0% found this document useful (0 votes)
16 viewsLecture 09 Model Misspecification
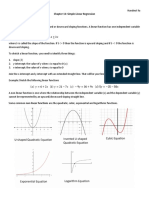
This lecture discusses model misspecification, focusing on the consequences of including irrelevant variables or omitting relevant ones in statistical models. It highlights two types of misspecification: omitting an important explanatory variable and including unnecessary ones, both of which can lead to biased estimates and invalid statistical tests. The lecture also explains how these issues affect the efficiency of estimators and the interpretation of goodness-of-fit measures in regression analysis.
Uploaded by
AngelinaCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
16 viewsLecture 09 Model Misspecification
This lecture discusses model misspecification, focusing on the consequences of including irrelevant variables or omitting relevant ones in statistical models. It highlights two types of misspecification: omitting an important explanatory variable and including unnecessary ones, both of which can lead to biased estimates and invalid statistical tests. The lecture also explains how these issues affect the efficiency of estimators and the interpretation of goodness-of-fit measures in regression analysis.
Uploaded by
AngelinaCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 5