0% found this document useful (0 votes)
32 viewsAI Lab File
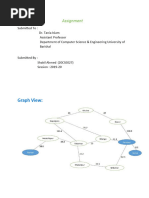
This document contains code snippets to implement various graph search algorithms like BFS, DFS, Best First Search and A* Search. It also contains code to load data from Excel and CSV files into a Pandas DataFrame and implement operations on the Titanic dataset using Pandas.
Uploaded by
RythmCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
32 viewsAI Lab File
This document contains code snippets to implement various graph search algorithms like BFS, DFS, Best First Search and A* Search. It also contains code to load data from Excel and CSV files into a Pandas DataFrame and implement operations on the Titanic dataset using Pandas.
Uploaded by
RythmCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 17