0% found this document useful (0 votes)
2 viewsChapter 6 Parallel and Concurrent Computing
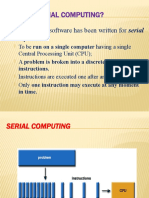
Chapter 5 of ICS 2410 discusses parallel and concurrent systems, defining key concepts such as concurrency and parallelism, and introducing Flynn's Taxonomy which classifies parallel computers into SISD, SIMD, MISD, and MIMD categories. It elaborates on the characteristics and programming methods of these systems, including multiprocessors and multicomputers, as well as various forms of parallelism like data and task parallelism. The chapter also highlights the advantages and disadvantages of SIMD and MIMD architectures.
Uploaded by
Jorams BarasaCopyright
© © All Rights Reserved
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
2 viewsChapter 6 Parallel and Concurrent Computing
Chapter 5 of ICS 2410 discusses parallel and concurrent systems, defining key concepts such as concurrency and parallelism, and introducing Flynn's Taxonomy which classifies parallel computers into SISD, SIMD, MISD, and MIMD categories. It elaborates on the characteristics and programming methods of these systems, including multiprocessors and multicomputers, as well as various forms of parallelism like data and task parallelism. The chapter also highlights the advantages and disadvantages of SIMD and MIMD architectures.
Uploaded by
Jorams BarasaCopyright
© © All Rights Reserved
Available Formats
Download as PPTX, PDF, TXT or read online on Scribd
/ 27