
The Series C funding, which brings its total raise to around $95 million, will go toward mass production of the startup’s inaugural products
treasuredataに関するa2ikmのブックマーク (29)
-
 a2ikm 2020/07/08
a2ikm 2020/07/08
-
すべてのエンジニアがコミットする、トレジャーデータの採用手法「エンジニア採用は誰のシゴト?#2」 - LAPRAS HR TECH LAB
ホーム » LAPRAS SCOUT導入事例 » インタビュー » すべてのエンジニアがコミットする、トレジャーデータの採用手法「エンジニア採用は誰のシゴト?#2」 本記事では、前回の記事に引き続き「エンジニア採用は誰のシゴト?」というテーマでエンジニア採用に関わる方にお話を訊いていきます。 今回お話を伺ったのはトレジャーデータ株式会社のエンジニアリングディレクターである伊澤さん。エンジニアチームが主導となって採用要件の策定から採用活動を行う体制についてお話いただきました。 《プロフィール》 伊澤 良樹さん: 米国留学後、リクルート米国法人子会社にてWebエンジニアとしてキャリアをスタート。帰国後、Yahoo! JAPANにてサービス開発、プラットフォーム開発・運用担当し、開発部長としてデータソリューション開発組織を管理運営してきた。その後、DeNAにて分析基盤の開発およびチームリードを経

-
Planet-scale Data Ingestion Pipeline: Bigdam
Bigdam is a planet-scale data ingestion pipeline designed for large-scale data ingestion. It addresses issues with the traditional pipeline such as imperfectqueue throughput limitations, latency in queries from event collectors, difficulty maintaining event collector code, many small temporary and imported files. The redesigned pipeline includes Bigdam-Gateway for HTTP endpoints, Bigdam-Pool for d

-
広告/マーケティング/CRMの領域を含む様々な顧客データを統合するカスタマー・データ・プラットフォーム(CDP)の提供を開始 - Treasure Data
広告/マーケティング/CRMの領域を含む様々な顧客データを統合するカスタマー・データ・プラットフォーム(CDP)の提供を開始 トレジャーデータ株式会社(本社:東京都千代田区、代表取締役社長:三橋 秀行、以下:トレジャーデータ)は、7月11日より、オンライン広告、マーケティングやCRM(Customer Relationship Management)領域のデータはもちろんのこと、顧客一人ひとりの行動データや属性データなどのデータを統合することで、パーソナライズを軸としたデジタルトランスフォーメーション(*1)を可能とするカスタマー・データ・プラットフォーム(CDP: Customer Data Platform)を提供します。 これまで、トレジャーデータは企業が独自に保有する様々なチャネルから生成される顧客の行動データなどとサードパーティデータを統合させることで、顧客データをセグメント化し

-
Plazma - Treasure Data’s distributed analytical database -
This document summarizes Plazma, Treasure Data's distributed analytical database that can import 40 billion records per day. It discusses how Plazma reliably imports and processes large volumes of data through its scalable architecture with real-time and archive storage. Data is imported using Fluentd and processed using its column-oriented, schema-on-read design to enable fast queries. The docume

-
ドリコムを支えるデータ分析基盤がTD+AWSに移行した話 - かにぱんのなく頃に
はじめに これは ドリコムAdventCalendar の7日目です 6日目は、keiichironaganoさんによる iTunes 使用許諾更新のとき一旦キャンセルしてほしい話 です 【その2】ドリコム Advent Calendar 2015 もあります 自己紹介 @ka_nipan 去年の ドリコムを支えるデータ分析基盤 に引き続き、今年もドリコムのデータ分析基盤を担当しています。 分析基盤をTreasure Dataに移行 オンプレ環境の Hadoop からTreasure Data に移行しました。 また、ジョブ管理ツールやBIツールといったサーバーもAmazon EC2 に移行しており、 徐々にオンプレ環境を離れつつあります。 背景 オンプレ環境で Hadoop を運用して3年も経つと考えなければならないのが HW の寿命です。 さてどうしようかとなった時に、ほぼ迷いなく外部

-
Treasure Data Update 2015 | Post Moratorium
Treasure Data Update 2015 皆様こんにちは。トレジャーデータでCTOをしてます太田です。Treasure Data Advent Calendar 1日目では、2015年の振り返りをして見たいと思います。 会社今年は個人的にはとにかく採用に時間を費やした年でした。2014年の12月にSeries Bの増資をした後、約40名から約100名まで採用を行いました。 エンジニアはもちろん、セールス・マーケ・プロダクト・BDなど会社として必要なあらゆるポジションが拡充されました。特にCFOが加入した事で、会社基盤が完全に次のレベルに入った実感が有ります。 地域で見るとUSが約55名、日本が約40名、韓国 (今年の1月にお店開き) が3名といったような内訳になっています。エンジニアが約30%・セールス & ・マーケティングが約60%という事で、4年目のB2B SaaSスタートア
-
トレジャーデータ 導入体験記 リブセンス編
第1回 トレジャーデータ ユーザ会で発表した、 Livesense Inc. での導入事例紹介です。Read less

-
Treasure DataのPlazmaDBを理解する - Qiita
こんにちは。Treasure Dataの斉藤です。出張中に時間ができたのでシアトル空港でこの記事を書いています。日本語でブログを書くのはものすごく久しぶりなのですが、Treasure Dataの列志向(columnar)圧縮ストレージであるPlazmaDBについて紹介していきたいと思います。 Treasure Dataでは2014年現在まで5兆(trillion)件を超えるレコードが取り込まれており、一秒あたりでは40万以上(!)のレコードを処理しています。 2013年のTwitterでは1秒あたり5,700 tweets処理していたとのことなので、その処理量の大きさが実感できるのではないでしょうか。この量のレコードをそのまま蓄積するのではストレージ量が膨大になってしまいますので、Treasure Dataではレコードを列分解し、MessagePack形式に変換+圧縮処理を施すことでデータ

-
-
【前編】トレジャーデータCTOと紐解く。日米で異なるCTOの役割とは?
Twitterでハッシュタグ「#naoya_sushi」が生まれてしまうほど、無類の寿司好きとして知られる伊藤直也氏(@naoya_ito)。そんな伊藤氏をホスト役とし、トップエンジニアをゲストに招いて、寿司をつまみつつホンネで語ってもらおうという、この企画。 第六回のゲストは、弱冠20歳にしてCTOとしてのキャリアをスタートさせ、現在はシリコンバレー発のベンチャー企業『トレジャーデータ株式会社』のCTOとして活躍中の太田一樹氏(@kzk_mover)が登場!日米両方でCTOを務めた経験から、そのギャップや空気感、そしてシリコンバレーから世界を相手に勝負するため起業した真意などをお聞かせいただきました。日米を股にかけるkzk氏だからこその視点で、議論していただきます。お楽しみに! — 伊藤直也(以下「naoya」):久しぶりですね。日本に戻ってくるタイミングだとやっぱり飲み会続きですか?

-
Treasure Data に入社しました - 2015-05-18 - はてなるせだいあり
今日から Treasure Data で働くことになりました。 前職が一段落して(退職エントリ)転職を考えた時に、ちょうどtagomorisさんが何社も回った末にTreasure Dataに決めていたので、TDにしました。 … もちろん物事を決めるときに理由はいくつもあるわけでして、 OSS開発者として暮らしやすそう Twitterを勤務時間中にできるとかそのほかもろもろ 知り合いの有無 何を目指しているかわかりやすい 目指しているところが不明瞭だと迷走しやすい気がする これからの成長の余地が大きそう Ruby開発に際してビッグユーザーであるTreasure Dataのユースケースを得たかった あと、AmazonやGoogle、Microsoftと戦って、その戦う武器がOSSってのがよいですね。OSS派の旗を降ろせる条件がめちゃくちゃ厳しいのがよいです。 ちなみに今心配なことは、みんなも気
-
トレジャーデータでの Sales Engineering としてのやりがい,そして今後見据えるものについて - トレジャーデータ(Treasure Data)ブログ
始めに トレジャーデータは事業の急拡大を受けて、セールス、エンジニアなどの各方面で一緒に働ける人材を募集中しています。特に Sales Enginnering(SE)を私たちは必要としています。募集要項につきましては、以下のリンクをご参照下さい。 もし私を知っている方はTwitterおよびFacebookなどに気軽にお声かけ下さい。 さて今回は、私も所属するこのSEについて以下の3点をご紹介したいと思っています。 「トレジャーデータにおけるSEの役割」 「トレジャーデータにおけるSEとしてのやりがい」 「トレジャーデータではこんな方を募集しています」 トレジャーデータにおけるSEの役割 トレジャーデータは米シリコンバレーを本社に、そして日本にも支社を持つ、主にクラウド上でデータマネジメントサービスを提供する企業です。 ポイント1:ソフトウェアやハードウェアではなく、「サービス」を提供する
-
マウンテンビューの片隅で意識低く短期間滞在を生き抜くためのノウハウ - たごもりすメモ
自分もシリコンバレーはマウンテンビューに本社があるベンチャーに就職して仕事でカリフォルニアの青空すばらしい! とか言っているからにはこの地域でいかに生き抜くべきかみたいな意識の高いことを書こうかと思ったが、青空を見ながらも既にビールが入っていて到底無理そうだった*1。 なので、シリコンバレーとかベイエリアなんて風呂敷を広げず、マウンテンビュー、しかもダウンタウン近くではなくSan Antonioという微妙に離れた田舎でクルマ無しにショートステイを無事生きるにはどうすればよいかについて書き残そうと思う。 そんなニッチな文書書いてどうするんだという話はありそうだが、少なくともこれから東京で入社してくる同僚のためには役に立つ……はずだ。 前提 San Antonio Mountain Viewというところにオフィスがあって、そこに徒歩で通えるあたりのホテルもしくはAirbnbに宿泊すると思いねえ
-
Treasure Dataに入社しました - かみぽわーる
近況などをブログに書いたことはなかったんですが、4月からTreasure Dataで働くことになりました。 3月に新しい仕事を探してたタイミングでちょうど声をかけてもらって、他に誘ってくれてるところもあっていろいろ考えたんですけど、今まで自分がやってたWeb屋さんとは結構ちがう専門的なプロダクトが面白そうだったこと、話してみてエンジニアリング上の解決したい課題についてすごく具体的にいろいろ話してくれたので、畑違いな気もするけどやれることは結構ありそうだなとイメージできたので入社することにしました。 あとは声をかけてくれるのが2週間遅かったら他のところに決めちゃってたので、お互いのタイミングが合ってたことで自分が想像していなかった選択肢が生まれたことにも面白さを感じて、まあこれも自分の中のひとつのチャレンジだと思って返事をしたという感じです。 HadoopもFluentdもよく分からんしSl
-
Treasure Dataに入社しました - myui's memo
3/31付けで4月から国立研究開発法人になった産業技術総合研究所を退職致しまして、4/1からTreasure Dataに入社しました。第一号のResearch Engineerとして東京オフィスで働きます。 CTOの太田さんから2013年頃に一度お誘いを受けておりましたが、2014年になってまた声を掛けて頂き、2年越しでの入社となりました。 なんでTreasure Data? 現在のTreasure Dataでは、毎秒45万レコード、4,000億レコード/日ものデータが投入されていて、Hiveで処理されるデータ量も3+ペタバイト/日と急速な発展をとげております。研究でもこの規模のデータ量を扱うことはGoogleやFacebook等の一部の研究者を除いてはありませんから、非常に挑戦的な課題に取り組める環境であることにDB研究者として第一に魅力を感じました。優秀なエンジニアが集まっていて刺激的
-
-
データ分析で大切な4つのこと:1. 「当たり前の結果」をたくさん出す事の大切さ - トレジャーデータ(Treasure Data)ブログ
データ分析で大切な4つのこと トレジャーデータはクラウドでデータマネージメントサービスを提供しています。 ここ数年,データの大量な蓄積とそれに対する分散並列処理が可能な環境が成熟してきました。元々はデータの蓄積やバッチの効率化といった分析バックエンド(プラットフォーム)の方にフォーカスがあてられてきましたが,やっとその先のデータ」「分析」というところ,そしてその役割を果たすデータ分析者の重要性が理解されるようになってきているように感じています。 このブームは分析者にとって非常に喜ばしいことでもあると同時に,大きなプレッシャーにもなっているような気がします。 そのプレッシャーの1つに,企画者や経営者・あるいは顧客といった結果を活用する人々(=意志決定者)の,「これだけ材料(データ)が揃っているのだから多くの課題が解決できるはずだ」という期待に応えないといけないというプレッシャーがあると思いま
-
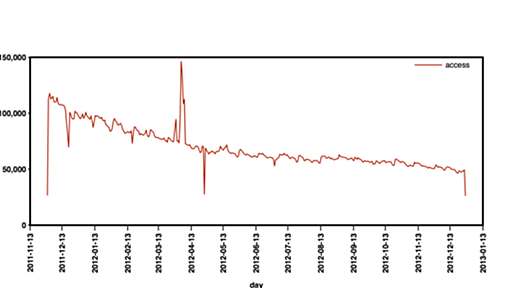
Login(アクセス)ログからわかる12の指標 その1 - トレジャーデータ(Treasure Data)ブログ
*トレジャーデータはデータ収集、保存、分析のためのエンドツーエンドでサポートされたクラウドサービスです。 「Login(アクセス)ログからわかる12の指標 シリーズ」 その1,その2,その3,その4 クエリ内のTreasure UDFのリファレンスはこちら。 本シリーズの主張は,例え単純な ”ログイン”(アクセス)の記録のみを取るだけでも,それにユーザーIDが付くことでトレジャーデータ上で遙かにリッチな示唆を得ることができる,ということです。 もしユーザーを識別できるサービスをお持ちでこれから分析を始めたい企業様は,きちんとそれをloginログを残すことから始めましょう。本記事では「login(アクセス)ログ」というたった1種類のデータから得られる12の指標を紹介したいと思います。 定義 以下の項目で定義されるログを「loginログ」と定義し,かつ各ユーザーの登録時からこのログデータが取得
-
Treasure Dataが新サービス発表。バッチ型クエリと比較して10倍から50倍高速な「Treasure Query Accelerator」とデータ可視化ツール「Treasure Viewer」
クラウド上で大規模データの保存し、分析、レポーティングのサービスを提供しているTreasure Dataは9日、大規模データに対してアドホッククエリを発行する機能と、同社として初めてとなるデータ可視化ツールなどの新サービスを発表しました。 Treasure DataのCTO 太田一樹氏は、同社が100社以上の顧客から預かっているデータが2兆5000億件に達していることを明らかにしたうえで、顧客のデータ活用が定型レポートから始まり、徐々にアドホッククエリなどによってデータをドリルダウンし、いま何が起きているのか分析を行う方向へと進化していくと指摘。「お客様の進化に合わせて新サービスを投入する」と発言。 Treasure Query AcceleratorとTreasure Viewer発表 1つ目の新サービスは、アドホックなデータ解析向けのクエリエンジン「Treasure Query Acc







公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


Copyright © 2005-2024 Hatena. All Rights Reserved.
設定を変更しました