Crawling the internet: data science within a large engineering system
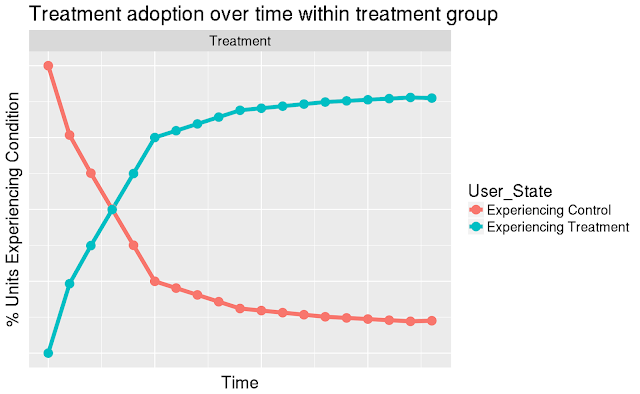
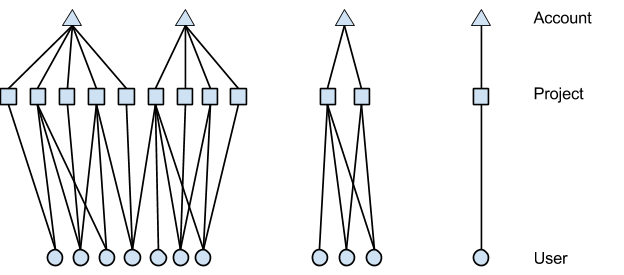
by BILL RICHOUX Critical decisions are being made continuously within large software systems. Often such decisions are the responsibility of a separate machine learning (ML) system. But there are instances when having a separate ML system is not ideal. In this blog post we describe one of these instances — Google search deciding when to check if web pages have changed. Through this example, we discuss some of the special considerations impacting a data scientist when designing solutions to improve decision-making deep within software infrastructure. Data scientists promote principled decision-making following several different arrangements. In some cases, data scientists provide executive level guidance, reporting insights and trends. Alternatively, guidance and insight may be delivered below the executive level to product managers and engineering leads, directing product feature development via metrics and A/B experiments. This post focuses on an even lower-level pattern