0% found this document useful (0 votes)
53 viewsSteps of Implementation of A GLM
This document discusses implementing a generalized linear model (GLM) in 5 steps:
1. Understand the data through descriptive statistics, distributions, relationships between variables, and feature engineering.
2. Preprocess the data by handling missing values, encoding categories, scaling variables, and splitting into training and test sets.
3. Choose the appropriate GLM family based on the response variable distribution.
4. Train the GLM model using a library like statsmodels.
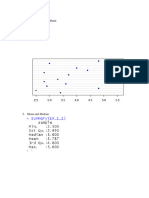
5. Evaluate the trained model using error metrics like MAE, RMSE, and R-squared and by plotting residuals.
Uploaded by
Paul WattellierCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
53 viewsSteps of Implementation of A GLM
This document discusses implementing a generalized linear model (GLM) in 5 steps:
1. Understand the data through descriptive statistics, distributions, relationships between variables, and feature engineering.
2. Preprocess the data by handling missing values, encoding categories, scaling variables, and splitting into training and test sets.
3. Choose the appropriate GLM family based on the response variable distribution.
4. Train the GLM model using a library like statsmodels.
5. Evaluate the trained model using error metrics like MAE, RMSE, and R-squared and by plotting residuals.
Uploaded by
Paul WattellierCopyright
© © All Rights Reserved
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 8