0% found this document useful (0 votes)
2 viewsLesson 10 (Simple Tests of Hypothesis)
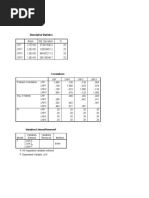
The document provides an overview of hypothesis testing, including definitions of null and alternative hypotheses, types of errors (Type I and Type II), and decision rules such as P-value and regions of acceptance. It outlines the steps in hypothesis testing and discusses the significance level, degrees of freedom, and the appropriate tests (z-test and t-test) to use based on sample size and standard deviation knowledge. The document emphasizes the importance of statistical evidence in accepting or rejecting hypotheses in research.
Uploaded by
lailaisabel.galeraCopyright
© © All Rights Reserved
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
2 viewsLesson 10 (Simple Tests of Hypothesis)
The document provides an overview of hypothesis testing, including definitions of null and alternative hypotheses, types of errors (Type I and Type II), and decision rules such as P-value and regions of acceptance. It outlines the steps in hypothesis testing and discusses the significance level, degrees of freedom, and the appropriate tests (z-test and t-test) to use based on sample size and standard deviation knowledge. The document emphasizes the importance of statistical evidence in accepting or rejecting hypotheses in research.
Uploaded by
lailaisabel.galeraCopyright
© © All Rights Reserved
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
/ 42