Point Estimation ExercisesDocument7 pagesPoint Estimation ExercisesJulius Vai100% (1)
- Review Class 101 4th QTRDocument56 pagesReview Class 101 4th QTRAbraham Del CastilloNo ratings yet
- Assignment 2Document3 pagesAssignment 2MubynAfiqNo ratings yet
- Calculating BetaDocument5 pagesCalculating BetajhonNo ratings yet
- Crude Analysis of SASDocument6 pagesCrude Analysis of SASMark AwNo ratings yet
- Class 1 - Descripritive StatisticsDocument46 pagesClass 1 - Descripritive StatisticsBharat ThapaNo ratings yet
- Solutions: 10-601 Machine Learning, Midterm Exam: Spring 2008 SolutionsDocument8 pagesSolutions: 10-601 Machine Learning, Midterm Exam: Spring 2008 Solutionsreshma khemchandaniNo ratings yet
- Group Data MeanDocument9 pagesGroup Data MeanAlexis OrganisNo ratings yet
- Department of Education: Republic of The PhilippinesDocument7 pagesDepartment of Education: Republic of The Philippinesadith.mangaronNo ratings yet
- STATISTICS Quarter 4 LAS 4Document4 pagesSTATISTICS Quarter 4 LAS 4Ezracel BallerasNo ratings yet