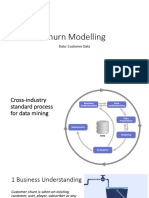
Lec - 4
Lec - 4
Download as pdf or txt
You might also like
- Attorney General V Blake 2001 1 Ac 268Document1 pageAttorney General V Blake 2001 1 Ac 268Dennis KimamboNo ratings yet
- Unit 2Document28 pagesUnit 2LOGESH WARAN PNo ratings yet
- Lecture TestmodelsDocument31 pagesLecture TestmodelssowmyasanthavelNo ratings yet
- Machine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingDocument26 pagesMachine Learning: Lecture 13: Model Validation Techniques, Overfitting, UnderfittingMd Fazle Rabby100% (2)
- Module3-Ensemble LearningDocument107 pagesModule3-Ensemble LearningJADEN JOSEPHNo ratings yet
- Data Mining Assignment HelpDocument5 pagesData Mining Assignment HelpStatistics Homework SolverNo ratings yet
- Week 10 - PROG 8510 Week 10Document16 pagesWeek 10 - PROG 8510 Week 10Vineel KumarNo ratings yet
- MIS410 Lecture9-10Document40 pagesMIS410 Lecture9-10Ahanaf RasheedNo ratings yet
- 5 - Model For Predictions - MLDocument52 pages5 - Model For Predictions - MLganeshNo ratings yet
- Unit 5 NewDocument9 pagesUnit 5 NewSENTHAMIZH VANI A PNo ratings yet
- Model Selection NEWDocument24 pagesModel Selection NEWMOHANA RAO GANGAVARAPUNo ratings yet
- Data Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4From EverandData Science for Beginners: Tips and Tricks for Effective Machine Learning/ Part 4No ratings yet
- ML Notes (Module-3)Document21 pagesML Notes (Module-3)karanrainavaarNo ratings yet
- Cross-Validation in Machine LearningDocument18 pagesCross-Validation in Machine LearningPriya dharshini.GNo ratings yet
- 5 no ans.Document38 pages5 no ans.prabhat0022kumarNo ratings yet
- CHP 3Document70 pagesCHP 3its9918kNo ratings yet
- Model Validation & Data PartitionDocument14 pagesModel Validation & Data PartitionibaadahmedNo ratings yet
- ML Unit 2Document33 pagesML Unit 2016-TriveniNo ratings yet
- CH 05 Optimization TechniqueDocument58 pagesCH 05 Optimization Technique1032210687No ratings yet
- Lecture 3Document15 pagesLecture 3dpmanishNo ratings yet
- ML Unit 2Document35 pagesML Unit 2suhanisweety448No ratings yet
- SML Updated UNIT 4Document44 pagesSML Updated UNIT 422416No ratings yet
- Learning Best Practices For Model Evaluation and Hyperparameter TuningDocument17 pagesLearning Best Practices For Model Evaluation and Hyperparameter Tuningsanjeev devNo ratings yet
- Cross Validation LN 12Document11 pagesCross Validation LN 12M S PrasadNo ratings yet
- Cross Validation LN 12Document11 pagesCross Validation LN 12M S PrasadNo ratings yet
- Training EvaluationDocument42 pagesTraining EvaluationRaksa KunNo ratings yet
- ML - Chapter 6 - Model EvaluationDocument65 pagesML - Chapter 6 - Model EvaluationYohannes DerejeNo ratings yet
- CSL0777 L08Document29 pagesCSL0777 L08Konkobo Ulrich ArthurNo ratings yet
- ML Unit-3 - RTUDocument20 pagesML Unit-3 - RTUvishakhasahu0001No ratings yet
- Fam QB AnsDocument9 pagesFam QB AnsRitika DaradeNo ratings yet
- Predicting ChurnDocument37 pagesPredicting ChurnSAHARUDIN BIN JAPARUDIN MoeNo ratings yet
- Unit 1 AAMDocument16 pagesUnit 1 AAMgiramashish5No ratings yet
- AIML-HC Mod 03Document46 pagesAIML-HC Mod 03kushaan.bhatNo ratings yet
- Unit6 Part3 General ProcedureDocument19 pagesUnit6 Part3 General Proceduretamanna sharmaNo ratings yet
- ML MU Unit 2Document42 pagesML MU Unit 2Paulos K100% (2)
- ML 5Document14 pagesML 5dibloaNo ratings yet
- ML MU Unit 2Document84 pagesML MU Unit 2Paulos K100% (3)
- Cross Validation in MLDocument5 pagesCross Validation in MLKittu BhargaviNo ratings yet
- Overfitting & Feature Engineering.pptxDocument37 pagesOverfitting & Feature Engineering.pptxenpassNo ratings yet
- ML.1Lecture.2 (Old)Document23 pagesML.1Lecture.2 (Old)Annayah UsmanNo ratings yet
- Wa0001.Document173 pagesWa0001.Mihir MaisuriaNo ratings yet
- ML 1 2 3Document54 pagesML 1 2 3Shoba NateshNo ratings yet
- Chapter III - Supervised and Unsupervised AlgorithmsDocument122 pagesChapter III - Supervised and Unsupervised Algorithmskhmanal49No ratings yet
- Unit VDocument12 pagesUnit Vmanglamdubey2011No ratings yet
- Unit Ii MLDocument57 pagesUnit Ii MLfokom47102No ratings yet
- Cross-Validation and Model SelectionDocument46 pagesCross-Validation and Model Selectionneelam sanjeev kumarNo ratings yet
- ML 2Document166 pagesML 2midnight.emprorerNo ratings yet
- MC4301 - ML Unit 2 (Model Evaluation and Feature Engineering)Document40 pagesMC4301 - ML Unit 2 (Model Evaluation and Feature Engineering)prathab031No ratings yet
- ML 3170724 Unit-3Document48 pagesML 3170724 Unit-3Hetvy JadejaNo ratings yet
- Types of Machine Learning AlgorithmsDocument14 pagesTypes of Machine Learning AlgorithmsVipin RajputNo ratings yet
- ML2Document8 pagesML2riteshprasad1026No ratings yet
- Lec 8Document35 pagesLec 8alalousimohammadNo ratings yet
- ML FundamentalsDocument15 pagesML FundamentalsSam SmithNo ratings yet
- 4 ClassificationDocument20 pages4 ClassificationthirosulNo ratings yet
- P-2.1.2 Cross Validation and RegularizationDocument37 pagesP-2.1.2 Cross Validation and RegularizationPuneet PariharNo ratings yet
- Section 1: Cross-Validation and Model PerformanceDocument33 pagesSection 1: Cross-Validation and Model Performancechandreshpadmani9993No ratings yet
- 3 Pred AnalysisDocument18 pages3 Pred Analysisnamisha211No ratings yet
- Assessing and Improving Prediction and Classification: Theory and Algorithms in C++From EverandAssessing and Improving Prediction and Classification: Theory and Algorithms in C++No ratings yet
- Model Evaluation: Evaluating the Performance and Accuracy of Data Warehouse ModelsFrom EverandModel Evaluation: Evaluating the Performance and Accuracy of Data Warehouse ModelsNo ratings yet
- Useless SiteDocument31 pagesUseless Sitewekepix890No ratings yet
- Harvard ManageMentorDocument3 pagesHarvard ManageMentorMarine ZhanNo ratings yet
- Technical Notes Manual: For SAP2000Document4 pagesTechnical Notes Manual: For SAP2000ahmedidrees1992No ratings yet
- Crawford UniversityDocument70 pagesCrawford UniversityIsmaila YusufNo ratings yet
- TEST - 3 (Code-C) All India Aakash Test Series For Medical-2020Document38 pagesTEST - 3 (Code-C) All India Aakash Test Series For Medical-2020fasderNo ratings yet
- Ab Urbe Condita (Document3 pagesAb Urbe Condita (Radovan SpiridonovNo ratings yet
- Maf251 Jan2024Document6 pagesMaf251 Jan202423afiqimtiyazNo ratings yet
- OmniVision OV9716Document2 pagesOmniVision OV9716cuntadinNo ratings yet
- Different Types of ComputersDocument9 pagesDifferent Types of ComputersChristian Paul Baltazar EstebanNo ratings yet
- Shelf Speaker in The Acoustic Energy AE300 Test - Audio and Home Theater - ReviewsDocument9 pagesShelf Speaker in The Acoustic Energy AE300 Test - Audio and Home Theater - Reviewsplanbeta69No ratings yet
- Target 04 PDFDocument164 pagesTarget 04 PDFJithinNo ratings yet
- Assessing The Role of Sex Appeal in Marketing CommunicationsDocument27 pagesAssessing The Role of Sex Appeal in Marketing CommunicationsCitizenNo ratings yet
- Application Note: Using Proconx Esepro With Woodward ControllersDocument11 pagesApplication Note: Using Proconx Esepro With Woodward ControllersgiopetrizzoNo ratings yet
- How To Make 3 D Effect On Corel DrawDocument20 pagesHow To Make 3 D Effect On Corel DrawSatyajeet BhagatNo ratings yet
- Lab11 Inlab and PostlabDocument5 pagesLab11 Inlab and PostlabHelloNo ratings yet
- Joinery and FixationDocument71 pagesJoinery and FixationUbaid Ullah100% (1)
- Theoretical Maximum Specific Gravity and Density of Hot Mix Asphalt (HMA)Document3 pagesTheoretical Maximum Specific Gravity and Density of Hot Mix Asphalt (HMA)Budhi Kurniawan100% (1)
- Conceitos Basicos Automa Ç Ã o - Pea 3411 - v0Document9 pagesConceitos Basicos Automa Ç Ã o - Pea 3411 - v0Alexandre RamosNo ratings yet
- The Temple of The Storm God in Aleppo Kay KohlmayerDocument14 pagesThe Temple of The Storm God in Aleppo Kay KohlmayerAbd Aljalil ArabiNo ratings yet
- Simulation of 2.4Ghz Microstrip Patch Antenna Using Ebg StructureDocument5 pagesSimulation of 2.4Ghz Microstrip Patch Antenna Using Ebg StructureSanjeev KumarNo ratings yet
- Notice For Consultant Ranking v2Document2 pagesNotice For Consultant Ranking v2Fatimah Zaharah Che MohamadNo ratings yet
- Pakistan Studies Assignment NewDocument19 pagesPakistan Studies Assignment NewAhsankietien Jaffri0% (2)
- Homeshopping - PK: The Largest Store For Online Shopping in PakistanDocument12 pagesHomeshopping - PK: The Largest Store For Online Shopping in PakistanHome PhoneNo ratings yet
- LQR For Rotating Inverted PendulumDocument14 pagesLQR For Rotating Inverted PendulumValery GaulinNo ratings yet
- Arquivo - Tabela Equivalencia AutomotivaDocument2 pagesArquivo - Tabela Equivalencia AutomotivaCarlos Eduardo ZagattoNo ratings yet
- Fundamentals of Sports TrainingDocument295 pagesFundamentals of Sports TrainingScribdTranslationsNo ratings yet
- INTRODUCTION Research Methodology Presentation1Document17 pagesINTRODUCTION Research Methodology Presentation1Walda HamadNo ratings yet
- Student ERP SystemDocument3 pagesStudent ERP SystemNikhil KumarNo ratings yet
- 914 TS - 20240625094750548Document5 pages914 TS - 20240625094750548Mohd Ismail HassanNo ratings yet