ICS Review
ICS Review
Download as pdf or txt
You might also like
- Sony Anycast Station Aws-G500e OpmDocument313 pagesSony Anycast Station Aws-G500e OpmanselmocassianoNo ratings yet
- Mano Computer System Architecture AllDocument261 pagesMano Computer System Architecture Allsuperstar53878% (9)
- 1kr Fe CoolingDocument128 pages1kr Fe Coolingfguij100% (1)
- Quickstart GuideDocument7 pagesQuickstart GuidePedro MarceloNo ratings yet
- System Software and Application SoftwareDocument3 pagesSystem Software and Application SoftwareAnonymous v5QjDW2eHxNo ratings yet
- Intro Class_CAD for VLSIDocument28 pagesIntro Class_CAD for VLSIArun .KNo ratings yet
- RISC, CISC, and Assemblers!: Hakim Weatherspoon CS 3410, Spring 2011Document31 pagesRISC, CISC, and Assemblers!: Hakim Weatherspoon CS 3410, Spring 2011Aakash KumarNo ratings yet
- MicroJava 701 by Baecker Bungert Gladisch Titze 1998 FALLDocument32 pagesMicroJava 701 by Baecker Bungert Gladisch Titze 1998 FALLcarlos1.lewiskiNo ratings yet
- 05SingleCycleCPU_1410693631Document48 pages05SingleCycleCPU_1410693631cw031001No ratings yet
- Lecture 05 ARM ProcessorsDocument65 pagesLecture 05 ARM ProcessorsNguyễn Tấn ĐịnhNo ratings yet
- High Efficiency Counter Mode Security Architecture Via Prediction and Pre-ComputationDocument22 pagesHigh Efficiency Counter Mode Security Architecture Via Prediction and Pre-ComputationlarryshiNo ratings yet
- 02 SIC XE MachineDocument38 pages02 SIC XE MachineahmedNo ratings yet
- 02 Abstract ArchDocument20 pages02 Abstract Archsanjanamooli77No ratings yet
- Chapter 2 - EditedDocument82 pagesChapter 2 - Edited沈文龙No ratings yet
- CO4 - ARM & PIC Part 1Document25 pagesCO4 - ARM & PIC Part 1Manu nilrowthNo ratings yet
- Intro To ARM Cortex-M3 (CM3) and LPC17xx MCU: OutlineDocument79 pagesIntro To ARM Cortex-M3 (CM3) and LPC17xx MCU: OutlinesupriyaNo ratings yet
- 02 ArmDocument53 pages02 ArmBasudha PalNo ratings yet
- SPDocument39 pagesSPShyam JalanNo ratings yet
- CS6103-SP-Module 1Document39 pagesCS6103-SP-Module 1Zane JhonsonNo ratings yet
- ISA - CISC VS RISC - Intro To MIPSDocument59 pagesISA - CISC VS RISC - Intro To MIPSAffan GhazaliNo ratings yet
- Digital Signal Processor 3Document25 pagesDigital Signal Processor 3Vijayaraghavan VNo ratings yet
- 03-AVR Microcontroller Tutorial - Eng MinaDocument78 pages03-AVR Microcontroller Tutorial - Eng Minamohammed ahmedNo ratings yet
- Ece4750 T01 Proc ScycleDocument24 pagesEce4750 T01 Proc ScyclekartimidNo ratings yet
- Pentium 4 StructureDocument38 pagesPentium 4 Structureapi-3801329100% (6)
- Microcontroller: Materi 2Document38 pagesMicrocontroller: Materi 2Oktaf Brillian KharismaNo ratings yet
- Basic Computer Operation and OrganizationDocument25 pagesBasic Computer Operation and OrganizationMa'munNo ratings yet
- RISC Machines: B. Ross COSC 3p92Document19 pagesRISC Machines: B. Ross COSC 3p92Achilles WanNo ratings yet
- Instruction Format PDFDocument5 pagesInstruction Format PDFG.SAIDULUNo ratings yet
- Computer System Architecture - Morris Mano (1) - Pfu79k3tv14e238u9o4r794Document517 pagesComputer System Architecture - Morris Mano (1) - Pfu79k3tv14e238u9o4r794Trending this yearNo ratings yet
- Curriculum.docx - Google DocsDocument3 pagesCurriculum.docx - Google Docs005blueharryNo ratings yet
- 2018fa CS61C L08 BN decisionsIIDocument24 pages2018fa CS61C L08 BN decisionsIIHeks JohnNo ratings yet
- HITB-v1.0 - Lab: ARM Assembly ShellcodeDocument66 pagesHITB-v1.0 - Lab: ARM Assembly ShellcodeAlbert LuzxNo ratings yet
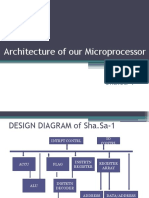
- Architecture of Sha - Sa-1 MicroprocessorDocument13 pagesArchitecture of Sha - Sa-1 MicroprocessorHeather HarrisNo ratings yet
- IA 64 Architecture ReviewDocument48 pagesIA 64 Architecture ReviewBangari NaiduNo ratings yet
- Control UnitDocument47 pagesControl UnitZul HaireyNo ratings yet
- Arm Basic ReDocument161 pagesArm Basic Reefferre79No ratings yet
- Elc2009 Qemu CrisDocument43 pagesElc2009 Qemu Crisma haijunNo ratings yet
- Sap - 2Document135 pagesSap - 2Muh Nur FaiziNo ratings yet
- NVMe1.1 Spec PPTDocument92 pagesNVMe1.1 Spec PPTviru_virajNo ratings yet
- UNIT 5-ARM ProcessorDocument55 pagesUNIT 5-ARM Processorvenkat MohanNo ratings yet
- Lec 08Document20 pagesLec 08rsrajasthanofficial600No ratings yet
- 08 - Chapter 2 PDFDocument15 pages08 - Chapter 2 PDFDimple AmudaNo ratings yet
- 08 - Chapter 2 PDFDocument15 pages08 - Chapter 2 PDFBhavani BhavanNo ratings yet
- Single-Cycle Mips ArchitectureDocument25 pagesSingle-Cycle Mips ArchitectureNicolle NaranjoNo ratings yet
- CA I - Chapter 2 ISA 2 RISC VDocument65 pagesCA I - Chapter 2 ISA 2 RISC VĐức MinhNo ratings yet
- Instruction Set Architecture (ISA)Document41 pagesInstruction Set Architecture (ISA)StarqueenNo ratings yet
- 11 ARM ProcessorDocument54 pages11 ARM ProcessorRobin SinghNo ratings yet
- High Level Synthesis - 01 - IntroductionDocument25 pagesHigh Level Synthesis - 01 - Introductiona bNo ratings yet
- 2 Central Processing Unit PDFDocument68 pages2 Central Processing Unit PDFمعتز العجيليNo ratings yet
- Lecture 05 - MicroprocessorDocument19 pagesLecture 05 - Microprocessorabdsyd21No ratings yet
- Advance Computer ArchitectureDocument43 pagesAdvance Computer ArchitectureSalman AslamNo ratings yet
- slp-week03Document55 pagesslp-week03scu.2022521460138No ratings yet
- Sem 3Document84 pagesSem 3Brijen RakholiyaNo ratings yet
- Computer System Architecture - Morris ManoDocument261 pagesComputer System Architecture - Morris ManoHarshit RautNo ratings yet
- 4897938Document67 pages4897938nshNo ratings yet
- Design of Large Scale Digital CircuitsDocument38 pagesDesign of Large Scale Digital CircuitsStudentNo ratings yet
- Algorithms For Cryptography-Education and Learning PerspectiveDocument71 pagesAlgorithms For Cryptography-Education and Learning Perspectiveposer4uNo ratings yet
- DDCA_Ch6_Ravi_annotated_v2(2)-mergedDocument176 pagesDDCA_Ch6_Ravi_annotated_v2(2)-mergedRimsha pervaizNo ratings yet
- Embedded System Design (EEMS140) : Dr. Prasanna Kumar Misra IIIT AllahabadDocument27 pagesEmbedded System Design (EEMS140) : Dr. Prasanna Kumar Misra IIIT AllahabadKashif NabiNo ratings yet
- Parallel Processing Chapter - 2: Basics of Architectural DesignDocument29 pagesParallel Processing Chapter - 2: Basics of Architectural DesignGetu GeneneNo ratings yet
- DVCon Europe 2015 TA2 2 PresentationDocument23 pagesDVCon Europe 2015 TA2 2 PresentationJon DCNo ratings yet
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.From EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.No ratings yet
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationFrom EverandPractical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and ObfuscationNo ratings yet
- Preliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960From EverandPreliminary Specifications: Programmed Data Processor Model Three (PDP-3) October, 1960No ratings yet
- Ms WordDocument15 pagesMs WordPawan KumarNo ratings yet
- AIX Command Crib SheetDocument14 pagesAIX Command Crib Sheetsantosh_kurakulaNo ratings yet
- SNX-300 Instruction ManualDocument71 pagesSNX-300 Instruction ManualdotatchuongNo ratings yet
- 2012-07-30Document35 pages2012-07-30brandonarrindellNo ratings yet
- HowtoRootTecnoPop6Go (BE6, BE6j) Easily (SimpleSteps) AndroidBiits 1706990476846Document3 pagesHowtoRootTecnoPop6Go (BE6, BE6j) Easily (SimpleSteps) AndroidBiits 1706990476846compaoreachim42No ratings yet
- Torque and TighteningDocument4 pagesTorque and Tighteningmsasng9880No ratings yet
- Wooden Architect Lamp PDFDocument13 pagesWooden Architect Lamp PDFassis_campos8950100% (1)
- Super A Can The Book - David-GlotzDocument13 pagesSuper A Can The Book - David-GlotzGABRIEL DAVID OLIVEIRA GLOTZNo ratings yet
- Cisco Start CatalogDocument4 pagesCisco Start CatalogqntttNo ratings yet
- Catalogue of International Standards Used in The Petroleum and Natural Gas IndustriesDocument129 pagesCatalogue of International Standards Used in The Petroleum and Natural Gas IndustriesmehranlnjdNo ratings yet
- Lab 01: Installing Windows Operating System and Disk PartitioningDocument8 pagesLab 01: Installing Windows Operating System and Disk PartitioningArian Ashfaque0% (1)
- Quickspecs: HP Compaq La1956X 19-Inch Led Backlit MonitorDocument10 pagesQuickspecs: HP Compaq La1956X 19-Inch Led Backlit Monitorleoncito6977No ratings yet
- Electrical Technology May-June 2022 (Digital) EngDocument27 pagesElectrical Technology May-June 2022 (Digital) Engtatendasaroti7No ratings yet
- OoniD's Panels 4Document3 pagesOoniD's Panels 4Anonymous PLwTAzQNo ratings yet
- GUI LPC2103 Cau Trúc Phàn C NGDocument104 pagesGUI LPC2103 Cau Trúc Phàn C NGBắc HoàiNo ratings yet
- Living in It Era ScrapbookDocument91 pagesLiving in It Era ScrapbookEj AparriNo ratings yet
- Implementing Client Virtualization and Cloud ComputingDocument33 pagesImplementing Client Virtualization and Cloud ComputingEthan BooisNo ratings yet
- Wii AdDocument62 pagesWii AdLuis Gustavo Felix GarciaNo ratings yet
- TurboProp Build Guide V1.6.3Document195 pagesTurboProp Build Guide V1.6.3pauloteodorovendasNo ratings yet
- Simple Arduino POV WandDocument6 pagesSimple Arduino POV WandnemoneoNo ratings yet
- OneFS Storage Efficiency For Healthcare PACS PDFDocument11 pagesOneFS Storage Efficiency For Healthcare PACS PDFDavid GiriNo ratings yet
- Unit2-Services and Components of OSDocument24 pagesUnit2-Services and Components of OSRutuja PoteNo ratings yet
- Nurse Call SpecsDocument15 pagesNurse Call SpecsRodel FadroganeNo ratings yet
- FL/MCP/MMF301: GeneralDocument2 pagesFL/MCP/MMF301: Generalrasuahmed.ixonyNo ratings yet
- Dell Vostro 1015Document8 pagesDell Vostro 1015Бојан ЧавићNo ratings yet
- Ddec VDocument30 pagesDdec Vllama90% (20)