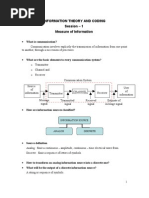
Itc Class1
Itc Class1
Download as pptx, pdf, or txt
You might also like
- TIMO-Mock-2019-Primary 6Document9 pagesTIMO-Mock-2019-Primary 6Doan Thi Luyen100% (2)
- EconometricsTest Bank Questions Chapter 3Document3 pagesEconometricsTest Bank Questions Chapter 3Ngọc Huyền100% (10)
- Information TheoryDocument30 pagesInformation TheorySuhas Ns50% (2)
- Class 7 Mathematics Percentage PDFDocument9 pagesClass 7 Mathematics Percentage PDFdinaabhiNo ratings yet
- Information TheoryDocument26 pagesInformation TheoryArighna BasakNo ratings yet
- Lecture01 02 Part1Document27 pagesLecture01 02 Part1Bunny EstronavellaNo ratings yet
- Module 1Document29 pagesModule 1Raghavendra ILNo ratings yet
- Infotheory&Coding BJS CompiledDocument91 pagesInfotheory&Coding BJS CompiledTejus PrasadNo ratings yet
- Information Theory and Coding - Chapter 2Document41 pagesInformation Theory and Coding - Chapter 2Dr. Aref Hassan Kurdali0% (1)
- Unit 4 - DC - 2023-2024Document100 pagesUnit 4 - DC - 2023-2024l22aecmanojNo ratings yet
- 21EC51_DC_Module_4Document40 pages21EC51_DC_Module_4afa.deccanNo ratings yet
- Chapter 02 Information TheoryDocument15 pagesChapter 02 Information Theorymuhabamohamed21No ratings yet
- CE NotesDocument32 pagesCE Notesece.kavitha mamcetNo ratings yet
- MIT6 02F12 Chap02Document12 pagesMIT6 02F12 Chap02gautruc408No ratings yet
- Lesson 4 Information TheoryDocument39 pagesLesson 4 Information Theorymarkangelobautista86No ratings yet
- Ec23ec4211itc PPTDocument148 pagesEc23ec4211itc PPTPrathmeshNo ratings yet
- Information Theory PDFDocument26 pagesInformation Theory PDFljjbNo ratings yet
- Information Theory FinalDocument50 pagesInformation Theory FinaltsNo ratings yet
- Lec35 - 210108062 - ZAINAB ALIDocument9 pagesLec35 - 210108062 - ZAINAB ALIvasu sainNo ratings yet
- Information Coding TechniquesDocument42 pagesInformation Coding TechniquesexcitekarthikNo ratings yet
- Unit 1 ITCDocument25 pagesUnit 1 ITCSwastikNo ratings yet
- Pres 3may 5may 9871Document11 pagesPres 3may 5may 9871sgjhrNo ratings yet
- Information Theory and Coding System: PMSCS 676 Summer 2016Document64 pagesInformation Theory and Coding System: PMSCS 676 Summer 2016sam mohaNo ratings yet
- Intro Lecture NotesDocument15 pagesIntro Lecture NotesKevin DanyNo ratings yet
- Information TheoryDocument38 pagesInformation TheoryprinceNo ratings yet
- 02 InfothDocument5 pages02 InfothTayyibNo ratings yet
- Amount of Information I Log (1/P)Document2 pagesAmount of Information I Log (1/P)NaeemrindNo ratings yet
- Information Theory CodingDocument6 pagesInformation Theory CodingAviral KediaNo ratings yet
- Intro ClassDocument19 pagesIntro ClassVanitha RNo ratings yet
- Lecture 2Document22 pagesLecture 21234 МаNo ratings yet
- Information Theory and CodingDocument84 pagesInformation Theory and CodingsonaliNo ratings yet
- Cha 02Document45 pagesCha 02muhabamohamed21No ratings yet
- DC HandoutsDocument51 pagesDC HandoutsneerajaNo ratings yet
- Ce Unit Iii PDFDocument116 pagesCe Unit Iii PDFPragna SidhireddyNo ratings yet
- Chapter 1 (A)Document30 pagesChapter 1 (A)NidhiNo ratings yet
- Information TheoryDocument41 pagesInformation Theoryvccgyugu jbuuNo ratings yet
- Lec.1n - COMM 552 Information Theory and CodingDocument25 pagesLec.1n - COMM 552 Information Theory and CodingDonia Mohammed AbdeenNo ratings yet
- Information, Entropy, and The Motivation For Source Codes: HapterDocument12 pagesInformation, Entropy, and The Motivation For Source Codes: HapterjohnNo ratings yet
- Discrete Memoryless Source FinalDocument34 pagesDiscrete Memoryless Source FinalNylNicartNo ratings yet
- Shannon's Coding Theorems: Saint Mary's College of CaliforniaDocument23 pagesShannon's Coding Theorems: Saint Mary's College of CaliforniaHguh sharmaNo ratings yet
- Notes Adc Unit 5Document25 pagesNotes Adc Unit 5Yash JadhavNo ratings yet
- Discrete Memoryless Source Final 2Document34 pagesDiscrete Memoryless Source Final 2NylNicart100% (6)
- What Is InformationDocument32 pagesWhat Is InformationYogi Jeya PrakashNo ratings yet
- Unit 5 PartialDocument116 pagesUnit 5 PartialReyan AnsariNo ratings yet
- ITCT Lab Manual 2018-19Document40 pagesITCT Lab Manual 2018-19ritesh bhandari100% (3)
- 2 marsk-ITCDocument8 pages2 marsk-ITClakshmiraniNo ratings yet
- Chapte-2 Information Theory and CodingDocument68 pagesChapte-2 Information Theory and CodingtsehaygurmessaNo ratings yet
- CH 11Document36 pagesCH 11Bkm Mizanur RahmanNo ratings yet
- Information TheoryDocument108 pagesInformation TheorySivaji KumarNo ratings yet
- ITC Module - IDocument98 pagesITC Module - IAiswarya SNo ratings yet
- IT Lec 01 (TELE Engineering)Document8 pagesIT Lec 01 (TELE Engineering)Muhammad Umair Ali KhanNo ratings yet
- ECM3701 Study Unit 8Document20 pagesECM3701 Study Unit 8Kuda ChiwandireNo ratings yet
- Lecture 1: Introduction, Entropy and ML EstimationDocument5 pagesLecture 1: Introduction, Entropy and ML EstimationRajesh KetNo ratings yet
- Week 5 Information Theory Part1Document26 pagesWeek 5 Information Theory Part1youssefmo.workNo ratings yet
- Information Entropy FundamentalsDocument19 pagesInformation Entropy Fundamentalsmaskon.alienNo ratings yet
- IAT-I Solution of 15EC54 Information Theory and Coding September 2017 by Rahul NyamangoudarDocument19 pagesIAT-I Solution of 15EC54 Information Theory and Coding September 2017 by Rahul NyamangoudarnandiniNo ratings yet
- 1Document86 pages1sanyasirevanth2005No ratings yet
- DCS Module 1Document46 pagesDCS Module 1Sudarshan GowdaNo ratings yet
- Basic Information Theory: Thinh Nguyen Oregon State UniversityDocument17 pagesBasic Information Theory: Thinh Nguyen Oregon State UniversityDeepa RangasamyNo ratings yet
- Human Proxies in Cryptographic Networks: Establishing a new direction to end-to-end encryption with the introduction of the inner envelope in the echo protocolFrom EverandHuman Proxies in Cryptographic Networks: Establishing a new direction to end-to-end encryption with the introduction of the inner envelope in the echo protocolNo ratings yet
- QuestionDocument4 pagesQuestionSrinivas BollaramNo ratings yet
- X F FX FX F / (N: Chapter 20, Page 1/29Document30 pagesX F FX FX F / (N: Chapter 20, Page 1/29Carlos SanchezNo ratings yet
- Chapter 1Document15 pagesChapter 1fabriyanaNo ratings yet
- Grade 5 Mathematics SyllabusDocument4 pagesGrade 5 Mathematics SyllabusCharm GaculaNo ratings yet
- DLP-RHEA DIADULA-Math 8Document6 pagesDLP-RHEA DIADULA-Math 8Rhea B. DiadulaNo ratings yet
- Principal Component Analysis: Jianxin WuDocument24 pagesPrincipal Component Analysis: Jianxin WuXg WuNo ratings yet
- The Rubik's Cube WorkshopDocument26 pagesThe Rubik's Cube Workshopcpt_sparkyNo ratings yet
- Rules For Rounding OffDocument4 pagesRules For Rounding OffUmathevi SubramaniamNo ratings yet
- Suest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation CommandsDocument19 pagesSuest - Seemingly Unrelated Estimation: 20 Estimation and Postestimation Commandseko abiNo ratings yet
- LUSAS Volume 2Document272 pagesLUSAS Volume 2AshutoshAparaj100% (1)
- Time Response 1Document68 pagesTime Response 1Rishabh BhargavaNo ratings yet
- The Relation Between Creativity and Students' PerformanceDocument15 pagesThe Relation Between Creativity and Students' PerformanceSyed Abdul Hakim Syed ZainuddinNo ratings yet
- MFCS Unit 1Document285 pagesMFCS Unit 1SaíTejJa PatèL100% (1)
- Q1 Math-5-Le - W5Document5 pagesQ1 Math-5-Le - W5Margy Daraway BangitNo ratings yet
- Basic Operations With FractionsDocument8 pagesBasic Operations With Fractionsber tingNo ratings yet
- M3 S3-A2 Variance and Standard Deviation Practice With AnswersDocument7 pagesM3 S3-A2 Variance and Standard Deviation Practice With AnswersKishan KumarNo ratings yet
- NCERT Solutions For Class 9 Maths Chapter 2 Exercise 2.2 (Ex 2.2)Document9 pagesNCERT Solutions For Class 9 Maths Chapter 2 Exercise 2.2 (Ex 2.2)MohitNo ratings yet
- Top 243 Pyqs of Jee Mains 2024 ChapterwiseDocument34 pagesTop 243 Pyqs of Jee Mains 2024 ChapterwiseNisargNo ratings yet
- BINOMIAL ML KhannaDocument5 pagesBINOMIAL ML KhannaPavitra KukadiyaNo ratings yet
- Personal Development Reporting Group 3 MidasDocument24 pagesPersonal Development Reporting Group 3 MidasJustine Margate LautingcoNo ratings yet
- LP - SAS Congruence Postulates Julius EDocument9 pagesLP - SAS Congruence Postulates Julius EJoel BulawanNo ratings yet
- Lecturer 4 Regression AnalysisDocument29 pagesLecturer 4 Regression AnalysisShahzad Khan100% (1)
- Final Exam Reviewer: Math 17Document2 pagesFinal Exam Reviewer: Math 17Dondee Sibulo AlejandroNo ratings yet
- Charles Poor, Relativity and The Law of GravitationDocument3 pagesCharles Poor, Relativity and The Law of Gravitationbluefenix11No ratings yet
- C++ and Object-OrientedDocument334 pagesC++ and Object-OrientedVgokulGokulNo ratings yet
- Interpreting Numeral Systems: BasesDocument16 pagesInterpreting Numeral Systems: BasesBill WangNo ratings yet