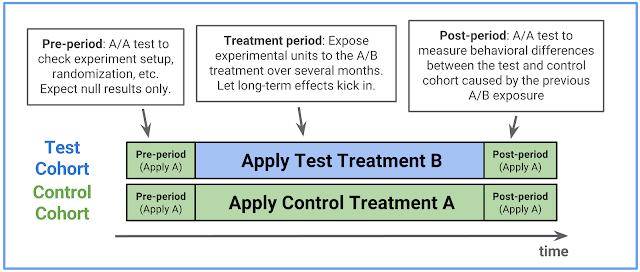
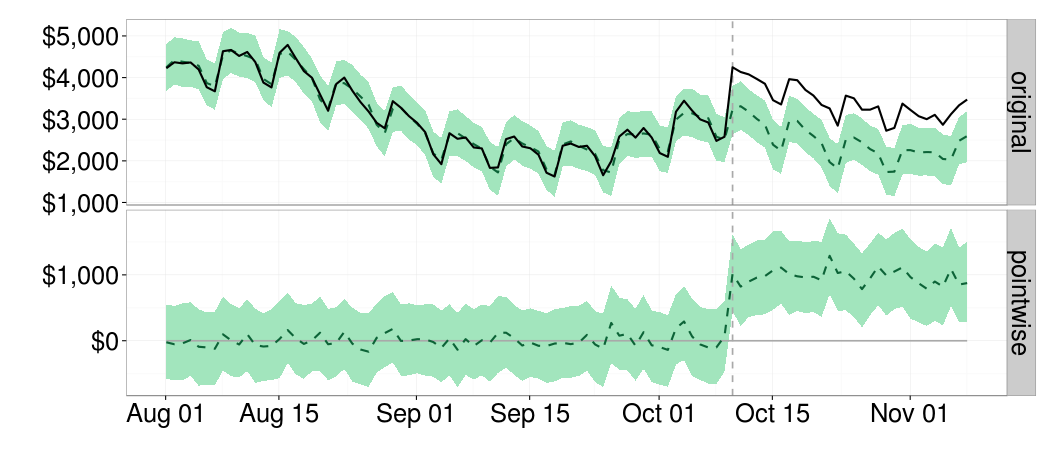
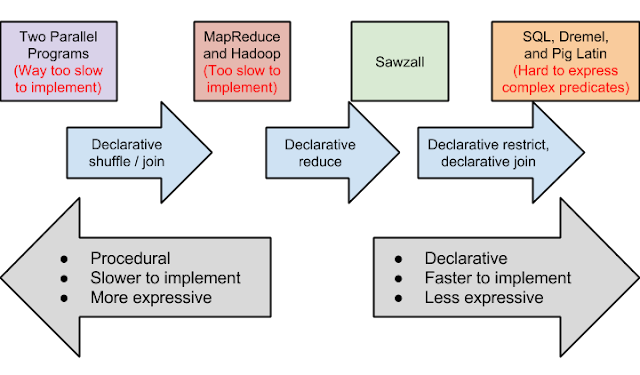
Data scientist as scientist
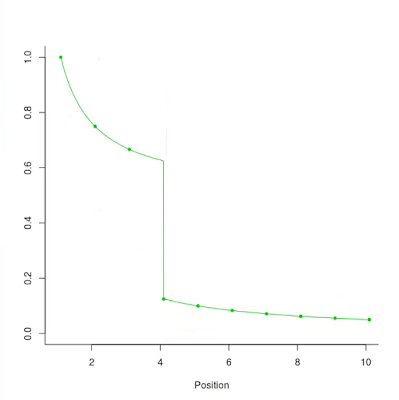
by NIALL CARDIN, OMKAR MURALIDHARAN, and AMIR NAJMI When working with complex systems or phenomena, the data scientist must often operate with incomplete and provisional understanding, even as she works to advance the state of knowledge. This is very much what scientists do. Our post describes how we arrived at recent changes to design principles for the Google search page, and thus highlights aspects of a data scientist’s role which involve practicing the scientific method. There has been debate as to whether the term “data science” is necessary. Some don’t see the point. Others argue that attaching the “science” is clear indication of a “wannabe” (think physics, chemistry, biology as opposed to computer science, social science and even creation science ). We’re not going to engage in this debate but in this blog post we do focus on science. Not science pertaining to a presumed discipline of data science but rather science of the domain within which a data scientist operates.