MySQLやSSDとかの話・前編
•Download as PPTX, PDF•
2 likes•5,589 views

瀬島 貴則(グリー株式会社)「MySQLやSSDとかの話・前編」 MySQL User Conference Tokyo 2015での登壇資料です https://www.mysql.com/news-and-events/events/mysql-user-conference-tokyo-2015/













































MySQLやSSDとかの話・前編
- 2. 自己紹介 ● わりとMySQLのひと ● 3.23.58 から使ってる ● むかしは Resource Monitoring も力入れてやってた ● ganglia & rrdcached の(たぶん)ヘビーユーザ ● 5年くらい前から使い始めた ● gmond は素のまま使ってる ● gmetad は欲しい機能がなかったので patch 書いた ● webfrontend はほぼ書き直した ● あとはひたすら python module 書いた ● ganglia じゃなくても良かったんだけど、とにかく rrdcached を使いたかった ● というわけで、自分は Monitoring を大事にする ● 一時期は Flare という OSS の bugfix などもやってた
- 3. ● 古いサーバを、新しくて性能の良いサーバに置き換えていく際、い ろいろ工夫して集約していっているのですが ● そのあたりの背景や取り組みなどについて、本日はお話しようと思 います ● オンプレミス環境の話になっちゃうんですが ● 一部は、オンプレミス環境じゃなくても応用が効くと思います ● あと、いろいろ変なことやってますが、わたしはだいたい考えただ けで ● 実働部隊は優秀な若者たちがいて、細かいところは彼らががんばっ てくれてます 本日のお話
- 4. ● 最近の HW や InnoDB の I/O 周りについて考えつつ、取り組んで おりまして ● さいきん、そのあたりを資料にまとめて slideshare で公開しており ます ● 後日、あわせて読んでいただけると、よりわかりやすいかと思いま す ● 参考: ● 5.6以前の InnoDB Flushing ● CPUに関する話 ● EthernetやCPUなどの話 本日のお話の補足資料
- 5. では はじめます
- 6. ● GREEのサービスは歴史が古い ● 古いサービスはコードが密結合な部分がある ● むかしから動いてるMySQLのサーバは、かなり sharding されてい た ● 2000年代、GREEは SAS HDD 146GB 15krpm * 4本使ったRAID10の前提で、 データベースを設計してるところが多かった ● そういうストレージでも動くように、データベースのサイズは 100-200GB以下 のものが多かった ● わたしが入社した2010年のころはよくサービスささっていて、各エ ンジニアが協力して改善してた ● アプリケーションレイヤーでがんばってもらったり、力の限り sharding したり ● わたしは、 ganglia で問題切り分けて、チューニングなどに力いれた 背景
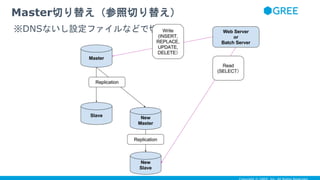
- 7. ● わたしが入社する前からノウハウがあって、ガンガンshardingして master切り替えてたそうで ● 具体的には次のように ● 先ずはサービス無停止で master 切換する方法から説明します どんなふうに sharding していたかというと
- 8. Master切り替え前
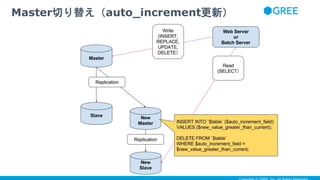
- 12. ● masterを切り替えた後に、古いmasterに対してINSERTが実行され たときのための対策 ● 例えば、次のような状態になっていれば、auto_increment の値は duplicate しない ● 旧master にINSERTすると、auto_increment のカラムは101以降の値を発番 する ● 新master にINSERTすると、auto_increment のカラムは131以降の値を発番 する ● 新masterには、master切り替えが完了するまでの間、 auto_incrementの値がduplicateしない程度の値を、 INSERT&DELETEし、 auto_increment の値を更新しておく ● master切り替えの間、更新を完全にブロックできるなら、やらなく てもいい auto_increment更新する理由
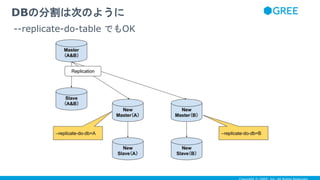
- 15. ● database や table を最初からある程度分割しておいたほうが、 -- replicate-do-db や --replicate-do-table で簡単に分割できるけど ● TRIGGER 使って table を分割することもできる ● binlog_format=’STATEMENT’ だと、 TRIGGER によって発生した binlog event は binary log に落ちないけど、 binlog_format=’ROW’ だと binary log に落ちる。 ● それらを組み合わせることによって、TRIGGER によって更新された table だけ replication することが可能 ● サービス無停止で column の追加や削除などにも対応できるので、 statement-based replication (& --log-slave-updates)& TRIGGER の組み合わせは、切り札として有用 sharding は後からでもできる
- 16. ● サーバを並べることによって、むかしより安定稼働するようにはな ったんだけど ● SSDを導入して活用したいという機運があった ● 個人的には、MySQLのボトルネックを、 CPU とメモリの問題にできるようにし ていきたい気持ちがあった。ストレージ速くなったし、Xeon は Core の数増え 続けてたし、MySQLはバージョン上がるごとに、CPUスケーラビリティを改善 し続けていたので。 そんな感じで、サービスとしては改善したんだけ ど
- 17. ● 「MySQLのバージョンが上がってN倍性能が良くなった」というの は ● (ほとんどの場合)MySQLがたくさんのCPUを活用できるようにな って、スループットが改善していってるという話だと ● InnoDB Adaptive Flushing などの改善もありますけどね ● MySQL5.5あたりから強く意識するようになった ● それまでは、とにかくHDDが圧倒的に遅かったけど ● SSDの登場により、CPUとメモリがボトルネックになるケースを、 強く意識し始めた 強く意識したのは、 MySQL5.5 あたりから
- 18. ● Fusion-IO 流行し始めたころ、調達できたのは ioDrive MLC 320GB ● 先ずは KVS に投入したり、 sharding が困難だったDBに投入した けど ● ほとんどのDBはHDDでも動くように sharding したり、アプリケー ション工夫したりしていたから、 320GB という容量は使いドコロ が難しかった ● また、当時はHDDのサーバが大量にあったので、 ioDrive に依存し た設計にしてしまうと、今後どれだけリプレースすればいいの、と いう恐れもあった ● 他社のワークロードとGREEのワークロード違うから、他社の事例は 参考にしにくかった 先ずは ioDrive 導入した
- 19. ● 当時、GREEで使ってたHDDのサーバと比較して、 ioDrive のサー バはコスト的に三倍くらいだったので、三倍以上の成果を挙げさせ たいという前提のもと ● 他のサーバの三倍以上のqueryを受けさせるために ● GREEのDBサーバに求められる要件を分析し、考えていった 三倍の仕事をさせるために
- 20. そして ひらめいた
- 21. ● GREEのアプリケーションサーバはコネクションプーリングをしてお らず、リクエストが来るごとにコネクションを張り、レスポンスを 返すごとにコネクション切っていて ● これは当時そこまで珍しくない実装だと思うけど ● 不幸なことに、共通系のDBなるものが存在して ● 特定のサービスでDBがささると、共通系のDBへのコネクションが溜 まっていって、 too many connections が発生し ● 他のサービスが巻き込まれてしまうという負の連鎖 密結合ゆえの問題を軽減しよう
- 22. (とてもざっくり)図にするとこう
- 23. ● too many connections を避けるため、HDDのサーバをたくさん並 べて、たくさんの connection 受けられるようにするとか ● 重要なサービスと内製ゲームで、slaveのクラスタを分けるとかして ● 数の暴力で解決してたんだけど かつては富豪的に解決してた
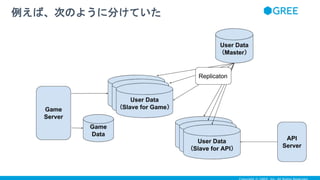
- 24. 例えば、次のように分けていた
- 26. ● ioDrive や一般的な PCI-e SSD は、 latency が異常によい ● これは現代においても言える、オンプレミス環境のメリット ● ストレージというより、「ちょっと遅いメモリ」と考える ● ちょっと遅いメモリなので、 buffer pool のヒット率を少し下げて も大丈夫 ● ピークタイムに、ユーザのデータの大半がヒットするなら、性能あまり変わらな い ● buffer pool の割当を意図的に減らして、そのぶん max_connections を増やす。具体的にはHDDのサーバの三倍以上 に上げる ● (高価だから)それほど多くないDRAM、 latency のすぐれた ioDrive という組み合わせで、HDDのサーバの三倍以上のqueryを 受けさせて、MySQLのCPU利用率引き上げる buffer pool のヒット率をうまく下げる
- 27. ● slave は O_DIRECT 使えばメモリあけられるけど ● master は binlog が page cache に乗り続けてしまう ● そこで、 buffer pool の割当減らしてる master では、 cron で posix_fadvise(2) たたいて、古い binlog は page cache からちょ っとずつ落とすようにしてます。 ● (言語はなんでもいいんですけど) いまのところ ruby で IO#advise つかって :dontneed 叩いてます。 ちょっと一工夫
- 28. ● ioDriveのサーバ1台と、HDDのサーバ三台程度を等価交換できるよ うにした ● どうしても I/O の性能が必要になった場合、 ioDrive のサーバを、 大量にある HDD のサーバ三台で置き換えることによって確保でき るように ● むかしからあるHDDなサーバの在庫も活用できるように ● これで、 ioDrive のサーバの稼働台数を増やすことが可能になった ● ioDrive たくさん使うことによって、どんなふうに故障するのかがわ かってきた ● ハードウェアは故障するまで使わないと、次のステージに踏み込めない HDDのサーバとの互換性
- 30. ● 時は流れ、NAND Flash の価格が下がり、大容量化が進んでいった ● 800GB以上のエンタープライズ仕様のSSDが普通に買えるようにな った ● これは使いたい ● 当時、容量大きいSSD使ってる他社事例それほど多くは聞かなかったので、使っ てやりたい ● いまは珍しく無いと思いますけど ● 他社が活用できてないものを活用することによって、サービスの競争力を向上さ せる ● かつて、masterはHDD、slaveは一台の物理サーバに複数mysqld 起動してSSDで集約するという他社事例あったけど、それだと運用 の手間が増えるし、 Monitoring が難しくなるなと思った NAND Flash の価格が下がってきた
- 31. ● 高い random I/O 性能というのもあるけれど ● HDDと比べて消費電力が低く、熱にも強い ● 消費電力が少ないので、それだけ一つのラックにたくさんのサーバ 積めるようになるし ● TurboBoost 使って clock あげて、CPUぶん回してやることもやり やすくなる ● かつてHDDのために使っていた電力を、より多くのCPUのために使 う ● ラック単位で電力を考えたとき、ストレージよりもCPUに多くの電 力を回すようにする そもそも、NAND Flash は何がうれしいか
- 32. ● GREEは力の限り sharding してしまっている ● SSDにリプレースしなくても動かせるDBが大量にある ● 100-200GB程度しかないDBでは、800GBのSSDは無用の長物では なかろうか? だがしかし
- 33. こんなことも あろうかと
- 34. ずいぶん 前から
- 35. 考えていたこ とがあった
- 36. そうだ
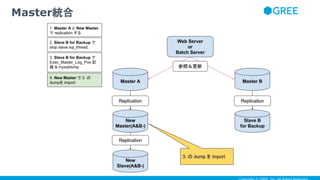
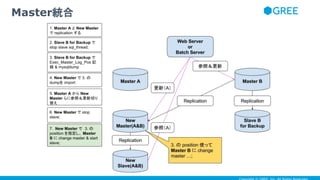
- 39. Master統合
- 40. Master統合
- 41. Master統合
- 42. Master統合
- 43. Master統合
- 44. Master統合
- 45. Master統合
- 46. Master統合
- 47. ● New Master -> New Slave 間で、全力で binary log が転送され てしまうケースがあった。ネットワークの帯域を圧迫するのがコワ イ ● いろいろ改善策はあると思うけど ● slave_compressed_protocol がお手軽でいいかも ● いつもは有効にしたくないなら、 dump 流しこむときだけ有効にし ても良い ● 動的に変更できるので便利 mysqldump の結果を流しこむときに
- 48. ● change master したあとに start slave すると、一気に binary log 転送され、一気に binary log を SQL_Thread が処理してしま うので ● ここで書いたスクリプト 使って、ちょっとずつ binary log 転送し て、ちょっとずつ binary log を適用させるように ● あと、 binary log は大き過ぎない方が良い感じ ● 弊社の場合は 200MB 程度にしてます ちょっとだけ工夫
- 50. 続きは 後編で
- 51. つづく