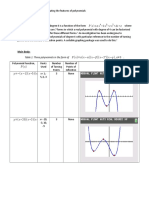
Machine Learnin
Machine Learnin
Download as pdf or txt
You might also like
- Investigating The Features of Polynomials - Online VersionDocument8 pagesInvestigating The Features of Polynomials - Online VersionFahmi Farhan67% (3)
- K-NN (Nearest Neighbor)Document17 pagesK-NN (Nearest Neighbor)Shisir Ahmed100% (1)
- 0.1 Guilherme Marthe - Boston House Pricing ChallengeDocument15 pages0.1 Guilherme Marthe - Boston House Pricing ChallengeGuilherme Marthe100% (1)
- CS85: Data Stream Algorithms Lecture Notes, Fall 2009: Amit Chakrabarti Dartmouth CollegeDocument61 pagesCS85: Data Stream Algorithms Lecture Notes, Fall 2009: Amit Chakrabarti Dartmouth CollegearnettmoultrieNo ratings yet
- Week 3 Forecasting HomeworkDocument4 pagesWeek 3 Forecasting HomeworkMargot LaGrandNo ratings yet
- DL Lab ManualDocument35 pagesDL Lab Manuallavanya penumudi100% (1)
- Chapter 4 - Linear RegressionDocument25 pagesChapter 4 - Linear Regressionanshita100% (2)
- Cardio Screen RFDocument27 pagesCardio Screen RFThe Mind100% (1)
- ClassificationDocument37 pagesClassificationKingslin Rm100% (1)
- Python3 CheatsheetDocument6 pagesPython3 CheatsheetLiwj100% (1)
- Analysing Ad BudgetDocument4 pagesAnalysing Ad BudgetSrikanth100% (1)
- Outliers, Hypothesis and Natural Language ProcessingDocument7 pagesOutliers, Hypothesis and Natural Language Processingsubhajitbasak001100% (1)
- Essential Python Cheat Sheet: SschaubDocument11 pagesEssential Python Cheat Sheet: SschaubOusmane Diamari100% (1)
- Charmi Shah 20bcp299 Lab2Document7 pagesCharmi Shah 20bcp299 Lab2Princy100% (1)
- 0.1 Stock DataDocument4 pages0.1 Stock Datayogesh patil100% (1)
- Assignment10 4Document3 pagesAssignment10 4dash100% (1)
- Lab7.ipynb - ColaboratoryDocument5 pagesLab7.ipynb - ColaboratoryPRAGASM PROG100% (1)
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- IRIS BPNN - Ipynb - ColaboratoryDocument4 pagesIRIS BPNN - Ipynb - Colaboratoryrwn data100% (1)
- 01-Introduction Machine LearningDocument48 pages01-Introduction Machine LearningAli Don100% (1)
- SVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceDocument28 pagesSVM (Support Vector Machine) For Classification - by Aditya Kumar - Towards Data ScienceZuzana W100% (1)
- 3 Confussion Matrix Hasil Modelling OKDocument8 pages3 Confussion Matrix Hasil Modelling OKArman Maulana Muhtar100% (1)
- Lab 3. Linear Regression 230223Document7 pagesLab 3. Linear Regression 230223ruso100% (1)
- SQL Cheat SheetDocument44 pagesSQL Cheat Sheetviany lepro100% (1)
- ML - LAB - 7 - Jupyter NotebookDocument7 pagesML - LAB - 7 - Jupyter Notebooksuman100% (1)
- Bootstrap PowerpointDocument10 pagesBootstrap PowerpointJose C Beraun Tapia100% (1)
- Actividad Semana 4 - Jupyter NotebookDocument7 pagesActividad Semana 4 - Jupyter NotebookM. Eugenia Barrios100% (1)
- Taxi Trips Analysis Project 1682332303Document28 pagesTaxi Trips Analysis Project 1682332303mohit c-35100% (2)
- Sales ForecastingDocument10 pagesSales ForecastingSharath Shetty100% (1)
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (2)
- Linear - RegressionDocument39 pagesLinear - Regressionhowgibaa100% (1)
- Unit V - Classification and Prediction 2020-21Document68 pagesUnit V - Classification and Prediction 2020-21rambabudugyani100% (1)
- Regressao Linear Simples - Ipynb - ColaboratoryDocument2 pagesRegressao Linear Simples - Ipynb - ColaboratoryGestão Financeira Fatec Bragança100% (1)
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- ML0101EN Clas Logistic Reg Churn Py v1Document13 pagesML0101EN Clas Logistic Reg Churn Py v1banicx100% (1)
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Chapter-3-Linear Models For RegressionDocument61 pagesChapter-3-Linear Models For Regressionlongfei zhang100% (1)
- XG Boost PDFDocument3 pagesXG Boost PDFIVAN ALVARO TORRES ROBLES100% (1)
- Importing Libraries: Import As Import As Import As From Import As From Import From Import ImportDocument11 pagesImporting Libraries: Import As Import As Import As From Import As From Import From Import Importharishr2494100% (1)
- A) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsDocument6 pagesA) What Is Motivation Behind Ensemble Methods? Give Your Answer in Probabilistic TermsHassan Saddiqui100% (1)
- Presentation GPT 4Document25 pagesPresentation GPT 4Francisco García100% (1)
- CS550 Regression Aug12Document63 pagesCS550 Regression Aug12dipsresearch100% (1)
- Logistics RegressionDocument5 pagesLogistics RegressionNazakat ali100% (1)
- HW1Document8 pagesHW1Anonymous fXSlye100% (1)
- Introduction To Scikit LearnDocument108 pagesIntroduction To Scikit LearnRaiyan Zannat100% (1)
- WeatherforecastingDocument10 pagesWeatherforecastingLoser To Winner100% (1)
- Bagging, BoostingDocument32 pagesBagging, Boostinglassijassi100% (1)
- Machine Learning and Neural Networks: Riccardo RizzoDocument113 pagesMachine Learning and Neural Networks: Riccardo RizzoRamakrishnaRao Soogoori100% (1)
- TP RegressionDocument1 pageTP RegressionMOHAMED EL BACHIR BERRIOUA100% (1)
- Everything You Need To Know About Linear RegressionDocument19 pagesEverything You Need To Know About Linear RegressionRohit Umbare100% (1)
- Loading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDocument8 pagesLoading The Dataset: First We Load The Dataset and Find Out The Number of Columns, Rows, NULL Values, EtcDivyani Chavan100% (1)
- CS464 Ch9 LinearRegressionDocument43 pagesCS464 Ch9 LinearRegressionOnur Asım İlhan100% (1)
- Ensemble MethodsDocument15 pagesEnsemble Methodsbrm1shubha100% (1)
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- ML Unit1 PDFDocument36 pagesML Unit1 PDFMohanraj Pramanathan100% (1)
- Fnal+Report Advance+StatisticsDocument44 pagesFnal+Report Advance+StatisticsPranav Viswanathan100% (1)
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- 8 Best Python Cheat Sheets For Beginners and Intermediate LearnersDocument13 pages8 Best Python Cheat Sheets For Beginners and Intermediate LearnersJoseph Jung100% (1)
- BookDocument480 pagesBookNaorem Sing100% (1)
- Jntuk R20 ML Unit-IiiDocument21 pagesJntuk R20 ML Unit-IiiMahesh100% (1)
- ML Lect1Document51 pagesML Lect1physics lover100% (1)
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- ACCT-4103 Mid PreparationDocument16 pagesACCT-4103 Mid PreparationShimul HossainNo ratings yet
- Aim: To Perform 8-Bit and 16-Bit Arithmetic Operations Tool UsedDocument16 pagesAim: To Perform 8-Bit and 16-Bit Arithmetic Operations Tool UsedSanthosh RaminediNo ratings yet
- Cubic Spline in AutomotiveDocument17 pagesCubic Spline in Automotive19MCE24 Poovendhan VNo ratings yet
- 2010 TJC Prelim Paper 2 Qns Final)Document8 pages2010 TJC Prelim Paper 2 Qns Final)cjcsucksNo ratings yet
- The Disjoint Set ADTDocument67 pagesThe Disjoint Set ADTHarish ramNo ratings yet
- SLR OcrDocument28 pagesSLR OcrAradina BabuNo ratings yet
- Language Accepted by Turing MachineDocument22 pagesLanguage Accepted by Turing Machinekndnew guadeNo ratings yet
- Crackling NoiseDocument29 pagesCrackling Noisepoyiw57027No ratings yet
- Module QuestionsDocument2 pagesModule QuestionsdarshugowNo ratings yet
- MINI PROJECT NOMINAL LIST (Data Science)Document3 pagesMINI PROJECT NOMINAL LIST (Data Science)princetonNo ratings yet
- Wireless Communication Using MatlabDocument6 pagesWireless Communication Using MatlabChaitanyaVigNo ratings yet
- Updated ICISN 2024 v6Document10 pagesUpdated ICISN 2024 v6Tuyển NguyễnNo ratings yet
- Top 20 Questions PG Linear AlgebraDocument2 pagesTop 20 Questions PG Linear AlgebraRohit KumarNo ratings yet
- CISSP CramStudy Masala Guide 4 RefDocument96 pagesCISSP CramStudy Masala Guide 4 RefsashiNo ratings yet
- Math Merge-FileDocument27 pagesMath Merge-FileRed Angela DinsonNo ratings yet
- Reversing Conway's Game of Life: ProblemDocument2 pagesReversing Conway's Game of Life: ProblemGaz ArtimisNo ratings yet
- Filmtrust: Movie Recommendations Using Trust in Web-Based Social NetworksDocument5 pagesFilmtrust: Movie Recommendations Using Trust in Web-Based Social NetworkszeeshanNo ratings yet
- Multi-Label Multimodal Emotion RecognitionDocument17 pagesMulti-Label Multimodal Emotion RecognitionNexgen TechnologyNo ratings yet
- Quick HelpDocument12 pagesQuick HelpLeo TDNo ratings yet
- W.A.S.M.U.Widanaarachchi Postgraduate Institute of Science University of Peradeniya Peradeniya, Sri Lanka Csc2239@pgis - LKDocument7 pagesW.A.S.M.U.Widanaarachchi Postgraduate Institute of Science University of Peradeniya Peradeniya, Sri Lanka Csc2239@pgis - LKMalky WidanarachchiNo ratings yet
- Exercises - Logic CircuitsDocument4 pagesExercises - Logic CircuitsTeodora DanNo ratings yet
- DLL Engineering Simple Reliability Calculations: Empirical Failure RateDocument8 pagesDLL Engineering Simple Reliability Calculations: Empirical Failure RatemachinmayNo ratings yet
- Solution css223Document8 pagesSolution css223chiedzad madondoNo ratings yet
- Machine Learning Project: Problem 1Document26 pagesMachine Learning Project: Problem 1manas vikram50% (2)
- Machine Learning Engineer Nanodegree Supervised Learning Project: Finding Donors For CharityMLDocument16 pagesMachine Learning Engineer Nanodegree Supervised Learning Project: Finding Donors For CharityMLCarlos PimentelNo ratings yet
- 417 - AI - SQP Simpal PaperDocument8 pages417 - AI - SQP Simpal PaperAVN SchoolNo ratings yet
- Bee AlgorithmDocument37 pagesBee AlgorithmChu Văn Nam100% (1)