0% found this document useful (0 votes)
2 viewsStatistical_Computing
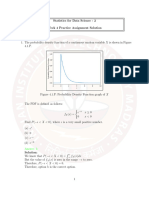
The document outlines a statistical computing coursework involving the derivation of a cumulative distribution function (CDF) from a given probability density function (PDF), and the application of the inverse probability integral transformation (PIT) theorem to generate random samples from the target distribution. It also discusses rejection sampling, including the steps to implement the algorithm and the efficiency measured by the acceptance rate. The results demonstrate that the generated samples closely match the expected distributions, with visual representations through histograms and density curves.
Uploaded by
chaoyang.soconsultingCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
2 viewsStatistical_Computing
The document outlines a statistical computing coursework involving the derivation of a cumulative distribution function (CDF) from a given probability density function (PDF), and the application of the inverse probability integral transformation (PIT) theorem to generate random samples from the target distribution. It also discusses rejection sampling, including the steps to implement the algorithm and the efficiency measured by the acceptance rate. The results demonstrate that the generated samples closely match the expected distributions, with visual representations through histograms and density curves.
Uploaded by
chaoyang.soconsultingCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 6