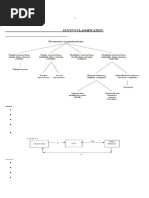
Aca Unit 1.1
Aca Unit 1.1
Download as pptx, pdf, or txt
You might also like
- SOR01 TareaDocument10 pagesSOR01 TareaIria LorenzoNo ratings yet
- Parallel ProcessingDocument35 pagesParallel ProcessingGetu GeneneNo ratings yet
- Computer Architecture and Parallel ProcessingDocument29 pagesComputer Architecture and Parallel ProcessingFaisal ShafiqNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- Lec 5Document14 pagesLec 5Sayantani DuttaNo ratings yet
- PDC Assignment 1Document5 pagesPDC Assignment 1Samavia RiazNo ratings yet
- Cloud Computing - Lecture 3Document22 pagesCloud Computing - Lecture 3Muhammad FahadNo ratings yet
- Unit2_aDocument70 pagesUnit2_aYashaswini MNo ratings yet
- Baker CHPT 5 SIMD GoodDocument94 pagesBaker CHPT 5 SIMD GoodAsif MehmoodNo ratings yet
- Flynn's Taxonomy: 1. SisdDocument7 pagesFlynn's Taxonomy: 1. SisdJaweria SiddiquiNo ratings yet
- Module 4- ArchitectureDocument22 pagesModule 4- ArchitectureAbhigyan GangulyNo ratings yet
- u 1 cDocument20 pagesu 1 cshivamkashid70No ratings yet
- Module 2 - Parallel ComputingDocument55 pagesModule 2 - Parallel ComputingmuwaheedmustaphaNo ratings yet
- StudM1p1Parallel Computer Modelsppt1sharedDocument107 pagesStudM1p1Parallel Computer Modelsppt1sharedSHEENA YNo ratings yet
- UNIT 2 Cloud ComputingDocument18 pagesUNIT 2 Cloud ComputingRajput ShreeyaNo ratings yet
- 21cs401 CA Unit VDocument16 pages21cs401 CA Unit VVignesh MGNo ratings yet
- Introduction Mod1Document120 pagesIntroduction Mod1SHEENA YNo ratings yet
- Module II (CC)Document125 pagesModule II (CC)Amanda DrewNo ratings yet
- Final Unit5 CO NotesDocument7 pagesFinal Unit5 CO NotesMohd Ismail GourNo ratings yet
- Unit 1 - Part - 2Document30 pagesUnit 1 - Part - 2Meet PanchalNo ratings yet
- Os Module 5Document6 pagesOs Module 5Tuhinsuvra SarkarNo ratings yet
- L13 - Modern ProcessorsDocument19 pagesL13 - Modern Processorsدانه النوفليNo ratings yet
- ModelDocument14 pagesModelASHWANI MISHRANo ratings yet
- CS-3006_3_ParallelArchitecturesDocument56 pagesCS-3006_3_ParallelArchitectureslordshen2804No ratings yet
- Parallel and distributed computingDocument16 pagesParallel and distributed computingbc210402586 HAFIZA ANIQA IRFANNo ratings yet
- Module-1 Theory of Parallelism: The State of Computing Computer Development MilestonesDocument48 pagesModule-1 Theory of Parallelism: The State of Computing Computer Development MilestonesUdupiSri groupNo ratings yet
- Parallel and Distributed ComputingDocument90 pagesParallel and Distributed ComputingWell WisherNo ratings yet
- Explicitly Parallel PlatformsDocument90 pagesExplicitly Parallel PlatformswmanjonjoNo ratings yet
- Lecture 3 - 1 Dichotomy of Parallel Computing PlatformsDocument17 pagesLecture 3 - 1 Dichotomy of Parallel Computing PlatformswmanjonjoNo ratings yet
- APznzaaBPbq19r7DttJsFJDiz6xdljQmPxg0oflqRAoyoqcN6IEEo4yrW Ck8XgHkH5PDMZIHRNz7h0ZpQWHOHwyjvO3PX93sVHvLd5fwcGETUu8XvmdTkaodNRbNrLgkDFPQZVQMfz8KHkZay30aqD0CVLA10PSummzrUt1vN32NEahcaq-m3CTYqZXjSBaBus9kPl5fj8KDKPT (1)Document80 pagesAPznzaaBPbq19r7DttJsFJDiz6xdljQmPxg0oflqRAoyoqcN6IEEo4yrW Ck8XgHkH5PDMZIHRNz7h0ZpQWHOHwyjvO3PX93sVHvLd5fwcGETUu8XvmdTkaodNRbNrLgkDFPQZVQMfz8KHkZay30aqD0CVLA10PSummzrUt1vN32NEahcaq-m3CTYqZXjSBaBus9kPl5fj8KDKPT (1)Vishal ChowdaryNo ratings yet
- Unit 7 - Parallel Processing ParadigmDocument26 pagesUnit 7 - Parallel Processing ParadigmMUHMMAD ZAID KURESHINo ratings yet
- UNIT-2 PP FlynnsClassificationDocument80 pagesUNIT-2 PP FlynnsClassificationankitupatil1No ratings yet
- (SMC), (SMP), (MPP) : Symmetric Multi-Computers Symmetric Multi-ProcessorsDocument13 pages(SMC), (SMP), (MPP) : Symmetric Multi-Computers Symmetric Multi-ProcessorsAnkit guptaNo ratings yet
- Chapter 6 Advanced TopicsDocument14 pagesChapter 6 Advanced TopicsRoshanNo ratings yet
- Slot28 CH17 ParallelProcessing 32 SlidesDocument32 pagesSlot28 CH17 ParallelProcessing 32 Slidestuan luuNo ratings yet
- ACA UNIT-5 NotesDocument15 pagesACA UNIT-5 Notespraveennegiuk07No ratings yet
- MultiprocessingDocument10 pagesMultiprocessingSurbhi YadavNo ratings yet
- Flynn ClassificationDocument6 pagesFlynn ClassificationvishwangarravikumarNo ratings yet
- Computer Organization: - by Rama Krishna Thelagathoti (M.Tech CSE From IIT Madras)Document118 pagesComputer Organization: - by Rama Krishna Thelagathoti (M.Tech CSE From IIT Madras)iamy2ramsNo ratings yet
- Lecture 10 Parallel Computing - by FQDocument29 pagesLecture 10 Parallel Computing - by FQaina syafNo ratings yet
- Os MD 4Document112 pagesOs MD 4Magneto Eric Apollyon ThornNo ratings yet
- Slot28 CH17 ParallelProcessing 32 SlidesDocument32 pagesSlot28 CH17 ParallelProcessing 32 SlidesTrương Văn TrầnNo ratings yet
- Parallel Processing:: Multiple Processor OrganizationDocument24 pagesParallel Processing:: Multiple Processor OrganizationKrishnaNo ratings yet
- Chapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesDocument41 pagesChapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesraghvendrmNo ratings yet
- Unit 1Document88 pagesUnit 1studgg78No ratings yet
- Flynn's ClassificationDocument4 pagesFlynn's ClassificationLuziana D'melloNo ratings yet
- CC UNIT-1 MaterialDocument26 pagesCC UNIT-1 Materialarvindreddy013No ratings yet
- NOTESDocument19 pagesNOTESUmer ManshaNo ratings yet
- Architecture of Parallel ComputingDocument6 pagesArchitecture of Parallel ComputingRabia YazdaniNo ratings yet
- Flynn's TaxonomyDocument6 pagesFlynn's Taxonomyvenmathimsc482No ratings yet
- Multi-Processor / Parallel ProcessingDocument12 pagesMulti-Processor / Parallel ProcessingRoy DhruboNo ratings yet
- Parallel Computer Models: PCA Chapter 1Document61 pagesParallel Computer Models: PCA Chapter 1AYUSH KUMARNo ratings yet
- Solved Assignment - Parallel ProcessingDocument29 pagesSolved Assignment - Parallel ProcessingNoor Mohd Azad63% (8)
- Lecture 3 PDCDocument21 pagesLecture 3 PDCAhsan SaeedNo ratings yet
- CA Unit IV Notes Part 1 PDFDocument17 pagesCA Unit IV Notes Part 1 PDFaarockiaabins AP - II - CSENo ratings yet
- Lec1 Introduction to Parallel Computing (2)Document40 pagesLec1 Introduction to Parallel Computing (2)mofreh hogoNo ratings yet
- Flynn's TaxonomyDocument18 pagesFlynn's TaxonomyHammad KhalilNo ratings yet
- Unit-7 Design Issues For Parallel Computers DefinitionDocument11 pagesUnit-7 Design Issues For Parallel Computers DefinitionSarbesh ChaudharyNo ratings yet
- CP4253 Map Unit IDocument31 pagesCP4253 Map Unit INivi VNo ratings yet
- Computer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignFrom EverandComputer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- Lumanti Housing ProjectDocument141 pagesLumanti Housing ProjectKiran BasuNo ratings yet
- Side Effects of Radiation TherapyDocument7 pagesSide Effects of Radiation TherapySerrano Ivan JasperNo ratings yet
- Identification Tag Ready For PrintDocument1 pageIdentification Tag Ready For PrintNAJIH SABIULLAHNo ratings yet
- Agriculture (Week1 Week4) Grade6Document91 pagesAgriculture (Week1 Week4) Grade6PIOLO LANCE SAGUNNo ratings yet
- ABAQUS CAE Workshops by TylerDocument8 pagesABAQUS CAE Workshops by TylerpvsunilNo ratings yet
- Tutorial Deadlock AnswerDocument2 pagesTutorial Deadlock Answernornajwanajib4965No ratings yet
- Matutiã - A Grezel MaeDocument1 pageMatutiã - A Grezel Maecoolmer drugstore08No ratings yet
- Je Et S Ir: AssumptionDocument6 pagesJe Et S Ir: Assumptionpawanswami324No ratings yet
- Chemistry Pr.3Document3 pagesChemistry Pr.3Bhagyesh ChaudhariNo ratings yet
- Carrier and Midea Price List On 5th March 2023Document5 pagesCarrier and Midea Price List On 5th March 2023ziad nabilNo ratings yet
- Run The System File Checker ToolDocument5 pagesRun The System File Checker ToolBojan JerotijevićNo ratings yet
- BITSCAN (Jan-Jun 2020) PDFDocument28 pagesBITSCAN (Jan-Jun 2020) PDFToyota MitsubishiNo ratings yet
- EV Question Bank Set - 1Document7 pagesEV Question Bank Set - 1Pundlik ShindeNo ratings yet
- Motorcraft 6 0L Diesel Fuel Filter Reference GuideDocument2 pagesMotorcraft 6 0L Diesel Fuel Filter Reference GuideJustin EldridgeNo ratings yet
- Invoice Discounting For ManufacturersDocument7 pagesInvoice Discounting For ManufacturersSaddam HussainNo ratings yet
- Innovative Teaching Strategies in Electrical Installations and MaintenanceDocument20 pagesInnovative Teaching Strategies in Electrical Installations and Maintenancejennifer.miranda005No ratings yet
- Temperaments ChartDocument1 pageTemperaments ChartPulchritudinous EstrellaNo ratings yet
- Nptel: Hall Ticket ForDocument1 pageNptel: Hall Ticket ForKarim ShaikNo ratings yet
- Angel Nicole P. BanaagDocument4 pagesAngel Nicole P. BanaagAnonymous 4eD3kXWNo ratings yet
- Coupon Collecting With Quotas: Russell MayDocument7 pagesCoupon Collecting With Quotas: Russell MayjohnoftheroadNo ratings yet
- General Instructions To Candidates For Online ExaminationDocument16 pagesGeneral Instructions To Candidates For Online ExaminationTashi LamaNo ratings yet
- Sony CDX-GT300MP ManualDocument2 pagesSony CDX-GT300MP ManualGujadhur PravishNo ratings yet
- Exercises (1)Document2 pagesExercises (1)harukanakamura722No ratings yet
- R3 - RM - 2020 - 023 Region-III-Official-List-of-Delegates-to-the-2020-NSPCDocument17 pagesR3 - RM - 2020 - 023 Region-III-Official-List-of-Delegates-to-the-2020-NSPCBiblioteca FilipinaNo ratings yet
- Study of Different Refrigerant Control Lab ManualDocument4 pagesStudy of Different Refrigerant Control Lab ManualMohdQasimNo ratings yet
- Medality 2024 Radiology Practice Development ReportDocument29 pagesMedality 2024 Radiology Practice Development Reportstarogalax95No ratings yet
- En 9 1 020 PNEUFIT C SeriesDocument27 pagesEn 9 1 020 PNEUFIT C SeriesPaulo YorgosNo ratings yet
- Hanbali Fiqh & Usul Class Everything You Need in One Place Dr. Ahmad Abdel-WahabDocument7 pagesHanbali Fiqh & Usul Class Everything You Need in One Place Dr. Ahmad Abdel-WahabShabab ASHNo ratings yet
- Brake Accelrator KBI ManualDocument12 pagesBrake Accelrator KBI Manualcnwhqrs.scrlyNo ratings yet