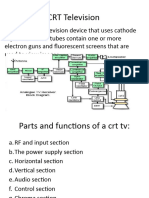
Chapter 5
Chapter 5
Download as ppt, pdf, or txt
You might also like
- Otis PDFDocument11 pagesOtis PDFJones LakerNo ratings yet
- Chapter 1Document44 pagesChapter 1Tseagaye BiresawNo ratings yet
- Chapter 1 - Query Processing and OptimizationDocument62 pagesChapter 1 - Query Processing and Optimizationbekibura1No ratings yet
- CH - 2 Query ProcessDocument44 pagesCH - 2 Query ProcessfiraolfroNo ratings yet
- Query ProcessingDocument3 pagesQuery ProcessingNiroj ThapaNo ratings yet
- Query Processing in DBMSDocument22 pagesQuery Processing in DBMSPalak RathoreNo ratings yet
- Query ProcessingDocument5 pagesQuery Processinganon_189503955No ratings yet
- Query ProcessingDocument15 pagesQuery Processingmusikmania0% (1)
- Chapter 2 Querry ProccessingDocument7 pagesChapter 2 Querry ProccessingMusariri TalentNo ratings yet
- Adir QBDocument27 pagesAdir QBAayush galaNo ratings yet
- ADBMS Chapter OneDocument21 pagesADBMS Chapter OneNaomi AmareNo ratings yet
- Query Processing and Optimization: Chapter - 2Document42 pagesQuery Processing and Optimization: Chapter - 2jaf42747No ratings yet
- CH - 1 Query Process SWDocument43 pagesCH - 1 Query Process SWfiraolfroNo ratings yet
- Unit 3 Notes UDS23201J Query ProcessingDocument38 pagesUnit 3 Notes UDS23201J Query Processingvashu150105No ratings yet
- Query Processing and OptimizationDocument24 pagesQuery Processing and OptimizationFazal MaharNo ratings yet
- Query Optimization: Admas University, Advanced DBMS Lecture NoteDocument5 pagesQuery Optimization: Admas University, Advanced DBMS Lecture NoteLubadri LmNo ratings yet
- Ivunit Query ProcessingDocument12 pagesIvunit Query ProcessingKeshava VarmaNo ratings yet
- Rdbms AssignmentDocument12 pagesRdbms Assignmentncngl2019No ratings yet
- Advance Database Management System: Unit - 2 .Query Processing and OptimizationDocument38 pagesAdvance Database Management System: Unit - 2 .Query Processing and OptimizationshikhroxNo ratings yet
- FALLSEM2023 24 - BCSE302L - TH - VL2023240100776 - 2023 06 16 - Reference Material I 2Document41 pagesFALLSEM2023 24 - BCSE302L - TH - VL2023240100776 - 2023 06 16 - Reference Material I 2Suryadevara Meghana Chakravarthi 21BCB0125No ratings yet
- Chapter 2 - Query OptimizationDocument40 pagesChapter 2 - Query Optimizationkasutaye192No ratings yet
- Cosc2072: Advanced Database Systems: Chapter Two: Query Processing and OptimizationDocument80 pagesCosc2072: Advanced Database Systems: Chapter Two: Query Processing and OptimizationAni Nimoona DhaNo ratings yet
- AMSALDocument58 pagesAMSALmebra tatekNo ratings yet
- SQL InterviewDocument9 pagesSQL Interviewjayadeepthiyamasani91No ratings yet
- Oracle Performance Tuning Interview QuestionsDocument7 pagesOracle Performance Tuning Interview QuestionsJean Jacques Nkuitche NzokouNo ratings yet
- ETL Transformations Performance OptimizationDocument7 pagesETL Transformations Performance OptimizationInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- ADBChapter 1Document32 pagesADBChapter 1abenezer012000No ratings yet
- Query Processing and OptimizationDocument28 pagesQuery Processing and OptimizationLubadri LmNo ratings yet
- Heuristic-Based Query OptimizationDocument6 pagesHeuristic-Based Query OptimizationGowri IlayarajaNo ratings yet
- Presentation9 - Query Processing and Query Optimization in DBMSDocument36 pagesPresentation9 - Query Processing and Query Optimization in DBMSsatyam singhNo ratings yet
- DDBMS-Chapter-4-SE-LectureNote (Version 1)Document11 pagesDDBMS-Chapter-4-SE-LectureNote (Version 1)davegerimNo ratings yet
- ADE Unit-1: Entity Relational ModelDocument19 pagesADE Unit-1: Entity Relational ModelPradeepNo ratings yet
- Adbms NotesDocument50 pagesAdbms Notesxidita3483No ratings yet
- Chapter 13: Query ProcessingDocument25 pagesChapter 13: Query ProcessingkrishnaNo ratings yet
- RDBMS Unit-VDocument28 pagesRDBMS Unit-Vvinoth kumarNo ratings yet
- Querry OptimizationDocument13 pagesQuerry Optimizationnikunja.mca016-24No ratings yet
- Unit 6Document34 pagesUnit 6Ghanashyam BkNo ratings yet
- 4.query Processing and OptimizationDocument5 pages4.query Processing and OptimizationBHAVESHNo ratings yet
- Query ProcessingDocument20 pagesQuery ProcessingAmanpreet DuttaNo ratings yet
- Unit 2Document48 pagesUnit 2rodsingle948No ratings yet
- Perofrmance and Indexes Discussion Questions Solutions PDFDocument5 pagesPerofrmance and Indexes Discussion Questions Solutions PDFbmaksNo ratings yet
- DBMSDocument24 pagesDBMSDimpal SayareNo ratings yet
- Bca3020 Unit 11 SLMDocument22 pagesBca3020 Unit 11 SLMJignesh PatelNo ratings yet
- ADB Chapter 2Document40 pagesADB Chapter 2anwarsirajfeyeraNo ratings yet
- Chapter 4 Query OptimizationDocument35 pagesChapter 4 Query Optimizationanon_494993240No ratings yet
- Query Processing OptimizationDocument38 pagesQuery Processing OptimizationBalaram RathNo ratings yet
- Advaced DB U1Document48 pagesAdvaced DB U1genawmigo20No ratings yet
- Query Proc NotesDocument10 pagesQuery Proc NotesPrem Bahadur KcNo ratings yet
- Unit 4Document24 pagesUnit 4BhagyaNo ratings yet
- IM Ch11 DB Performance Tuning Ed12Document17 pagesIM Ch11 DB Performance Tuning Ed12MohsinNo ratings yet
- Ch-2 Query Processing and OptimizationDocument21 pagesCh-2 Query Processing and Optimizationsefuasfaw021No ratings yet
- 36-Module-4 Query Optimization-16-03-2024Document6 pages36-Module-4 Query Optimization-16-03-2024d.nitin110804No ratings yet
- Teradata Performance OptimizationDocument20 pagesTeradata Performance OptimizationtanikantiNo ratings yet
- Chapter - 1 - Query OptimizationDocument38 pagesChapter - 1 - Query Optimizationmaki ababiNo ratings yet
- Data Mining AssignmentDocument11 pagesData Mining AssignmentPargatSidhu0% (1)
- DatabaseDocument4 pagesDatabaseprajwolsubedim1No ratings yet
- Ans: A: 1. Describe The Following: Dimensional ModelDocument8 pagesAns: A: 1. Describe The Following: Dimensional ModelAnil KumarNo ratings yet
- Smart TVDocument20 pagesSmart TVnat yesuNo ratings yet
- Day 3 - Fundamental Data Structures IDocument50 pagesDay 3 - Fundamental Data Structures Inat yesuNo ratings yet
- Day 1 - Intro To DSADocument20 pagesDay 1 - Intro To DSAnat yesuNo ratings yet
- Javascript BasicsDocument116 pagesJavascript Basicsnat yesuNo ratings yet
- HTML LAB TopicsDocument78 pagesHTML LAB Topicsnat yesuNo ratings yet
- Introduction To HTMLDocument61 pagesIntroduction To HTMLnat yesuNo ratings yet
- Introduction To Cascading Style Sheet Part IIIDocument149 pagesIntroduction To Cascading Style Sheet Part IIInat yesuNo ratings yet
- CRT TelevisionDocument19 pagesCRT Televisionnat yesuNo ratings yet
- Chapter 1Document42 pagesChapter 1nat yesuNo ratings yet
- Microwave TubesDocument21 pagesMicrowave Tubesnat yesuNo ratings yet
- Chapter 7 - FINAL Resource Management For InclusionDocument12 pagesChapter 7 - FINAL Resource Management For Inclusionnat yesuNo ratings yet
- Database Further MysqlDocument32 pagesDatabase Further Mysqlnat yesuNo ratings yet
- Project Proposal Form (Edexcel) 2Document3 pagesProject Proposal Form (Edexcel) 2Максим КарплюкNo ratings yet
- VulbraflexDocument11 pagesVulbraflexFernando BragancaNo ratings yet
- 12 Predictions for the Future of Technology - Vinod Khosla - TED - 英文 (自動產生) ? 中文(繁體) (雙語)Document6 pages12 Predictions for the Future of Technology - Vinod Khosla - TED - 英文 (自動產生) ? 中文(繁體) (雙語)abcde830601No ratings yet
- Linear Programming - Graphical MethodDocument10 pagesLinear Programming - Graphical MethodVonreev OntoyNo ratings yet
- SPLK-1002.prepaway - Premium.exam.64q: Number: SPLK-1002 Passing Score: 800 Time Limit: 120 Min File Version: 1.0Document19 pagesSPLK-1002.prepaway - Premium.exam.64q: Number: SPLK-1002 Passing Score: 800 Time Limit: 120 Min File Version: 1.0IslamMohamedNo ratings yet
- Lab 2 - Interfacing To Switches and LED's ObjectivesDocument12 pagesLab 2 - Interfacing To Switches and LED's ObjectivesidkNo ratings yet
- Mini Ice PlantDocument3 pagesMini Ice PlantGemma Gamolo Buntag100% (3)
- Presentation GPT 4Document25 pagesPresentation GPT 4Francisco García100% (1)
- Hoja de Datos Luminaria Holophane MongooseDocument7 pagesHoja de Datos Luminaria Holophane MongooseCarlos HernándezNo ratings yet
- Algorithms and Data Structures-Searching AlgorithmsDocument15 pagesAlgorithms and Data Structures-Searching AlgorithmsTadiwanashe GanyaNo ratings yet
- Attachment-4 Bill of QuantityDocument1 pageAttachment-4 Bill of QuantitysparkCENo ratings yet
- 4 - 2electricalDocument72 pages4 - 2electricalSang TranNo ratings yet
- Model 590 Control Valves: Technical Sales BulletinDocument12 pagesModel 590 Control Valves: Technical Sales BulletinRyan DuhonNo ratings yet
- Erp IntroductionDocument6 pagesErp IntroductionNeelakshi srivastavaNo ratings yet
- 01 Logic1Document18 pages01 Logic1Nisa FatimaNo ratings yet
- Using OpenBSD With VDSLDocument4 pagesUsing OpenBSD With VDSLtiemenwerkman3540No ratings yet
- Rainastar Sinchai Marmat SAMBHARDocument10 pagesRainastar Sinchai Marmat SAMBHARLaxu KhanalNo ratings yet
- LabWare 8 BrochureDocument8 pagesLabWare 8 BrochureLAURA SOFIA JIMENEZ GUTIERRENo ratings yet
- Proposal Template-2Document4 pagesProposal Template-2Luis Gabriel VasquezNo ratings yet
- COTI Guide PDFDocument133 pagesCOTI Guide PDFmysteriousNo ratings yet
- Microsoft and AV QuotationDocument55 pagesMicrosoft and AV QuotationConstanza PérezNo ratings yet
- AngularjsDocument34 pagesAngularjsCosmin PopescuNo ratings yet
- Modeling and Simulation of HVDC - Minxiao Han, Aniruddha M. GoleDocument367 pagesModeling and Simulation of HVDC - Minxiao Han, Aniruddha M. GoleHuy Thông Nguyễn100% (1)
- Internet of Energy - Opportunities, Applications, Architectures and Challenges in Smart IndustriesDocument14 pagesInternet of Energy - Opportunities, Applications, Architectures and Challenges in Smart IndustriesDaniel BernalNo ratings yet
- ACP Revit StructureDocument2 pagesACP Revit StructureparthibanNo ratings yet
- Comfort Control TAC Installation InstructionsDocument28 pagesComfort Control TAC Installation InstructionsANo ratings yet
- LERIS Online Step by Step Procedure v5Document31 pagesLERIS Online Step by Step Procedure v5boombayaNo ratings yet
- Lifepak CR PlusDocument58 pagesLifepak CR Plusariel urquizoNo ratings yet
- AC Offshore Substation - For BiginnersDocument52 pagesAC Offshore Substation - For BiginnersArun dasNo ratings yet