Example Import GCP To ADLS
Example Import GCP To ADLS
Download as txt, pdf, or txt
You might also like
- PLC - Process ValidationDocument10 pagesPLC - Process ValidationOscar HoyosNo ratings yet
- 05 FunctionsDocument6 pages05 FunctionsjenNo ratings yet
- Spark Job DataprocDocument4 pagesSpark Job DataprocDenys StolbovNo ratings yet
- Migrating Data From HDFS To Big QueryDocument5 pagesMigrating Data From HDFS To Big QueryMadhu SudhanNo ratings yet
- Snow SQLDocument3 pagesSnow SQLDurgesh SaindaneNo ratings yet
- Example BQ IngestionDocument5 pagesExample BQ Ingestionjenniferwright3264338No ratings yet
- MainDocument15 pagesMainvictor manuel diazNo ratings yet
- CephadmDocument105 pagesCephadmYuan ZhaoNo ratings yet
- RTL Compiler ScriptDocument4 pagesRTL Compiler Scriptmuthukumar_eee3659No ratings yet
- PilotDocument78 pagesPilotprediatechNo ratings yet
- SetupDocument3 pagesSetupluis danilo ortega caleroNo ratings yet
- Storing Data Directly From Oracle SGADocument9 pagesStoring Data Directly From Oracle SGAKaramela MelakaraNo ratings yet
- UtilsDocument12 pagesUtilsRobert RădoiNo ratings yet
- Create AKS Cluster Using TerraformDocument21 pagesCreate AKS Cluster Using TerraformSatyanarayana SureNo ratings yet
- Apache AirflowDocument69 pagesApache AirflowDilson CruzNo ratings yet
- Empacar PyDocument3 pagesEmpacar PyAFNo ratings yet
- Lstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubDocument5 pagesLstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubMuhammad Hamdani AzmiNo ratings yet
- jinkens配置Document8 pagesjinkens配置岂安No ratings yet
- 19.3.2 Data Preprocessing Di SparkDocument5 pages19.3.2 Data Preprocessing Di SparkYafi ShalihuddinNo ratings yet
- ColdboxDocument8 pagesColdboxshrikantlavhare20No ratings yet
- Yield Curve Calib 2021Document65 pagesYield Curve Calib 2021dhoang6679No ratings yet
- Lastexception 63855428737Document41 pagesLastexception 63855428737Fran BlancoNo ratings yet
- ELK ConfigDocument8 pagesELK Configraficse1971No ratings yet
- (Big Data Analytics With PySpark) (CheatSheet)Document7 pages(Big Data Analytics With PySpark) (CheatSheet)Niwahereza DanNo ratings yet
- Capital Bikeshare SQLDocument3 pagesCapital Bikeshare SQLC BNo ratings yet
- All ScriptsDocument42 pagesAll ScriptsNishkarsh SinghNo ratings yet
- Web AppvdbdhDocument14 pagesWeb AppvdbdhCode GeeksNo ratings yet
- Lastexception 63855515782Document4 pagesLastexception 63855515782Fran BlancoNo ratings yet
- Normal Abnormal Ear - Ipynb - ColabDocument10 pagesNormal Abnormal Ear - Ipynb - ColabSaddam AbdullahNo ratings yet
- Python CodeDocument5 pagesPython Codehariom_jadavNo ratings yet
- FacedetectionDocument16 pagesFacedetectionRizwan SaifiNo ratings yet
- Spark 3.0 New Features: Spark With GPU SupportDocument8 pagesSpark 3.0 New Features: Spark With GPU SupportMohammed HusseinNo ratings yet
- Ghostscript Format String Cve 2024 29510.rbDocument2 pagesGhostscript Format String Cve 2024 29510.rbTran Minh TuanNo ratings yet
- Discord Beta Banner.Document7 pagesDiscord Beta Banner.M Ilham AfandiNo ratings yet
- Banner Code PermiumDocument7 pagesBanner Code PermiumbrialnjignNo ratings yet
- Lastexception 63813906764Document21 pagesLastexception 63813906764Julia PiedraNo ratings yet
- Setup k8s With Kubeadm in AWS 2024Document12 pagesSetup k8s With Kubeadm in AWS 2024Mohamed Abdulwahid ElshafieNo ratings yet
- Lastexception 63847431586Document41 pagesLastexception 63847431586stefani40001No ratings yet
- Airtable - Ipynb - ColaboratoryDocument4 pagesAirtable - Ipynb - ColaboratoryVesselin NikovNo ratings yet
- Winrar ExploitDocument2 pagesWinrar Exploittier2meNo ratings yet
- Economist Old EditionDocument7 pagesEconomist Old EditionPiscineNo ratings yet
- 21BCP122 - Digital - Forensics - Assignment - 4a 2Document6 pages21BCP122 - Digital - Forensics - Assignment - 4a 2Patel AnujNo ratings yet
- Video Api Endpoint NDocument7 pagesVideo Api Endpoint NSatya PerabhatulaNo ratings yet
- WATS Database Export Import RecommendationDocument6 pagesWATS Database Export Import RecommendationSreekanth ReddyNo ratings yet
- Lastexception 63736300370Document72 pagesLastexception 63736300370Josefina AlonzoNo ratings yet
- SNOWPIPE-Continuous Data Loading in SnowflakeDocument5 pagesSNOWPIPE-Continuous Data Loading in Snowflakeravi.abinitNo ratings yet
- PGSQL SQLsDocument9 pagesPGSQL SQLskishore_m_kNo ratings yet
- Lastexception 63798889671Document3 pagesLastexception 63798889671Sherry DuanNo ratings yet
- Oracle RDBMS Rootkits and Other ModificationsDocument9 pagesOracle RDBMS Rootkits and Other Modificationsxedi rajNo ratings yet
- Lastexception 63743512169Document234 pagesLastexception 63743512169Josefina AlonzoNo ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Lastexception 63855458770Document6 pagesLastexception 63855458770Fran BlancoNo ratings yet
- Resque Backgroundrb: To: FromDocument30 pagesResque Backgroundrb: To: FromJames CoxNo ratings yet
- Output2Document2 pagesOutput2Laptop-Dimas-249No ratings yet
- ViernesDocument5 pagesViernescatriel lopezNo ratings yet
- Stop Burning Clients!!!: Alert ( Start!!!')Document15 pagesStop Burning Clients!!!: Alert ( Start!!!')Hung NguyenNo ratings yet
- Shell ScriptDocument14 pagesShell ScriptSaj PlusNo ratings yet
- Estudo Padronizacao Robo 3Document4 pagesEstudo Padronizacao Robo 3Ricardo PoletoNo ratings yet
- Lastexception 63855532120Document21 pagesLastexception 63855532120Fran BlancoNo ratings yet
- 03 Full MX Cons DTMSH Dim Ns RPT Type Catlg CTG To CMPDocument2 pages03 Full MX Cons DTMSH Dim Ns RPT Type Catlg CTG To CMPjenniferwright3264338No ratings yet
- Pntry-Instaleap-Incremental-Mx Instaleap Se-Nebula Op Step-Se ConfigDocument2 pagesPntry-Instaleap-Incremental-Mx Instaleap Se-Nebula Op Step-Se Configjenniferwright3264338No ratings yet
- BCT We Inc MX BCT Se Idc DTL TNDR Promo Se ConfigDocument2 pagesBCT We Inc MX BCT Se Idc DTL TNDR Promo Se Configjenniferwright3264338No ratings yet
- 03 Inc MX BCT Se Idc DTL TNDR Promo Raw To CTGDocument2 pages03 Inc MX BCT Se Idc DTL TNDR Promo Raw To CTGjenniferwright3264338No ratings yet
- Scenarios of Incidents For Trade Test Practices at HVTC (18-9-2021)Document7 pagesScenarios of Incidents For Trade Test Practices at HVTC (18-9-2021)藍青No ratings yet
- WAsP Software D Licencing GuideDocument2 pagesWAsP Software D Licencing GuideSantiago Flores AupazNo ratings yet
- Denr-Car Trip 2023-2025Document40 pagesDenr-Car Trip 2023-2025K Haji TVNo ratings yet
- An Overview of Firewall Technologies: Keywords: Firewall Technologies, Network Security, Access Control, SecurityDocument9 pagesAn Overview of Firewall Technologies: Keywords: Firewall Technologies, Network Security, Access Control, SecurityAjitav BasakNo ratings yet
- 651C MSK Pressure Controller ManualDocument160 pages651C MSK Pressure Controller ManualHoa DaoNo ratings yet
- WF-C20590 C17590 Rev.HDocument1,520 pagesWF-C20590 C17590 Rev.HHEGEL CRISTIAN ROCA PEREZ100% (7)
- HD 5Document5 pagesHD 5bachaduongphuongNo ratings yet
- Resume Letizia TincoliniDocument3 pagesResume Letizia Tincolinilaetitia86No ratings yet
- 252 SiPass Int MP2 65SP2 RelNotes A-100083-1 en ADocument40 pages252 SiPass Int MP2 65SP2 RelNotes A-100083-1 en Aedwin garcia100% (1)
- KX-FP701FX: Operating InstructionsDocument56 pagesKX-FP701FX: Operating InstructionswinaryantoNo ratings yet
- GS EravapDocument8 pagesGS EravapYan RiveraNo ratings yet
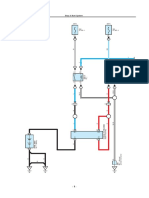
- System Circuit Engine - Hybrid System Stop - Start SystemDocument19 pagesSystem Circuit Engine - Hybrid System Stop - Start SystemEdik Bonifacio MamaniNo ratings yet
- File B - Ketikkan Word Dengan JawabanDocument5 pagesFile B - Ketikkan Word Dengan JawabanAprilia Dwihana SajidahNo ratings yet
- Application of PCA-CNN (Principal Component Analysis - Convolutional Neural Networks) Method On Sentinel-2 Image Classification For Land Cover MappingDocument5 pagesApplication of PCA-CNN (Principal Component Analysis - Convolutional Neural Networks) Method On Sentinel-2 Image Classification For Land Cover MappingIJAERS JOURNALNo ratings yet
- RICOH IM CW2200 BrochureDocument8 pagesRICOH IM CW2200 BrochureAbdirachid AbdiNo ratings yet
- PCSX2 Readme PDFDocument4 pagesPCSX2 Readme PDFsdfNo ratings yet
- QR Code and Student Instruction document-PVL3701Document1 pageQR Code and Student Instruction document-PVL3701Nabeelah AngamiaNo ratings yet
- Ea15a Manual en PDFDocument6 pagesEa15a Manual en PDFTimmyJuriNo ratings yet
- Example CV - JavaScript DeveloperDocument3 pagesExample CV - JavaScript DeveloperRadu AnastaseNo ratings yet
- 10 - Todorut Amalia VeneraDocument5 pages10 - Todorut Amalia VeneraTomoiu Bianca GeorgianaNo ratings yet
- SonobuoyDocument28 pagesSonobuoySahal Babu100% (1)
- A Complete Guide About Solar Panel Installation. Step by Step Procedure With Calculation and Images - Electrical TechnologyDocument16 pagesA Complete Guide About Solar Panel Installation. Step by Step Procedure With Calculation and Images - Electrical TechnologyChukwudi AugustineNo ratings yet
- Game Boi VST Install Guide Hzrd6yDocument5 pagesGame Boi VST Install Guide Hzrd6ykhususruttrackerNo ratings yet
- Ever Since Men Began To Modify Their Lives by Using Technology They Have Found Themselves in A Series of Technology TrapsDocument10 pagesEver Since Men Began To Modify Their Lives by Using Technology They Have Found Themselves in A Series of Technology TrapsAgatha OfrecioNo ratings yet
- EECI Incoloy825HeatingElements ProductFlyer 140129 ScreenDocument2 pagesEECI Incoloy825HeatingElements ProductFlyer 140129 ScreenMohd AzharNo ratings yet
- ICOM AG-2400 2.4 GHZ Down Converter WWDocument4 pagesICOM AG-2400 2.4 GHZ Down Converter WW10sd156No ratings yet
- MISP TCA Resit Spring 2021Document4 pagesMISP TCA Resit Spring 2021Chester MochereNo ratings yet
- Computer Network NoteDocument81 pagesComputer Network Noteupendrapaudel0No ratings yet
- MS Samsung Cassette r22 Airconditioner 2 PDFDocument2 pagesMS Samsung Cassette r22 Airconditioner 2 PDFMacSparesNo ratings yet