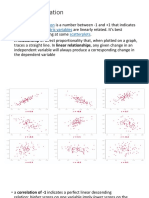
Psy 234 Investigating Relationships Week 11
Psy 234 Investigating Relationships Week 11
Download as pdf or txt
You might also like
- Pearson CorrelationDocument59 pagesPearson CorrelationSOLLEZA, FRANDA B.No ratings yet
- Community Project: Simple Linear Regression in SPSSDocument4 pagesCommunity Project: Simple Linear Regression in SPSSNeva AsihNo ratings yet
- 49 Correlation ScatterDocument4 pages49 Correlation ScatterBikky BirajiNo ratings yet
- 77 MultipleRegressionDocument4 pages77 MultipleRegressionSameeiaNo ratings yet
- MetNum1 2023 1 Week 13Document70 pagesMetNum1 2023 1 Week 13donbradman334No ratings yet
- Introduction of CorrelationDocument39 pagesIntroduction of Correlationaarya.raghav9No ratings yet
- 1 Statistical Methods For Continuous Variables Corr and RegressionDocument75 pages1 Statistical Methods For Continuous Variables Corr and RegressionFuad100% (1)
- Chapter 5 T test & ANOVADocument26 pagesChapter 5 T test & ANOVAeyobirhanu1992No ratings yet
- Two Quantitative Variables: Scatterplot, Correlation, and Linear RegressionDocument17 pagesTwo Quantitative Variables: Scatterplot, Correlation, and Linear Regressionbrownka5No ratings yet
- Biostatistics (Correlation and Regression)Document29 pagesBiostatistics (Correlation and Regression)Devyani Marathe100% (1)
- Z-Score Examples With SolutionsDocument6 pagesZ-Score Examples With SolutionsAdrian Jay JavierNo ratings yet
- Correlation Coefficient & Simple Linear Regression: STATS 101 Laurens Holmes, JRDocument53 pagesCorrelation Coefficient & Simple Linear Regression: STATS 101 Laurens Holmes, JRchipchiphopNo ratings yet
- Week8 TutorialDocument17 pagesWeek8 TutorialThu PhươngNo ratings yet
- Introduction of RegressionDocument57 pagesIntroduction of Regressionaarya.raghav9No ratings yet
- Topic - 7 - Regression AnalysisDocument33 pagesTopic - 7 - Regression AnalysisdhadkanNo ratings yet
- Chapter 5 Hypothesis TestingDocument27 pagesChapter 5 Hypothesis Testingkidi mollaNo ratings yet
- Practical Research Ii Q2 W3Document25 pagesPractical Research Ii Q2 W3Darey ApostolNo ratings yet
- This Scatterplot Shows The Relationship Between Chocolate Consumption and Body Weight. On TheDocument2 pagesThis Scatterplot Shows The Relationship Between Chocolate Consumption and Body Weight. On TheAisha ChohanNo ratings yet
- Statistical TreatmentDocument41 pagesStatistical TreatmentTAMAYO, Ruth P.No ratings yet
- ASS#1-FINALS DoromalDocument8 pagesASS#1-FINALS DoromalAna DoromalNo ratings yet
- Correlation and Regression: Associate Professor Georgi Iskrov, PHD Department of Social Medicine and Public HealthDocument28 pagesCorrelation and Regression: Associate Professor Georgi Iskrov, PHD Department of Social Medicine and Public HealthKARTHIK SREEKUMARNo ratings yet
- Correlation Analysis MBADocument17 pagesCorrelation Analysis MBAravi anandNo ratings yet
- Statistics MATH FINALS REVIEWERDocument28 pagesStatistics MATH FINALS REVIEWERLOUISE ANDRHEA D. DOLOTALLASNo ratings yet
- Chapter 4 Correlational AnalysisDocument13 pagesChapter 4 Correlational AnalysisLeslie Anne Bite100% (2)
- AIML Hon. Practical 3 - 1Document8 pagesAIML Hon. Practical 3 - 1Saniya BondeNo ratings yet
- Short Term Training Programme On Data Analytics Using SPSS and RCMDRDocument20 pagesShort Term Training Programme On Data Analytics Using SPSS and RCMDRAr Apurva SharmaNo ratings yet
- CorrelationDocument29 pagesCorrelations.zainabtanweerNo ratings yet
- Correlational AnalysisDocument28 pagesCorrelational Analysiscorpuzmica27No ratings yet
- AIML Hon. Practical 3Document8 pagesAIML Hon. Practical 3Saniya BondeNo ratings yet
- What Is Correlation: (Pearson) Correlation Metric Variables ScatterplotsDocument13 pagesWhat Is Correlation: (Pearson) Correlation Metric Variables ScatterplotsRashidNo ratings yet
- Chapter 5 Hypothesis TestingDocument27 pagesChapter 5 Hypothesis Testingsolomon edaoNo ratings yet
- Powepoint Presentation On Correlation and Regression AnalysisDocument51 pagesPowepoint Presentation On Correlation and Regression AnalysisRene Aubert MbonimpaNo ratings yet
- Lecture 5 - CorrelationDocument48 pagesLecture 5 - CorrelationEight ThousandNo ratings yet
- W15 - Simple Linear Regression and CorelationDocument61 pagesW15 - Simple Linear Regression and CorelationMuhammad AreebNo ratings yet
- Mod 3aDocument54 pagesMod 3akamleshmisra22No ratings yet
- Chapter 3 - RegressionDocument8 pagesChapter 3 - Regressiondiya254mNo ratings yet
- Steps in SPSS To Find Correlation Matrix and Partial CorrelationDocument33 pagesSteps in SPSS To Find Correlation Matrix and Partial Correlationmanas.23pgdm157No ratings yet
- CorrelationDocument9 pagesCorrelationsanjeev khanalNo ratings yet
- Linear RegressionDocument72 pagesLinear RegressionMD. SAKIBUR RAHMANNo ratings yet
- 6nov regressionII 202425Document40 pages6nov regressionII 202425kellycykchanNo ratings yet
- Pearson RDocument25 pagesPearson Randrianarellano23No ratings yet
- Regression AnalysisDocument34 pagesRegression Analysissumrun sahabNo ratings yet
- Stat Is TikaDocument44 pagesStat Is TikaImelda Free Unita ManurungNo ratings yet
- Quiz Simple RegressionDocument5 pagesQuiz Simple RegressionEvans AzandeNo ratings yet
- MMW (Data Management) - Part 2Document43 pagesMMW (Data Management) - Part 2arabellah shainnah rosalesNo ratings yet
- S.id.C.8 Linear RegressionDocument11 pagesS.id.C.8 Linear RegressionSmita NagNo ratings yet
- Eda ReviewerDocument12 pagesEda ReviewerLianne RegorosaNo ratings yet
- Chapter 6 - Correlation AnalysisDocument132 pagesChapter 6 - Correlation AnalysisNicole AgustinNo ratings yet
- Correlation Anad RegressionDocument13 pagesCorrelation Anad RegressionMY LIFE MY WORDSNo ratings yet
- FALLSEM2023-24 SWE2020 ETH VL2023240103291 2023-11-22 Reference-Material-IIDocument26 pagesFALLSEM2023-24 SWE2020 ETH VL2023240103291 2023-11-22 Reference-Material-IIKartik SoniNo ratings yet
- L7 CorrelationDocument40 pagesL7 CorrelationderisivebratNo ratings yet
- Correlation and Linear RegressionDocument46 pagesCorrelation and Linear RegressionNguyễn Đức TuấnNo ratings yet
- SUMSEM2022-23 ITA6014 TH VL2022230701044 2023-08-08 Reference-Material-IDocument31 pagesSUMSEM2022-23 ITA6014 TH VL2022230701044 2023-08-08 Reference-Material-Idinesh kumar dkNo ratings yet
- Correlation 1Document9 pagesCorrelation 1Bharat ChaudharyNo ratings yet
- Point-Biserial and Biserial CorrelationDocument6 pagesPoint-Biserial and Biserial Correlationmagicboy88No ratings yet
- Session 12Document9 pagesSession 12Osman Gani TalukderNo ratings yet
- Introduction To Correlation and Regression AnalysisDocument23 pagesIntroduction To Correlation and Regression AnalysisshoaibNo ratings yet
- Quntative Data Analysis SPSS: Correlation & RegressionDocument65 pagesQuntative Data Analysis SPSS: Correlation & RegressionRania AbdullahNo ratings yet
- CM8.1 Pearson Product Moment CorrelationDocument5 pagesCM8.1 Pearson Product Moment CorrelationJasher VillacampaNo ratings yet
- Enrique Dóal Pérez Frías - Predictive Methods For Football and Betting Markets (2023)Document485 pagesEnrique Dóal Pérez Frías - Predictive Methods For Football and Betting Markets (2023)RON MORGAN100% (1)
- 6Vol99No14 2021 JATITDocument11 pages6Vol99No14 2021 JATITMujiono SadikinNo ratings yet
- Linear Discriminant AnalysisDocument33 pagesLinear Discriminant AnalysisNaman JainNo ratings yet
- Prevalence and Determinants of Exocrine Pancreatic Insufficiency Among Older Adults Results of A Population Based StudyDocument9 pagesPrevalence and Determinants of Exocrine Pancreatic Insufficiency Among Older Adults Results of A Population Based StudyguschinNo ratings yet
- PLUM - Ordinal Regression: WarningsDocument3 pagesPLUM - Ordinal Regression: WarningsAnastasia WijayaNo ratings yet
- Problem Set 4: Theory QuestionsDocument5 pagesProblem Set 4: Theory QuestionsGuido GilliNo ratings yet
- Towards AI-Enabled Hardware Security: Challenges and OpportunitiesDocument10 pagesTowards AI-Enabled Hardware Security: Challenges and OpportunitiesAmal HamadaNo ratings yet
- 1 Introduction To Machine LearningDocument32 pages1 Introduction To Machine LearningKarina Flores TorresNo ratings yet
- Unit 2 Data PreprocessingDocument40 pagesUnit 2 Data PreprocessingAbhijeet ThamakeNo ratings yet
- Esci50559.2021.9397029Document5 pagesEsci50559.2021.9397029Jamal AhmedNo ratings yet
- Roth 2002 - A New Questionnaire To Detect Sleep DisordersDocument10 pagesRoth 2002 - A New Questionnaire To Detect Sleep DisordersUtia KhairaNo ratings yet
- Paper+1+ (2023 4 1) +Food+Satisfaction+Among+Students+a+Study+of+Present+Public+University+Document18 pagesPaper+1+ (2023 4 1) +Food+Satisfaction+Among+Students+a+Study+of+Present+Public+University+Ella joy LayagonNo ratings yet
- When Words SweatDocument83 pagesWhen Words SweatExacapeNo ratings yet
- Cesarean Scar Defect: A Prospective Study On Risk Factors: GynecologyDocument8 pagesCesarean Scar Defect: A Prospective Study On Risk Factors: Gynecologynuphie_nuphNo ratings yet
- Crop ResidueDocument11 pagesCrop ResidueZarin juthiNo ratings yet
- Comparison of Classification AlgorithmsDocument11 pagesComparison of Classification AlgorithmsFatih Melih UluşanNo ratings yet
- Solution HW 1Document9 pagesSolution HW 1Nixon PatelNo ratings yet
- 35 Years of Studies On Business Failure - An Overview of The Classic Statistical Methodologies and Their Related ProblemsDocument31 pages35 Years of Studies On Business Failure - An Overview of The Classic Statistical Methodologies and Their Related ProblemsGaMer LoidNo ratings yet
- Wiese Freund IJBD 2011Document8 pagesWiese Freund IJBD 2011Vivian Agnolo MadalozzoNo ratings yet
- Multivariate Data Analysis: Overview of MethodsDocument30 pagesMultivariate Data Analysis: Overview of MethodsAnjali Shergil100% (1)
- 03 Logistic RegressionDocument23 pages03 Logistic RegressionHarold CostalesNo ratings yet
- Unit IIDocument13 pagesUnit IImananrawat537100% (1)
- SPSSC For Social ScienceDocument353 pagesSPSSC For Social ScienceIsrael Celi ToledoNo ratings yet
- Introduction To Machine Learning: 2 Linear ClassifiersDocument4 pagesIntroduction To Machine Learning: 2 Linear ClassifiersSandeep Kumar YadlapalliNo ratings yet
- 2023 CFA L2 Book 1 Quants Eco MultipleDocument63 pages2023 CFA L2 Book 1 Quants Eco MultiplePRNo ratings yet
- Predictors of Progression and Regression in Exercise Adoption in Young Women1Document14 pagesPredictors of Progression and Regression in Exercise Adoption in Young Women1DanielBCNo ratings yet
- Poverty Alleviation in The Philippines Through Entrepreneurship: An Empirical AnalysisDocument13 pagesPoverty Alleviation in The Philippines Through Entrepreneurship: An Empirical AnalysisSHAL NeyNo ratings yet
- Stats Formulas &tablesDocument21 pagesStats Formulas &tablesChandra ReddyNo ratings yet
- A Journey From Persuasion To Decision of Generation Z-Empirical Evidence of Rhetoric Effect Strategies in AdvertisementDocument15 pagesA Journey From Persuasion To Decision of Generation Z-Empirical Evidence of Rhetoric Effect Strategies in AdvertisementMRINAL GOYALNo ratings yet
- Results Binomial Logistic Regression: Model Deviance AIC RDocument7 pagesResults Binomial Logistic Regression: Model Deviance AIC RSmit MangeNo ratings yet