Single GPU Billion-scale Model Training via Parameter-Efficient Finetuning¶
![]()

As pointed out by a recent paper from Stanford Institute for Human-Centered Artificial Intelligence, AI is undergoing a paradigm shift with the rise of “foundation models”, i.e., giant models that are trained on a diverse collection of datasets generally in a self-supervised way. These foundation models, which are the key of AutoMM, can be easily adapted to down-stream applications. However, as the size of these foundation models grows, finetuning these models becomes increasingly difficult. Following is a figure from the Microsoft research blog that demonstrates the trend:
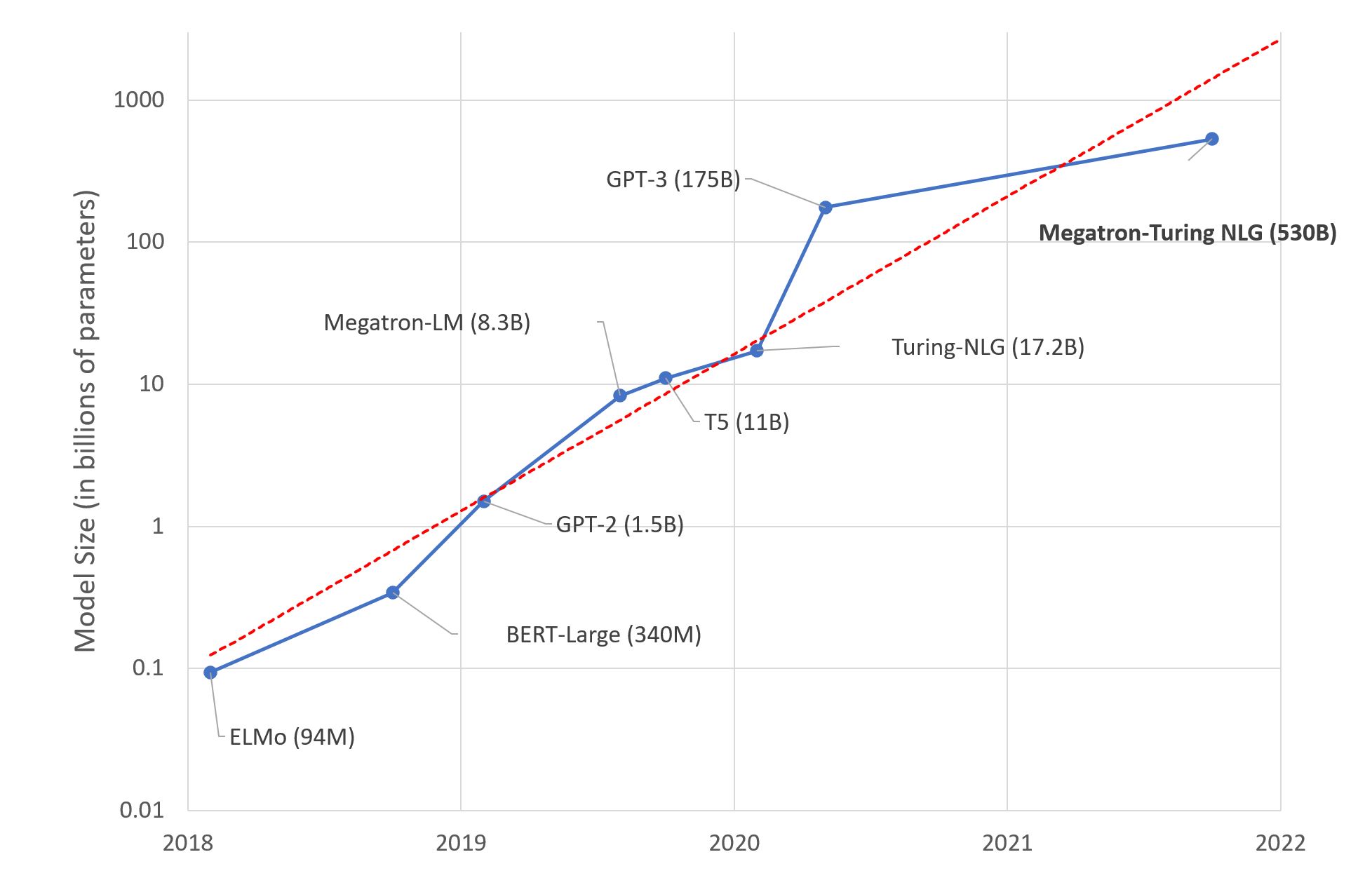
The goal of AutoMM is to help anyone solve machine learning problems via open source foundation models, including these giant models. To finetune these large-scale models, we adopt the recently popularized parameter-efficient finetuning technique. The idea is to either finetune a small subset of the weights in the foundation model (e.g., BitFit), or adding a tiny tunable structure on top of the fixed backbone (e.g., Prompt Tuning, LoRA, Adapter, MAM Adapter, IA^3). These techniques can effectively reduce the peak memory usage and model training time, while maintaining the performance.
In this tutorial, we introduce how to apply parameter-efficient finetuning in MultiModalPredictor.
We first introduce how to adopt the "ia3_bias" algorithm for parameter-efficient finetuning. Afterwards, we show how you can simply combine "ia3_bias"
and gradient checkpointing to finetune the XL-variant of Google’s FLAN-T5 via a single NVIDIA T4 GPU.
Prepare Dataset¶
The Cross-Lingual Amazon Product Review Sentiment dataset contains Amazon product reviews in four languages.
Here, we load the English and German fold of the dataset. In the label column, 0 means negative sentiment and 1 means positive sentiment.
For the purpose of demonstration, we downsampled the training data to 1000 samples. We will train the model on the English dataset and
directly evaluate its performance on the German and Japanese test set.
!wget --quiet https://automl-mm-bench.s3.amazonaws.com/multilingual-datasets/amazon_review_sentiment_cross_lingual.zip -O amazon_review_sentiment_cross_lingual.zip
!unzip -q -o amazon_review_sentiment_cross_lingual.zip -d .
import os
import shutil
os.environ["TRANSFORMERS_CACHE"] = "cache"
def clear_cache():
if os.path.exists("cache"):
shutil.rmtree("cache")
clear_cache()
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
train_en_df = pd.read_csv("amazon_review_sentiment_cross_lingual/en_train.tsv",
sep="\t",
header=None,
names=["label", "text"]) \
.sample(1000, random_state=123).reset_index(drop=True)
test_en_df = pd.read_csv("amazon_review_sentiment_cross_lingual/en_test.tsv",
sep="\t",
header=None,
names=["label", "text"]) \
.sample(200, random_state=123).reset_index(drop=True)
test_de_df = pd.read_csv("amazon_review_sentiment_cross_lingual/de_test.tsv",
sep="\t", header=None, names=["label", "text"]) \
.sample(200, random_state=123).reset_index(drop=True)
test_jp_df = pd.read_csv('amazon_review_sentiment_cross_lingual/jp_test.tsv',
sep='\t', header=None, names=['label', 'text']) \
.sample(200, random_state=123).reset_index(drop=True)
train_en_df.head(5)
| label | text | |
|---|---|---|
| 0 | 0 | This is a film that literally sees little wron... |
| 1 | 0 | This music is pretty intelligent, but not very... |
| 2 | 0 | One of the best pieces of rock ever recorded, ... |
| 3 | 0 | Reading the posted reviews here, is like revis... |
| 4 | 1 | I've just finished page 341, the last page. It... |
test_jp_df.head(5)
| label | text | |
|---|---|---|
| 0 | 1 | 原作はビクトル・ユーゴの長編小説だが、私が子供の頃読んだのは短縮版の「ああ無情」。それでもこ... |
| 1 | 1 | ほかの作品のレビューにみんな書いているのに、何故この作品について書いている人が一人しかいない... |
| 2 | 0 | 一番の問題点は青島が出ていない事でしょう。 TV番組では『芸人が出ていればバラエティだから... |
| 3 | 0 | 昔、 りんたろう監督によるアニメ「カムイの剣」があった。 「カムイの剣」…を観た人なら本作... |
| 4 | 1 | 以前のアルバムを聴いていないのでなんとも言えないが、クラシックなメタルを聞いてきた耳には、と... |
Finetuning Multilingual Model with IA3 + BitFit¶
In AutoMM, to enable efficient finetuning, just specify the optimization.efficient_finetune to be "ia3_bias".
from autogluon.multimodal import MultiModalPredictor
import uuid
model_path = f"./tmp/{uuid.uuid4().hex}-multilingual_ia3"
predictor = MultiModalPredictor(label="label",
path=model_path)
predictor.fit(train_en_df,
presets="multilingual",
hyperparameters={
"optimization.efficient_finetune": "ia3_bias",
"optimization.lr_decay": 0.9,
"optimization.learning_rate": 3e-03,
"optimization.end_lr": 3e-03,
"optimization.max_epochs": 2,
"optimization.warmup_steps": 0,
"env.batch_size": 32,
})
=================== System Info ===================
AutoGluon Version: 1.1.1b20240613
Python Version: 3.10.13
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP Fri May 17 18:07:48 UTC 2024
CPU Count: 8
Pytorch Version: 2.3.1+cu121
CUDA Version: 12.1
Memory Avail: 28.65 GB / 30.95 GB (92.6%)
Disk Space Avail: 189.01 GB / 255.99 GB (73.8%)
===================================================
AutoGluon infers your prediction problem is: 'binary' (because only two unique label-values observed).
2 unique label values: [0, 1]
If 'binary' is not the correct problem_type, please manually specify the problem_type parameter during Predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression', 'quantile'])
AutoMM starts to create your model. ✨✨✨
To track the learning progress, you can open a terminal and launch Tensorboard:
```shell
# Assume you have installed tensorboard
tensorboard --logdir /home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3
```
Seed set to 0
GPU Count: 1
GPU Count to be Used: 1
GPU 0 Name: Tesla T4
GPU 0 Memory: 0.42GB/15.0GB (Used/Total)
Using bfloat16 Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params | Mode
---------------------------------------------------------------------------
0 | model | HFAutoModelForTextPrediction | 278 M | train
1 | validation_metric | BinaryAUROC | 0 | train
2 | loss_func | CrossEntropyLoss | 0 | train
---------------------------------------------------------------------------
122 K Trainable params
278 M Non-trainable params
278 M Total params
1,112.955 Total estimated model params size (MB)
Epoch 0, global step 12: 'val_roc_auc' reached 0.72319 (best 0.72319), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3/epoch=0-step=12.ckpt' as top 1
Epoch 0, global step 25: 'val_roc_auc' reached 0.85344 (best 0.85344), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3/epoch=0-step=25.ckpt' as top 1
Epoch 1, global step 37: 'val_roc_auc' reached 0.88946 (best 0.88946), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3/epoch=1-step=37.ckpt' as top 1
Epoch 1, global step 50: 'val_roc_auc' reached 0.89731 (best 0.89731), saving model to '/home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3/epoch=1-step=50.ckpt' as top 1
`Trainer.fit` stopped: `max_epochs=2` reached.
AutoMM has created your model. 🎉🎉🎉
To load the model, use the code below:
```python
from autogluon.multimodal import MultiModalPredictor
predictor = MultiModalPredictor.load("/home/ci/autogluon/docs/tutorials/multimodal/advanced_topics/tmp/052f655182394add8012763950a90348-multilingual_ia3")
```
If you are not satisfied with the model, try to increase the training time,
adjust the hyperparameters (https://auto.gluon.ai/stable/tutorials/multimodal/advanced_topics/customization.html),
or post issues on GitHub (https://github.com/autogluon/autogluon/issues).
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7fe77f0da8f0>
The fraction of the tunable parameters is around 0.5% of all parameters. Actually, the model trained purely on English data can achieve good performance on the test sets, even on the German / Japanese test set. It obtained comparable results as full-finetuning as in AutoMM for Text - Multilingual Problems.
score_in_en = predictor.evaluate(test_en_df)
score_in_de = predictor.evaluate(test_de_df)
score_in_jp = predictor.evaluate(test_jp_df)
print('Score in the English Testset:', score_in_en)
print('Score in the German Testset:', score_in_de)
print('Score in the Japanese Testset:', score_in_jp)
Score in the English Testset: {'roc_auc': 0.9319163903125314}
Score in the German Testset: {'roc_auc': 0.9234775641025641}
Score in the Japanese Testset: {'roc_auc': 0.8728388746803069}
Training FLAN-T5-XL on Single GPU¶
By combining gradient checkpointing and parameter-efficient finetuning, it is feasible to finetune
google/flan-t5-xl that has close to two billion parameterswith a single T4 GPU available in
AWS G4 instances.
To turn on gradient checkpointing, you just need to set "model.hf_text.gradient_checkpointing" to True.
To accelerate the training, we downsample the number of training samples to be 200.
# Just for clean the space
clear_cache()
shutil.rmtree(model_path)
from autogluon.multimodal import MultiModalPredictor
train_en_df_downsample = train_en_df.sample(200, random_state=123)
new_model_path = f"./tmp/{uuid.uuid4().hex}-multilingual_ia3_gradient_checkpoint"
predictor = MultiModalPredictor(label="label",
path=new_model_path)
predictor.fit(train_en_df_downsample,
presets="multilingual",
hyperparameters={
"model.hf_text.checkpoint_name": "google/flan-t5-xl",
"model.hf_text.gradient_checkpointing": True,
"model.hf_text.low_cpu_mem_usage": True,
"optimization.efficient_finetune": "ia3_bias",
"optimization.lr_decay": 0.9,
"optimization.learning_rate": 3e-03,
"optimization.end_lr": 3e-03,
"optimization.max_epochs": 1,
"optimization.warmup_steps": 0,
"env.batch_size": 1,
"env.eval_batch_size_ratio": 1
})
Global seed set to 123
Auto select gpus: [0]
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
-------------------------------------------------------------------
0 | model | HFAutoModelForTextPrediction | 1.2 B
1 | validation_metric | AUROC | 0
2 | loss_func | CrossEntropyLoss | 0
-------------------------------------------------------------------
203 K Trainable params
1.2 B Non-trainable params
1.2 B Total params
4,894.913 Total estimated model params size (MB)
Epoch 0, global step 20: 'val_roc_auc' reached 0.88802 (best 0.88802), saving model to '/home/ubuntu/autogluon/docs/tutorials/multimodal/advanced_topics/multilingual_ia3_gradient_checkpoint/epoch=0-step=20.ckpt' as top 1
Epoch 0, global step 40: 'val_roc_auc' reached 0.94531 (best 0.94531), saving model to '/home/ubuntu/autogluon/docs/tutorials/multimodal/advanced_topics/multilingual_ia3_gradient_checkpoint/epoch=0-step=40.ckpt' as top 1
`Trainer.fit` stopped: `max_epochs=1` reached.
<autogluon.multimodal.predictor.MultiModalPredictor at 0x7fd58c4dbca0>
score_in_en = predictor.evaluate(test_en_df)
print('Score in the English Testset:', score_in_en)
Score in the English Testset: {'roc_auc': 0.931263189629183}
# Just for clean the space
clear_cache()
shutil.rmtree(new_model_path)
Other Examples¶
You may go to AutoMM Examples to explore other examples about AutoMM.
Customization¶
To learn how to customize AutoMM, please refer to Customize AutoMM.