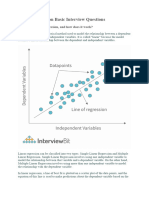
Econometrics
Econometrics
Download as pdf or txt
You might also like
- ITAE002Document10 pagesITAE002Nageshwar Singh0% (1)
- A Survey of Machine Learning Models For Financial Time Series ForecastingDocument18 pagesA Survey of Machine Learning Models For Financial Time Series Forecastingmarcmyomyint1663No ratings yet
- Business Statistics: Fourth Canadian EditionDocument33 pagesBusiness Statistics: Fourth Canadian EditionTaron AhsanNo ratings yet
- The Role of Planning and Forcasting in Business OrganizationDocument73 pagesThe Role of Planning and Forcasting in Business Organizationmuriski4live_174951087% (15)
- Multivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6From EverandMultivariate Analysis – The Simplest Guide in the Universe: Bite-Size Stats, #6No ratings yet
- 5) Multiple RegressionDocument8 pages5) Multiple RegressionSumit Mudi100% (1)
- Ba ReportingDocument3 pagesBa ReportingLea PascoNo ratings yet
- Linear Regression. ComDocument13 pagesLinear Regression. ComHamida patinoNo ratings yet
- Regression Analysis PresentationDocument52 pagesRegression Analysis PresentationKinza Saher BasraNo ratings yet
- Regression and ClassificationDocument26 pagesRegression and ClassificationDebasree RoyNo ratings yet
- BA3-4-5modulesDocument258 pagesBA3-4-5modulesmonikagowda.aNo ratings yet
- Multivariate Research AssignmentDocument6 pagesMultivariate Research AssignmentTari BabaNo ratings yet
- Income TaxDocument9 pagesIncome TaxDeepshikha SonberNo ratings yet
- Missing Value TreatmentDocument22 pagesMissing Value TreatmentrphmiNo ratings yet
- Model DevelopmentDocument80 pagesModel Developmentniti guptaNo ratings yet
- Data Analytics-11Document23 pagesData Analytics-11shrihariNo ratings yet
- Data ExplorationDocument23 pagesData ExplorationShivansh GhelaniNo ratings yet
- Simple and Multiple Linear RegressionDocument6 pagesSimple and Multiple Linear Regressionsuparshjain63No ratings yet
- A Guide To Data ExplorationDocument20 pagesA Guide To Data Explorationmike110*No ratings yet
- UNIT II RegressionDocument59 pagesUNIT II RegressionAshish ChaudharyNo ratings yet
- DS Unit-IvDocument34 pagesDS Unit-IvKusuma KorlamNo ratings yet
- Econometrics 2Document27 pagesEconometrics 2Anunay ChoudharyNo ratings yet
- Correlation of StatisticsDocument6 pagesCorrelation of StatisticsHans Christer RiveraNo ratings yet
- A Comprehensive Guide To Data Exploration: Steps of Data Exploration and Preparation Missing Value TreatmentDocument8 pagesA Comprehensive Guide To Data Exploration: Steps of Data Exploration and Preparation Missing Value Treatmentsnreddy b100% (2)
- regressionDocument7 pagesregressionjales34489No ratings yet
- Unit 3 Research MethodsDocument16 pagesUnit 3 Research Methodssruthyanand.lvNo ratings yet
- Regression AnalysisDocument11 pagesRegression AnalysisAvanija100% (2)
- Thesis Linear RegressionDocument5 pagesThesis Linear Regressionmelissabuckleyomaha100% (2)
- Notes StatsDocument8 pagesNotes StatsHira AliNo ratings yet
- Unit 2 DaDocument31 pagesUnit 2 Daitsrawat69No ratings yet
- ida unit-3.rtfDocument34 pagesida unit-3.rtfLakshmi GanjiNo ratings yet
- Data Exploration & VisualizationDocument23 pagesData Exploration & Visualizationdivya kolluriNo ratings yet
- Econometrics Board QuestionsDocument11 pagesEconometrics Board QuestionsSushwet AmatyaNo ratings yet
- Linear Regression Basic Interview QuestionsDocument36 pagesLinear Regression Basic Interview Questionsayush sainiNo ratings yet
- Econometrics ProjectDocument17 pagesEconometrics ProjectAkash ChoudharyNo ratings yet
- Data Mining TechnicalDocument45 pagesData Mining TechnicalbhaveshNo ratings yet
- Regression Analysis SPSS Natasha LatifDocument7 pagesRegression Analysis SPSS Natasha Latiflatif_996872197100% (1)
- BRM Unit 4 ExtraDocument10 pagesBRM Unit 4 Extraprem nathNo ratings yet
- What Is Regression AnalysisDocument18 pagesWhat Is Regression Analysisnagina hidayatNo ratings yet
- Examining Relationships in Quantitative ResearchDocument9 pagesExamining Relationships in Quantitative ResearchKomal RahimNo ratings yet
- 8614 2nd AssignmentDocument12 pages8614 2nd AssignmentAQSA AQSANo ratings yet
- Chapter 10 Multiple RegressionDocument43 pagesChapter 10 Multiple RegressionEslam FahmyNo ratings yet
- A Comprehensive Guide To Data ExplorationDocument18 pagesA Comprehensive Guide To Data Explorationbobby100% (1)
- Identifying The Most Important Independent Variables in Regression Models - Statistics by JimDocument8 pagesIdentifying The Most Important Independent Variables in Regression Models - Statistics by JimHector GutierrezNo ratings yet
- Business StatisticsDocument48 pagesBusiness Statisticskragul780No ratings yet
- DA2Document12 pagesDA2puneet mishraNo ratings yet
- Regression and Introduction To Bayesian NetworkDocument12 pagesRegression and Introduction To Bayesian NetworkSemmy BaghelNo ratings yet
- Educational StatisticsDocument12 pagesEducational StatisticsAsad NomanNo ratings yet
- Unidad 5 EstadisticaDocument33 pagesUnidad 5 EstadisticaAlejandro FuentesNo ratings yet
- Mod3Document50 pagesMod3vaishbhat19No ratings yet
- Social Research Methods - Statistical AnalysisDocument3 pagesSocial Research Methods - Statistical AnalysiszarsoeNo ratings yet
- IDS UNIT 5 Linear RegressionDocument27 pagesIDS UNIT 5 Linear RegressionAvyuktha RajuNo ratings yet
- unit-3 part 2 DADocument20 pagesunit-3 part 2 DANEMANI SRINITYA NEMANI SRINITYANo ratings yet
- Module 5: Multiple Regression Analysis: Tom IlventoDocument20 pagesModule 5: Multiple Regression Analysis: Tom IlventoBantiKumarNo ratings yet
- Multicollinearity Occurs When The Multiple Linear Regression Analysis Includes Several Variables That Are Significantly Correlated Not Only With The Dependent Variable But Also To Each OtherDocument11 pagesMulticollinearity Occurs When The Multiple Linear Regression Analysis Includes Several Variables That Are Significantly Correlated Not Only With The Dependent Variable But Also To Each OtherBilisummaa GeetahuunNo ratings yet
- Models AssignmentDocument43 pagesModels Assignmentsamiyeermi219No ratings yet
- Chapter Seven Multiple Regression An Introduction To Multiple Regression Performing A Multiple Regression On SpssDocument20 pagesChapter Seven Multiple Regression An Introduction To Multiple Regression Performing A Multiple Regression On SpssAkshit AroraNo ratings yet
- MLT Unit 2Document53 pagesMLT Unit 2Ashish MishraNo ratings yet
- Advanced Statistics and ProbabilityDocument37 pagesAdvanced Statistics and ProbabilityMadhu Sudhan GovinduNo ratings yet
- Thesis With Multiple Regression AnalysisDocument6 pagesThesis With Multiple Regression Analysiszehlobifg100% (2)
- 7-Multiple RegressionDocument17 pages7-Multiple Regressionحاتم سلطانNo ratings yet
- Econometrics Board QuestionsDocument13 pagesEconometrics Board QuestionsSushwet AmatyaNo ratings yet
- Q. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsDocument13 pagesQ. 1 How Is Mode Calculated? Also Discuss Its Merits and Demerits. AnsGHULAM RABANINo ratings yet
- Special Instructions / Useful Data: X X X I N PADocument17 pagesSpecial Instructions / Useful Data: X X X I N PAaishwarya asawaNo ratings yet
- Research Report ECON 340-70Document7 pagesResearch Report ECON 340-70Vinay KhandelwalNo ratings yet
- Final Examination Guide in Experimental Psychology (Research Example)Document23 pagesFinal Examination Guide in Experimental Psychology (Research Example)Ria Joy SorianoNo ratings yet
- 526-Article Text-1404-1-10-20230127Document9 pages526-Article Text-1404-1-10-20230127Anastasia UeNo ratings yet
- Total Productive Maintenance and PerformDocument10 pagesTotal Productive Maintenance and PerformTaiseer AshouriNo ratings yet
- Reliability and Validity of The T Test As A.12Document8 pagesReliability and Validity of The T Test As A.12anilrao2222No ratings yet
- Francis Galton: Galton's Law of Universal Regression Tall Fathers Less Short Fathers Was GreaterDocument18 pagesFrancis Galton: Galton's Law of Universal Regression Tall Fathers Less Short Fathers Was GreaterNavyashree B MNo ratings yet
- StataDocument14 pagesStataDiego RodriguezNo ratings yet
- HHHHHHDocument10 pagesHHHHHHAnjali patelNo ratings yet
- Assignment 3Document15 pagesAssignment 31921 Priya100% (1)
- Job Boredom and Its Correlates in 87 Finnish OrganizationsDocument8 pagesJob Boredom and Its Correlates in 87 Finnish OrganizationsVakis CharalampousNo ratings yet
- Linear RegressionDocument30 pagesLinear RegressionMinh Hứa HảiNo ratings yet
- 1850928928531-535 - H. M. Nafees - SS - UET - PAIDDocument5 pages1850928928531-535 - H. M. Nafees - SS - UET - PAIDEva BagaNo ratings yet
- Assignment6.1 DataMining Part2 Multiple Linear RegressionDocument8 pagesAssignment6.1 DataMining Part2 Multiple Linear Regressiondalo835100% (1)
- Group 8 - Sales Forecast AssignmentDocument7 pagesGroup 8 - Sales Forecast AssignmentsarathNo ratings yet
- Regression ModelDocument26 pagesRegression ModelkhadarcabdiNo ratings yet
- 04 Logistic RegressionDocument46 pages04 Logistic RegressionKHUSHI JAINNo ratings yet
- Transportation Planning Process: CE - 751, SLD, Class Notes, Fall 2006, IIT BombayDocument38 pagesTransportation Planning Process: CE - 751, SLD, Class Notes, Fall 2006, IIT BombayJohn DalidaNo ratings yet
- Article Review 1 EngDocument30 pagesArticle Review 1 EngCecilia FauziahNo ratings yet
- wTlkI0jOyvDocument168 pageswTlkI0jOyvJohn Luigi GonzalesNo ratings yet
- Multiple Regression Analysis 1Document57 pagesMultiple Regression Analysis 1Jacqueline CarbonelNo ratings yet
- Analisis Pengaruh Atribut Produk Terhadap Keputusan Pembelian Motor Suzuki Smash Di Kota Semarang Part-1Document10 pagesAnalisis Pengaruh Atribut Produk Terhadap Keputusan Pembelian Motor Suzuki Smash Di Kota Semarang Part-1Aji SetyobudiNo ratings yet
- Adaboost: An Ensemble Learning Approach For Estimating Weather-Related Outages in Distribution SystemsDocument10 pagesAdaboost: An Ensemble Learning Approach For Estimating Weather-Related Outages in Distribution Systemsmalini72No ratings yet
- Marshmallow Test 1 032429Document7 pagesMarshmallow Test 1 032429Størm ShadowsNo ratings yet
- MTH 4407 - Group 2 (Dr. Farid Zamani) - Lecture 6Document22 pagesMTH 4407 - Group 2 (Dr. Farid Zamani) - Lecture 6Auni syakirahNo ratings yet
- The Effect of Service and Food Quality On Customer Satisfaction and Hence Customer RetentionDocument12 pagesThe Effect of Service and Food Quality On Customer Satisfaction and Hence Customer RetentionAmrik SinghNo ratings yet