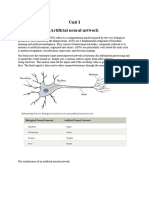
Artificial Neural Networks in Bi: Information System Dept ITS Surabaya 2009
Artificial Neural Networks in Bi: Information System Dept ITS Surabaya 2009
Download as ppt, pdf, or txt
You might also like
- King-Rook Vs King With Neural NetworksDocument10 pagesKing-Rook Vs King With Neural NetworksfuzzieNo ratings yet
- Tom Quayle - From Rock To Fusion DVDDocument11 pagesTom Quayle - From Rock To Fusion DVDJuan Villegas100% (2)
- Back-Propagation Algorithm of CHBPN CodeDocument10 pagesBack-Propagation Algorithm of CHBPN Codesch203No ratings yet
- Unit 4Document38 pagesUnit 4Abhinav KaushikNo ratings yet
- ANNDocument3 pagesANNmuhammadhamzaansari06No ratings yet
- 2020a1t182 Assgn1Document9 pages2020a1t182 Assgn1Aahib NazirNo ratings yet
- A Multilayer Feed-Forward Neural NetworkDocument9 pagesA Multilayer Feed-Forward Neural NetworkdebmatraNo ratings yet
- Aditya Jain NN AssignmentDocument13 pagesAditya Jain NN AssignmentAditya JainNo ratings yet
- Multiple-Layer Networks Backpropagation AlgorithmsDocument46 pagesMultiple-Layer Networks Backpropagation AlgorithmsZa'imahPermatasariNo ratings yet
- MLT Answer KeyDocument10 pagesMLT Answer KeyUma MaheswariNo ratings yet
- Neural NetworksDocument27 pagesNeural Networksrandom98appNo ratings yet
- Back Propagation Algorithm - A Review: Mrinalini Smita & Dr. Anita KumariDocument6 pagesBack Propagation Algorithm - A Review: Mrinalini Smita & Dr. Anita KumariTJPRC PublicationsNo ratings yet
- Unit 1Document19 pagesUnit 1Mohamed riyanNo ratings yet
- ML Unit-IvDocument19 pagesML Unit-IvYadavilli VinayNo ratings yet
- Deep Learning (1)Document19 pagesDeep Learning (1)sahupalak02No ratings yet
- CT1 DL AnsDocument13 pagesCT1 DL AnsDhivya Bharathi pNo ratings yet
- Pattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkDocument5 pagesPattern Classification of Back-Propagation Algorithm Using Exclusive Connecting NetworkEkin RafiaiNo ratings yet
- Applicable Artificial Intelligence Back Propagation: Academic Session 2022/2023Document20 pagesApplicable Artificial Intelligence Back Propagation: Academic Session 2022/2023muhammed suhailNo ratings yet
- Neural NetworksDocument6 pagesNeural NetworksARVINDNo ratings yet
- Neural Net 3rdclassDocument35 pagesNeural Net 3rdclassUttam SatapathyNo ratings yet
- Unit 2 v1.Document41 pagesUnit 2 v1.Kommi Venkat sakethNo ratings yet
- 11 Lesson 8Document6 pages11 Lesson 8mec17b209No ratings yet
- Assignment - 4Document24 pagesAssignment - 4Durga prasad TNo ratings yet
- Soft Computing-Lab FileDocument40 pagesSoft Computing-Lab FileAaaNo ratings yet
- Mid 1 DL NotesDocument15 pagesMid 1 DL Notesrajeshkollu81No ratings yet
- UNit 6 Machine LearningDocument23 pagesUNit 6 Machine LearningAyan ShaikhNo ratings yet
- Chapters 1-4Document6 pagesChapters 1-4bebo fayezNo ratings yet
- Training Neural Networks With GA Hybrid AlgorithmsDocument12 pagesTraining Neural Networks With GA Hybrid Algorithmsjkl316No ratings yet
- Neural NetworksDocument37 pagesNeural NetworksOmiarNo ratings yet
- 10 1 1 45Document45 pages10 1 1 45Akanksha GuptaNo ratings yet
- Notes On Introduction To Deep LearningDocument19 pagesNotes On Introduction To Deep Learningthumpsup1223No ratings yet
- Artificial Neural Network NotesDocument9 pagesArtificial Neural Network NotesTri FoxNo ratings yet
- Tutorial 6 1. List The Relationships Between Biological and Artificial Networks. Biological ArtificialDocument3 pagesTutorial 6 1. List The Relationships Between Biological and Artificial Networks. Biological ArtificialPeter KongNo ratings yet
- Artificial Neural Networks (ANN) : 1-IntroductionDocument5 pagesArtificial Neural Networks (ANN) : 1-IntroductionSarah DhaouiNo ratings yet
- Deep Learning PDFDocument55 pagesDeep Learning PDFNitesh Kumar SharmaNo ratings yet
- Deep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908Document5 pagesDeep Learning Assignment 1 Solution: Name: Vivek Rana Roll No.: 1709113908vikNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- Exp - 4 - 5 (Prakash)Document10 pagesExp - 4 - 5 (Prakash)rajchaudhary8733No ratings yet
- Filtering Noises From Speech Signal: A BPNN ApproachDocument4 pagesFiltering Noises From Speech Signal: A BPNN Approacheditor_ijarcsseNo ratings yet
- ML Unit-IiDocument41 pagesML Unit-IibharathkatamneniNo ratings yet
- Optimal Neural Network Models For Wind SDocument12 pagesOptimal Neural Network Models For Wind SMuneeba JahangirNo ratings yet
- Experiment No. 6 TE SL-II (ANN)Document2 pagesExperiment No. 6 TE SL-II (ANN)RutujaNo ratings yet
- Experiment 1Document7 pagesExperiment 1mohammed.ansariNo ratings yet
- Session 1Document8 pagesSession 1Ramu ThommandruNo ratings yet
- Aiml Unit 5Document16 pagesAiml Unit 5kanishNo ratings yet
- Unit 2 Deep LearningDocument19 pagesUnit 2 Deep Learningsahil.utube2003No ratings yet
- UNIT_1_DLDocument18 pagesUNIT_1_DLssuresh.pecNo ratings yet
- TensorflowDocument25 pagesTensorflowSudharshan VenkateshNo ratings yet
- 19 - Introduction To Neural NetworksDocument7 pages19 - Introduction To Neural NetworksRugalNo ratings yet
- Charotar University of Science and Technology Faculty of Technology and EngineeringDocument10 pagesCharotar University of Science and Technology Faculty of Technology and EngineeringSmruthi SuvarnaNo ratings yet
- IT 701 Soft Computing Unit II - 1722317891Document13 pagesIT 701 Soft Computing Unit II - 1722317891Mohit ShindeNo ratings yet
- Week - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Document7 pagesWeek - 5 (Deep Learning) Q. 1) Explain The Architecture of Feed Forward Neural Network or Multilayer Perceptron. (12 Marks)Mrunal BhilareNo ratings yet
- Amansoftcomp PDFDocument27 pagesAmansoftcomp PDFas6858732No ratings yet
- Architecture and Learning process in neural network - GeeksforGeeksDocument6 pagesArchitecture and Learning process in neural network - GeeksforGeeksk43047537No ratings yet
- Nnn3neural NetworksDocument5 pagesNnn3neural Networkskumar219No ratings yet
- Unit Iv DMDocument58 pagesUnit Iv DMSuganthi D PSGRKCWNo ratings yet
- Lecture 13.3 Classification ANNDocument64 pagesLecture 13.3 Classification ANNRoky DasNo ratings yet
- Neural Network Two Mark Q.BDocument19 pagesNeural Network Two Mark Q.BMohanvel2106No ratings yet
- Lecture 4Document65 pagesLecture 4Ces BiolettiNo ratings yet
- Backpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningFrom EverandBackpropagation: Fundamentals and Applications for Preparing Data for Training in Deep LearningNo ratings yet
- Mochammad Adji Firmansyah Study PlanDocument1 pageMochammad Adji Firmansyah Study PlanMochammad Adji Firmansyah100% (1)
- Pengantar Manajemen Rantai Pasok: Oleh: Erma SuryaniDocument53 pagesPengantar Manajemen Rantai Pasok: Oleh: Erma SuryaniMochammad Adji FirmansyahNo ratings yet
- TQ 1Document6 pagesTQ 1Mochammad Adji Firmansyah80% (5)
- Tq1 Hopes NotesDocument1 pageTq1 Hopes NotesMochammad Adji FirmansyahNo ratings yet
- Forecasting Time Series With Arma and Arima Models The Box-Jenkins MethodologyDocument35 pagesForecasting Time Series With Arma and Arima Models The Box-Jenkins MethodologyMochammad Adji Firmansyah100% (1)
- C Dominant 7flat5 Arpeggio: 44 P V Ev Ev V V Ev Ev V V Ev Ev V V V V V V Ev eVV JDocument2 pagesC Dominant 7flat5 Arpeggio: 44 P V Ev Ev V V Ev Ev V V Ev Ev V V V V V V Ev eVV JMochammad Adji FirmansyahNo ratings yet
- Analisis 3: Nilai Negatif Pada Analisis 1 Yang Di Drop Lalu Model Dijalankan Kembali - Hasil Analisisnya Sebagai BerikutDocument3 pagesAnalisis 3: Nilai Negatif Pada Analisis 1 Yang Di Drop Lalu Model Dijalankan Kembali - Hasil Analisisnya Sebagai BerikutMochammad Adji FirmansyahNo ratings yet
- Contoh KuesionerDocument2 pagesContoh KuesionerMochammad Adji FirmansyahNo ratings yet
- Pokok Bahasan #1-1 Review BDDocument30 pagesPokok Bahasan #1-1 Review BDMochammad Adji FirmansyahNo ratings yet
- JWB NMR 22Document1 pageJWB NMR 22Mochammad Adji FirmansyahNo ratings yet
- Tugas 2 SMBDDocument11 pagesTugas 2 SMBDMochammad Adji FirmansyahNo ratings yet
- Tugas 1 SMBDDocument6 pagesTugas 1 SMBDMochammad Adji FirmansyahNo ratings yet
- Ks091201 Brochure Example TemplateDocument3 pagesKs091201 Brochure Example TemplateMochammad Adji FirmansyahNo ratings yet
- Discrete Math: An Overview: Matematika DiskritDocument6 pagesDiscrete Math: An Overview: Matematika DiskritMochammad Adji FirmansyahNo ratings yet
- 8 Mobile Technologies To Watch in 2009, 2010: Bluetooth 3.0Document3 pages8 Mobile Technologies To Watch in 2009, 2010: Bluetooth 3.0Mochammad Adji FirmansyahNo ratings yet
- Workshop II-V-IDocument8 pagesWorkshop II-V-IMochammad Adji FirmansyahNo ratings yet
- 6.2 Shadow Bid Model AssumptionsDocument8 pages6.2 Shadow Bid Model Assumptionsshammuji9581No ratings yet
- Ud Wirastri: Memorial Journal (CLOSING ENTRY)Document1 pageUd Wirastri: Memorial Journal (CLOSING ENTRY)Daulat mugiNo ratings yet
- Origin of SHG in IndiaDocument2 pagesOrigin of SHG in IndiaVicky Patel60% (5)
- Sep2017MORNBFI1 PDFDocument969 pagesSep2017MORNBFI1 PDFMark RiveraNo ratings yet
- The Money Myth ExplodedDocument20 pagesThe Money Myth ExplodedscriberoneNo ratings yet
- Cholamandalam Initiation ReportDocument44 pagesCholamandalam Initiation ReportgirishrajsNo ratings yet
- Colt Request FormDocument1 pageColt Request FormAmmoLand Shooting Sports NewsNo ratings yet
- 2008 10-15-2009 3 CLJ 709 Standard Chartered Bank Malaysia BHD V Duli Yang Maha Mulia Tuanku Jaafar EdDocument18 pages2008 10-15-2009 3 CLJ 709 Standard Chartered Bank Malaysia BHD V Duli Yang Maha Mulia Tuanku Jaafar EdSiti Noor MardianaNo ratings yet
- VolkswagenDocument16 pagesVolkswagenHarshitAgrawalNo ratings yet
- Faculty of Commerce Name: Mangongo Batsirayi Reg Number: L0160425T Research Topic: An Investigation On The PerceivedDocument23 pagesFaculty of Commerce Name: Mangongo Batsirayi Reg Number: L0160425T Research Topic: An Investigation On The PerceivedBatsirayi MangongoNo ratings yet
- Accounts Receivable - Extractor FieldsDocument8 pagesAccounts Receivable - Extractor FieldsChirayu ChavdaNo ratings yet
- MERS Reports HB Rel 25Document111 pagesMERS Reports HB Rel 25TBNo ratings yet
- Capital StructureDocument16 pagesCapital Structureanushri100% (1)
- Reliance CommunicationsDocument117 pagesReliance Communicationsrahul m dNo ratings yet
- LAND BANK OF THE PHILIPPINES vs. SPOUSES PLACIDODocument18 pagesLAND BANK OF THE PHILIPPINES vs. SPOUSES PLACIDOAnne ObnamiaNo ratings yet
- Principles of Accounts MCDocument25 pagesPrinciples of Accounts MCBro Johnson78% (18)
- Alandurseweragetreatmentplantproject Pppmodel 190927110958 PDFDocument15 pagesAlandurseweragetreatmentplantproject Pppmodel 190927110958 PDFTran Binh MinhNo ratings yet
- Banga Versus BelloDocument15 pagesBanga Versus BelloAnskee TejamNo ratings yet
- 6 Si Ci PMD PDF Compressed 20200930030151Document8 pages6 Si Ci PMD PDF Compressed 20200930030151Anandita UpadhyayNo ratings yet
- Ratio AnalysisDocument9 pagesRatio AnalysisrakeshkchouhanNo ratings yet
- Using Vocabulary in Business and EconomicsDocument13 pagesUsing Vocabulary in Business and EconomicsKashani100% (2)
- Presentation Mandarin OrientalDocument62 pagesPresentation Mandarin OrientalAndra Manta100% (1)
- SEC V Laigo DigestDocument3 pagesSEC V Laigo DigestClarence ProtacioNo ratings yet
- Mirror DoctrineDocument9 pagesMirror DoctrineJanet Tal-udanNo ratings yet
- Executive SummaryDocument84 pagesExecutive SummaryNeha SharmaNo ratings yet
- KB240211FMDUC - KFS & Sanction LetterDocument10 pagesKB240211FMDUC - KFS & Sanction Letterrudraprasad520No ratings yet
- West Bengal Financial Rules: Chapter-01: Introductory and DefinitionsDocument5 pagesWest Bengal Financial Rules: Chapter-01: Introductory and DefinitionsGautamDuttaNo ratings yet
- Chapter 24 CPWD ACCOUNTS CODEDocument5 pagesChapter 24 CPWD ACCOUNTS CODEarulraj1971No ratings yet
- Topic 8: Financing The New VentureDocument31 pagesTopic 8: Financing The New VentureAmrezaa IskandarNo ratings yet
- Erie County PA Property Transfers For March 2007Document11 pagesErie County PA Property Transfers For March 2007api-3705969No ratings yet