Unit 4
Unit 4
Download as pptx, pdf, or txt
You might also like
- How To Be Classy PDFDocument182 pagesHow To Be Classy PDFPop100% (35)
- Written - Assignment01 - Pushpinder KaurDocument6 pagesWritten - Assignment01 - Pushpinder KaurPushpinder KaurNo ratings yet
- Medici Godfathers of The RenaissanceDocument17 pagesMedici Godfathers of The RenaissanceopoplNo ratings yet
- Dream Catcher Lesson PlanDocument6 pagesDream Catcher Lesson Plansarah_skidmore1206100% (4)
- Decent Work Employment and Transcultural Nursing NCM 120: Ma. Esperanza E. Reavon, RN, ManDocument41 pagesDecent Work Employment and Transcultural Nursing NCM 120: Ma. Esperanza E. Reavon, RN, ManMa. Esperanza C. Eijansantos-Reavon100% (2)
- Getting An Overview of Big Data (Module1)Document58 pagesGetting An Overview of Big Data (Module1)Nihal KocheNo ratings yet
- MergeResult 2024 12 01 08 49 35Document30 pagesMergeResult 2024 12 01 08 49 35Manpreet SinghNo ratings yet
- Big_Data_Analytics_1718265256Document43 pagesBig_Data_Analytics_1718265256Evelyn JenNo ratings yet
- Big Data Analytics - Unit 1Document43 pagesBig Data Analytics - Unit 1Johan TorresNo ratings yet
- Module 04 BaDocument45 pagesModule 04 BaashokmlplyNo ratings yet
- BDA NotesDocument96 pagesBDA NotesPulkit DesaiNo ratings yet
- Sem Csen1301Document12 pagesSem Csen1301pullisaipriya232No ratings yet
- BDA Unit 1Document22 pagesBDA Unit 1pl.babyshalini palanisamyNo ratings yet
- Big - Data Unit-1Document33 pagesBig - Data Unit-1Tulshiram Kamble100% (2)
- BDA - Unit-IDocument35 pagesBDA - Unit-IJerald RubanNo ratings yet
- Data For Business Analytics Unit 2Document23 pagesData For Business Analytics Unit 2iemhardikNo ratings yet
- BIG DATA Technology: SubtitleDocument34 pagesBIG DATA Technology: SubtitleDhavan KumarNo ratings yet
- Big Data AnalyticsDocument14 pagesBig Data Analyticsblackpink7010No ratings yet
- Data Science Vs Big DataDocument34 pagesData Science Vs Big Datapoi.tamrakarNo ratings yet
- Unit 1 Big Data NotesDocument40 pagesUnit 1 Big Data NotesKeerthivasanNo ratings yet
- Computer Networks TCPDocument48 pagesComputer Networks TCPtesthelsingNo ratings yet
- Big DataDocument16 pagesBig Datasaadbeg12No ratings yet
- Lecture01-Main Motivation and Drivers For Big Data AdoptionDocument16 pagesLecture01-Main Motivation and Drivers For Big Data AdoptionjhonjairoazaNo ratings yet
- Big Data - Module 1Document35 pagesBig Data - Module 1JagadeeshNo ratings yet
- ABSTRACTDocument9 pagesABSTRACTanchalsingh8291No ratings yet
- Now To Be DataDocument16 pagesNow To Be Datasaadbeg12No ratings yet
- Unit 1Document61 pagesUnit 1Keshav BagaadeNo ratings yet
- Business AnalyticsDocument46 pagesBusiness AnalyticsMuhammed Althaf VK100% (4)
- Big Data: Made By: Harshita Salian 17038 Syed Khadija Rizvi 17049 Sayyed Alfiya 17041 Rahul Masam 17028 Deepak Pal 17033Document12 pagesBig Data: Made By: Harshita Salian 17038 Syed Khadija Rizvi 17049 Sayyed Alfiya 17041 Rahul Masam 17028 Deepak Pal 17033Harshita SalianNo ratings yet
- Bda CHP1Document83 pagesBda CHP1Isam SyedNo ratings yet
- ISP500 Topic 3 Data and Knowledge Management - ch5Document23 pagesISP500 Topic 3 Data and Knowledge Management - ch5Mr. NNo ratings yet
- BDA Unit 1Document50 pagesBDA Unit 1Alekhya AbbarajuNo ratings yet
- Unit 1 Introduction: Data Science and Big Data: SyllabusDocument38 pagesUnit 1 Introduction: Data Science and Big Data: Syllabussunandanpt21020No ratings yet
- Big Data Analytics Unit Test-I Answers BankDocument10 pagesBig Data Analytics Unit Test-I Answers Bankvishal phuleNo ratings yet
- Module-1-Introduction To BigData PlatformDocument21 pagesModule-1-Introduction To BigData PlatformAswathy V SNo ratings yet
- Unit 5Document63 pagesUnit 5paridhiagarwal129No ratings yet
- Big DataDocument11 pagesBig DatawilsongadekarNo ratings yet
- Unit I-KCS-061Document42 pagesUnit I-KCS-061aggarwalmohit813No ratings yet
- Insights Into Big Data: An Industrial PerspectiveDocument52 pagesInsights Into Big Data: An Industrial PerspectivevenkymitNo ratings yet
- Unit - 5 (Data Science)Document25 pagesUnit - 5 (Data Science)sanskar26cs114No ratings yet
- Unit - I - Types of Digital DataDocument45 pagesUnit - I - Types of Digital DatahekhodkeNo ratings yet
- ISP500 Topic 3 Data and Knowledge Management - ch5Document23 pagesISP500 Topic 3 Data and Knowledge Management - ch5Stärk 10No ratings yet
- Big Data: Presented by J.Jitendra KumarDocument14 pagesBig Data: Presented by J.Jitendra KumarJitendra KumarNo ratings yet
- BigData Unit-1Document72 pagesBigData Unit-1Ravi YadavNo ratings yet
- Unit 1 Data Science and Big DataDocument23 pagesUnit 1 Data Science and Big DataPranav Sai AdityaNo ratings yet
- 117769Document20 pages117769AakashNo ratings yet
- Unit TenDocument50 pagesUnit TenManag LimbuNo ratings yet
- 2403RES29 - Hemant Choudhary - CS546 - Assignment - 1Document14 pages2403RES29 - Hemant Choudhary - CS546 - Assignment - 1Hemant ChoudharyNo ratings yet
- Chapter5-DATA AND KNOWLEDGE MANAGEMENTDocument39 pagesChapter5-DATA AND KNOWLEDGE MANAGEMENTyoshellyNo ratings yet
- Big Data Cat 1Document11 pagesBig Data Cat 1santhoshkumar1245268No ratings yet
- Big Data Analytics 1Document22 pagesBig Data Analytics 1VILLANUEVANo ratings yet
- Big Data-1Document61 pagesBig Data-1kesri nathNo ratings yet
- Business Analytics & ApplicationsDocument21 pagesBusiness Analytics & ApplicationsAbhishek DubeyNo ratings yet
- BigdataDocument12 pagesBigdataTGOWNo ratings yet
- 1.big Data and Its ImportanceDocument17 pages1.big Data and Its ImportanceZubia MuqtadirNo ratings yet
- Big DataDocument19 pagesBig DataAnnalyn Manangan RaguiniNo ratings yet
- Big Data AnalyticsDocument73 pagesBig Data Analyticsayushgoud1234No ratings yet
- Introduction To Data AnalyticsDocument63 pagesIntroduction To Data Analyticsmgs181101No ratings yet
- Unit-III CC&BD Cs62 AbDocument85 pagesUnit-III CC&BD Cs62 Abdhanrajpandya26No ratings yet
- Architectures of Big DataDocument27 pagesArchitectures of Big DataPalak GarhwaniNo ratings yet
- WINSEM2023-24 BCSE206L TH VL2023240501787 2024-01-29 Reference-Material-IDocument53 pagesWINSEM2023-24 BCSE206L TH VL2023240501787 2024-01-29 Reference-Material-Iriya bansalNo ratings yet
- (Ca) Bda Unit-IDocument10 pages(Ca) Bda Unit-ILakshmi LakshminarayanaNo ratings yet
- Big Data-IntroductionDocument14 pagesBig Data-IntroductiontripathineeharikaNo ratings yet
- UNIT I BIG DATA Extra ContentDocument15 pagesUNIT I BIG DATA Extra Contentantush.fredinaNo ratings yet
- For Polymer Asphaltic Concrete and Specification For Porous Asphalt Were Published in December 2008. You May FaxDocument1 pageFor Polymer Asphaltic Concrete and Specification For Porous Asphalt Were Published in December 2008. You May FaxPigmy LeeNo ratings yet
- Aspirated Unaspirated FlapDocument4 pagesAspirated Unaspirated FlapShanti.R. AfrilyaNo ratings yet
- History of Pakistan: The Massacre of Muslim Refugees in IndiaDocument2 pagesHistory of Pakistan: The Massacre of Muslim Refugees in IndiaMirza Naveed AkhtarNo ratings yet
- Biographical EssayDocument2 pagesBiographical EssayNoel Pelenio Billedo100% (1)
- RayovacDocument9 pagesRayovacVinayak Bhat100% (1)
- Atomic BombingsDocument12 pagesAtomic BombingsMethira DulsithNo ratings yet
- TUTORIAL - AIS615.CHAPTER 1 To CHAPTER3Document3 pagesTUTORIAL - AIS615.CHAPTER 1 To CHAPTER3Mon Luffy100% (1)
- Communication, Positioning, Consumer Behaviour, Price, Market Research, ProductDocument16 pagesCommunication, Positioning, Consumer Behaviour, Price, Market Research, ProductDuy TrácNo ratings yet
- Alfredo Mallari Vs CADocument4 pagesAlfredo Mallari Vs CACheezy ChinNo ratings yet
- SourcesDocument40 pagesSourcesKevin Jairo Santiago100% (1)
- Project Female Figures in LiteratureDocument43 pagesProject Female Figures in Literatureshaymaa zuhairNo ratings yet
- Food Expenses: Not IncludedDocument3 pagesFood Expenses: Not IncludedGisselle PauloNo ratings yet
- G.R. No. L-18924 October 19, 1922 THE People OF THE Philippine ISLANDS, Plaintiff-Appellant, WONG CHENG (Alias WONG CHUN), Defendant-AppelleeDocument2 pagesG.R. No. L-18924 October 19, 1922 THE People OF THE Philippine ISLANDS, Plaintiff-Appellant, WONG CHENG (Alias WONG CHUN), Defendant-Appelleenil qawNo ratings yet
- El Diario Secreto de Adrian MoleDocument2 pagesEl Diario Secreto de Adrian Molenacholj85No ratings yet
- Dimaandal v. COA (Full Text)Document5 pagesDimaandal v. COA (Full Text)ArahbellsNo ratings yet
- Ap EapcetDocument2 pagesAp EapcetAvinash PanigrahiNo ratings yet
- Prizes and BursariesDocument3 pagesPrizes and Bursariesjayanthi89No ratings yet
- Florida Department of Juvenile Justice - Roadmap To System ExcellenceDocument96 pagesFlorida Department of Juvenile Justice - Roadmap To System ExcellenceWJCT NewsNo ratings yet
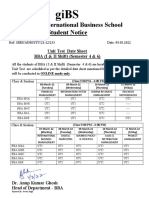
- Gitarattan International Business School Student Notice: Unit Test Date Sheet BBA (I & II Shift) (Semester 4 & 6)Document1 pageGitarattan International Business School Student Notice: Unit Test Date Sheet BBA (I & II Shift) (Semester 4 & 6)anshNo ratings yet
- Driver Registration FormDocument8 pagesDriver Registration FormRoxana MelnicuNo ratings yet
- Skkc3343 Assignment 1-2019Document2 pagesSkkc3343 Assignment 1-2019Yi Wen Yap100% (1)
- Matu - A Quaint Town With Stories To TellDocument5 pagesMatu - A Quaint Town With Stories To TellBoon Siong BoonNo ratings yet
- AccountStatement Report 6022228882 06122022 17 27Document2 pagesAccountStatement Report 6022228882 06122022 17 27Jaya ShindeNo ratings yet
- 04.responsible Project Management - Beyond The Triple ConstraintsDocument8 pages04.responsible Project Management - Beyond The Triple ConstraintsIgor EnnesNo ratings yet
- An Overview of The Debate On The African State: Masahisa KawabataDocument74 pagesAn Overview of The Debate On The African State: Masahisa KawabataLucrarilicentaNo ratings yet