0% found this document useful (0 votes)
4 viewsML Using Python Unit3 pdf
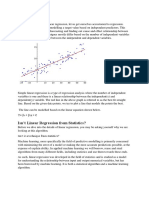
The document provides an overview of regression analysis, explaining its purpose in predicting continuous variables and detailing various types of regression algorithms, including linear, polynomial, and logistic regression. It highlights the differences between simple and multiple linear regression, as well as the significance of logistic regression for classification problems. Additionally, it discusses maximum likelihood estimation (MLE) and its applications in statistical modeling.
Uploaded by
UdayCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
4 viewsML Using Python Unit3 pdf
The document provides an overview of regression analysis, explaining its purpose in predicting continuous variables and detailing various types of regression algorithms, including linear, polynomial, and logistic regression. It highlights the differences between simple and multiple linear regression, as well as the significance of logistic regression for classification problems. Additionally, it discusses maximum likelihood estimation (MLE) and its applications in statistical modeling.
Uploaded by
UdayCopyright
© © All Rights Reserved
Available Formats
Download as PDF, TXT or read online on Scribd
/ 8