0% found this document useful (0 votes)
3 viewsLogistic Regression_ Gradient Descent_ Example
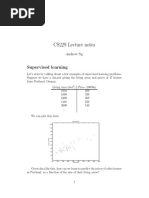
The document describes a step-by-step process for updating weights and bias in a binary classification model using a dataset with four samples. It includes calculations for the forward pass, binary cross-entropy cost, gradients, and updates for weights and bias across multiple samples. After one epoch, the final updated parameters are a weight of 0.0077 and a bias of 0.0561.
Uploaded by
manchestermilf1Copyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
3 viewsLogistic Regression_ Gradient Descent_ Example
The document describes a step-by-step process for updating weights and bias in a binary classification model using a dataset with four samples. It includes calculations for the forward pass, binary cross-entropy cost, gradients, and updates for weights and bias across multiple samples. After one epoch, the final updated parameters are a weight of 0.0077 and a bias of 0.0561.
Uploaded by
manchestermilf1Copyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 4