RL Class Mtech
RL Class Mtech
Download as pptx, pdf, or txt
You might also like
- Logical Security SOP SampleDocument13 pagesLogical Security SOP SampleAnton Mymrikov0% (2)
- Basics of Piping EngineeringDocument43 pagesBasics of Piping EngineeringAyush100% (1)
- A Summer Training Project Report On "Retail Store Operations"Document102 pagesA Summer Training Project Report On "Retail Store Operations"yatin rajput0% (1)
- ML Unit-4 - RTUDocument18 pagesML Unit-4 - RTUvishakhasahu0001No ratings yet
- Unit 5 Deep LearningDocument24 pagesUnit 5 Deep LearningPraveen KumarNo ratings yet
- RL Vishnu SankarDocument26 pagesRL Vishnu SankarVishnu Vgrp1No ratings yet
- Unit 1Document18 pagesUnit 1Mohamed riyanNo ratings yet
- lecture 9 Reiforcement learning (1)Document29 pageslecture 9 Reiforcement learning (1)abdallahsirmajor02No ratings yet
- Reinforcement LearningDocument32 pagesReinforcement Learningvedang maheshwariNo ratings yet
- Reinforcement LearningDocument25 pagesReinforcement LearningKartik Singh100% (1)
- RL EseDocument7 pagesRL EseShrishti BhasinNo ratings yet
- Unit 5Document45 pagesUnit 5randyyNo ratings yet
- rl-3Document31 pagesrl-3Gangadhari MouneeshNo ratings yet
- Q LearningDocument38 pagesQ LearningJeffy ShinyNo ratings yet
- L-14 - Reinforcement-L-d-07062024-111949amDocument22 pagesL-14 - Reinforcement-L-d-07062024-111949amBahadar AyazNo ratings yet
- ML Assignment 2Document6 pagesML Assignment 2221225No ratings yet
- Reinforcement LearningDocument10 pagesReinforcement Learningcrazybruce2024No ratings yet
- Lecture 3.1 AMLDocument65 pagesLecture 3.1 AMLVivek SreekarNo ratings yet
- Unit-5 Part C 1) Explain The Q Function and Q Learning Algorithm Assuming Deterministic Rewards and Actions With Example. Ans)Document11 pagesUnit-5 Part C 1) Explain The Q Function and Q Learning Algorithm Assuming Deterministic Rewards and Actions With Example. Ans)QUARREL CREATIONSNo ratings yet
- Unit-3 Unit-3 RL Problems,Prediction and Control p 241111 181426Document15 pagesUnit-3 Unit-3 RL Problems,Prediction and Control p 241111 181426Gopala KarthikNo ratings yet
- ML - Unit 3 - Part IIDocument51 pagesML - Unit 3 - Part IIdevipriya kondaNo ratings yet
- Artificial Intelligence: Computer Science & Engineering, Khulna UniversityDocument30 pagesArtificial Intelligence: Computer Science & Engineering, Khulna Universityrazi.d6968No ratings yet
- Unit 3Document12 pagesUnit 3karthikanegofficialNo ratings yet
- ML Unit 5Document29 pagesML Unit 5226y1a6760No ratings yet
- Unit-8 - Reinforcement LearningDocument52 pagesUnit-8 - Reinforcement Learninghefeke8164No ratings yet
- Reinforcement Learning by Comparing Immediate Reward: Punit Pandey DeepshikhapandeyDocument5 pagesReinforcement Learning by Comparing Immediate Reward: Punit Pandey DeepshikhapandeyBanifisabilillah Ibnu HashimNo ratings yet
- Reinforcement LearningDocument8 pagesReinforcement Learningashima.aryaNo ratings yet
- What Is Reinforcement LearningDocument12 pagesWhat Is Reinforcement LearningranamzeeshanNo ratings yet
- What Is Reinforcement LearningDocument5 pagesWhat Is Reinforcement LearningSS SerialNo ratings yet
- Reinforcement Learning: Karan KathpaliaDocument80 pagesReinforcement Learning: Karan KathpaliaRaghuNo ratings yet
- Chapter 3Document14 pagesChapter 3yigiblirujjjrxpthjNo ratings yet
- Unit VDocument24 pagesUnit Vbushrajameel88100% (1)
- unit 3 aiDocument5 pagesunit 3 aiklr289020No ratings yet
- DL Unit 6 QP SolutionDocument15 pagesDL Unit 6 QP SolutiondivyaniofficalNo ratings yet
- OT Model Question AnswersDocument4 pagesOT Model Question Answersroushan0324No ratings yet
- Unit 5 NotesDocument9 pagesUnit 5 Notesraneemjihan5No ratings yet
- Report On Reinforcement LearningDocument26 pagesReport On Reinforcement LearningDr.Srinivasa Rao K.V.NNo ratings yet
- Reinforcement LearningDocument64 pagesReinforcement LearningChandra Prakash Meena100% (1)
- lecture doubtsDocument2 pageslecture doubtssaranveluNo ratings yet
- Unit 5 - Reinforcement LearningDocument15 pagesUnit 5 - Reinforcement Learningananyasharma4014No ratings yet
- Reinforcement Learning: Russell and Norvig: CH 21Document16 pagesReinforcement Learning: Russell and Norvig: CH 21ZuzarNo ratings yet
- 404-BA-chapter IVDocument70 pages404-BA-chapter IVParag PardeshiNo ratings yet
- Reinforcement Learning - BasicsDocument7 pagesReinforcement Learning - Basicswh0am1No ratings yet
- 5.5 Reinforcement LearningDocument5 pages5.5 Reinforcement LearningROHIT DASNo ratings yet
- 4.1 Reinforcement Learning 2Document31 pages4.1 Reinforcement Learning 2NikhilNo ratings yet
- ML_Unit-4Document10 pagesML_Unit-4vishal soniNo ratings yet
- AI Unit3 Part 1Document5 pagesAI Unit3 Part 122jn1a05c1No ratings yet
- DD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionDocument9 pagesDD2431 Machine Learning Lab 4: Reinforcement Learning Python VersionbboyvnNo ratings yet
- Winter Semester 2023-24_CSE4037_ETH_AP2023246000594_2024-01-05_Reference-Material-IDocument35 pagesWinter Semester 2023-24_CSE4037_ETH_AP2023246000594_2024-01-05_Reference-Material-IhNo ratings yet
- Untitled documentDocument11 pagesUntitled documenteeshnaugraiyaNo ratings yet
- Reinforcement Learning2ADocument88 pagesReinforcement Learning2Ajiriraymond65No ratings yet
- Unit3Document13 pagesUnit3Sahil PhogatNo ratings yet
- 5.4-Reinforcement Learning-Part2-Learning-AlgorithmsDocument15 pages5.4-Reinforcement Learning-Part2-Learning-Algorithmspolinati.vinesh2023No ratings yet
- Solution to Assignment_4_Dynamic ProgrammingDocument11 pagesSolution to Assignment_4_Dynamic ProgrammingARNYNo ratings yet
- SectionsDocument76 pagesSectionskerolosnaseef555No ratings yet
- RLDocument9 pagesRLtoufeeq.s152003No ratings yet
- ML Unit 5 (ChatGPT)Document17 pagesML Unit 5 (ChatGPT)Tufail DarNo ratings yet
- MDPDocument10 pagesMDP2203a52078No ratings yet
- Reinforced LearningDocument25 pagesReinforced LearningVijayalakshmi GovindarajaluNo ratings yet
- Unit 4Document7 pagesUnit 4csedept20No ratings yet
- Reinforcement Learning - Ipynb - ColaboratoryDocument7 pagesReinforcement Learning - Ipynb - Colaboratoryzb laiNo ratings yet
- cs188 sp23 Note14Document2 pagescs188 sp23 Note14sondosNo ratings yet
- Deep Learning Unit2Document43 pagesDeep Learning Unit2attackontitans.blackloverNo ratings yet
- Introduction To Deep LearningDocument34 pagesIntroduction To Deep Learningattackontitans.blackloverNo ratings yet
- Deep Learning and Its ApplicationsDocument33 pagesDeep Learning and Its Applicationsattackontitans.blackloverNo ratings yet
- FL 1Document25 pagesFL 1attackontitans.blackloverNo ratings yet
- Crude Oil CharactertistcsDocument14 pagesCrude Oil CharactertistcsJawad Munir100% (2)
- Key Marketi Per (For BekeleDocument10 pagesKey Marketi Per (For BekeleMBA SAWLACAMPUS2014No ratings yet
- Sectors of The Indian EconomyDocument20 pagesSectors of The Indian Economyapoorv.gupta6677No ratings yet
- Ca Sep 2022 Week 1Document47 pagesCa Sep 2022 Week 1debasishsahuNo ratings yet
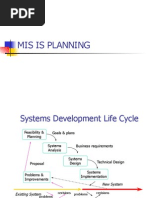
- Chapter - 3. MIS PlanningDocument38 pagesChapter - 3. MIS Planningபாவரசு. கு. நா. கவின்முருகு100% (1)
- Exam QuizzessDocument35 pagesExam QuizzessJaylord VerazonNo ratings yet
- A13 Hatchback Engine Management System System Manual For m78 CompressDocument46 pagesA13 Hatchback Engine Management System System Manual For m78 CompressDuban QuirogaNo ratings yet
- By:-Devang Gangwani and Ashish Juriani - Final Year Bpharm (2018)Document20 pagesBy:-Devang Gangwani and Ashish Juriani - Final Year Bpharm (2018)Devang GangwaniNo ratings yet
- List of Documents: 01.manufacturing SiteDocument2 pagesList of Documents: 01.manufacturing SiteShahadat Hossain TipuNo ratings yet
- Jenkins PPTDocument24 pagesJenkins PPTthecoinmaniac hodl100% (1)
- What Are Development Controls: Ar Jit Kumar Gupta ChandigarhDocument13 pagesWhat Are Development Controls: Ar Jit Kumar Gupta ChandigarhAayushi GodseNo ratings yet
- Smit Questionnaire On JewelleryDocument3 pagesSmit Questionnaire On JewelleryamitNo ratings yet
- Deploying and Updating Avaya Aura Media Server Appliance 11-7-2023Document103 pagesDeploying and Updating Avaya Aura Media Server Appliance 11-7-2023Asnake TegenawNo ratings yet
- Shimano 2015-2016 Road & MTN Bike Parts Compatibility - v029 - enDocument32 pagesShimano 2015-2016 Road & MTN Bike Parts Compatibility - v029 - enquestor4425No ratings yet
- Comprehensive Models of Cardiovascular and Respiratory Systems Their Mechanical Support and Interactions 1st Edition Marek DarowskiDocument70 pagesComprehensive Models of Cardiovascular and Respiratory Systems Their Mechanical Support and Interactions 1st Edition Marek Darowskibokeralinn100% (12)
- PBIEF (Eng) WebDocument10 pagesPBIEF (Eng) WebFayZ ZabidyNo ratings yet
- Yogyata VikasDocument11 pagesYogyata Vikasvivek1312No ratings yet
- Recoil Offgrid - Issue 55 2023 - Recoil OffgridDocument104 pagesRecoil Offgrid - Issue 55 2023 - Recoil OffgridAcraaNo ratings yet
- Stress Management TechniquesDocument4 pagesStress Management TechniquesMuhammad Hashim MemonNo ratings yet
- HYG Part Approval FormsDocument24 pagesHYG Part Approval Formsmarcos coelho100% (1)
- Sky and TelescopeDocument88 pagesSky and TelescopeJose SirittNo ratings yet
- The Guessing GameDocument106 pagesThe Guessing Gameap guptaNo ratings yet
- Cowles, Nelson CHPT 1Document32 pagesCowles, Nelson CHPT 1CharleneKronstedtNo ratings yet
- The Industrial Revolution SacDocument3 pagesThe Industrial Revolution Sacapi-190779969No ratings yet
- Project Report On Child Labour in India 2Document44 pagesProject Report On Child Labour in India 2Manza DeshmukhNo ratings yet
- Application Form XAT22068936Document3 pagesApplication Form XAT22068936Khandelwal CyclesNo ratings yet
- E.O. 337 ESB LawDocument4 pagesE.O. 337 ESB LawJames Bryan Viejo EsteleydesNo ratings yet