
機械学習に関するikajigokuのブックマーク (135)
-
 ikajigoku 2024/11/21
ikajigoku 2024/11/21
-
物理学者の逆襲!?Entropixはわずか3億6000万パラメータで1000億パラメータ級の回答を引き出す!Claude-3でも間違う問題を360Mが正しく解く|shi3z
物理学者の逆襲!?Entropixはわずか3億6000万パラメータで1000億パラメータ級の回答を引き出す!Claude-3でも間違う問題を360Mが正しく解く 物理学者たちがノーベル物理学賞をホップフィールドとヒントンが受賞すると知った時、まあまあ微妙な気持ちになったことは想像に難くない。 我々コンピュータ科学者にとっては、ノーベル賞は全く無縁なものだった。むしろ「ノーベル賞をコンピュータ科学者が取ることは永久にない」と言い訳することさえできた。コンピュータ科学の世界にはチューリング賞という立派な賞があるし、ノーベル賞よりも賞金が高かった京都賞は、アラン・ケイやアイヴァン・サザーランド、ドナルド・クヌースなど、コンピュータ科学者たちが堂々と受賞している。その割には本来マイクロチップの最初の設計者である嶋正利などが京都賞にノミネートされていなかったり、サザーランドの弟子であるアラン・ケイの

-
2024年ノーベル物理学賞:物理学からAIの基礎を築いた2氏に|日経サイエンス
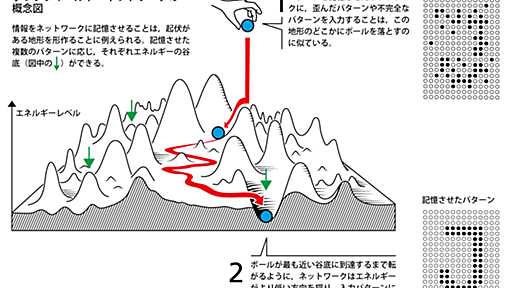
2024年のノーベル物理学賞は,「人工ニューラルネットワークによる機械学習を可能にする基礎的発見と発明」の功績で,米プリンストン大学のホップフィールド(John Hopfield)名誉教授とカナダのトロント大学のヒントン(Geoffrey Hinton)名誉教授に授与される。 ある技術が社会で広く使われ生活や産業を大きく変えたとき,その原点に立ち戻り,最初の一歩となった成果にノーベル賞が授与されることはしばしばある。今回の授賞がまさにその例だ。物理学賞を受賞した2人は1980年代に,今,最も注目が集まっている人工知能(AI)の根幹である人工ニューラルネットワークの基礎を築いた。 ヒントになったのは,磁性の振る舞いを語るのに使われている物理学のモデルだ。磁性体はしばしば,互いに影響を及ぼし合う電子のスピン(自転の向きに相当する)が縦横に並んだモデルで記述される。各スピンはお互いの距離と相互作
-
-
BitNetから始める量子化入門
はじめに BitNet、最近話題になっていますね。 そもそも量子化って何?という方もいると思うので、この記事は DeepLearning の量子化から入り、その上で BitNet の触りについて見ていこうと思います。色々とわかってないことがあり、誤読してそうなところはそう書いてるのでご了承ください。 図を作るのは面倒だったので、様々な偉大な先人様方の図やスライドを引用させていただきます。 量子化 DeepLearning における量子化 DeepLearning の学習・推論は基本 float32 で行います。これを int8 や Nbit に離散化することを量子化といいます。 計算に使う値は、モデルの重み、アクティベーション(ReLUとか通した後)、重みの勾配等があります。 学習時については一旦置いておいて、この記事では推論における量子化について焦点をあてます。推論時に量子化の対象となる

-
DeepMind、AIで人間考案のものより優秀なソートアルゴリズムを発見 最大70%高速化
米Google傘下のAI企業Google DeepMindは6月7日(現地時間)、アルゴリズムを開発するAI「AlphaDev」が、人間が考えたものより高速なソートアルゴリズムを発見したと発表した。 ソートアルゴリズムは、入力されたデータを一定のルールに基づいて並べ替えるもの。ネット検索結果の並べ替えやランキング制作などIT技術の根幹を担う技術の一つ。今回AlphaDevが考案したアルゴリズムは既存のものに比べて、少量のデータなら最大70%、数十万規模の大量のデータなら約1.7%速く処理できた。 DeepMindはAlphaDevに新しいアルゴリズムを発見させるため、ソートの作業を「組み立てゲーム」としてプレイさせた。「正確にソートできる」「既存のアルゴリズムより高速である」という2点を満たせばクリアとした。 関連記事 OpenAIやDeepMindのCEOやトップ研究者ら、「AIによる人

-
-
結城浩とChatGPTの対話
ChatWithChatGPT.md 結城浩とChatGPTの対話 2022年12月2日 「質問」は結城浩の文章です。 「回答」はChatGPTの文章です。 質問 ChatGPTという対話するAIツールがあります。人間が質問を投げかけるとそれらしく対話して回答してくれるツールです。こういうツールに対してどんな質問を投げかけたらおもしろい対話になるでしょうかね。何かアイディアがあったら聞かせてください。具体的な質問を知りたいなあ。 回答 ChatGPTは自然言語処理能力が高いため、人間が自然に投げかける質問をそれらしく受け答えることができます。例えば、ニュースやスポーツに関する話題、人間の心理や行動、哲学的な問題、文化や歴史に関する話題など、様々なテーマについて対話することができます。また、ChatGPTを用いた対話は、人間のようなスムーズな会話のように進むことができますので、おもしろい対話

-
ChatGPT使い方総まとめ - Qiita
こんにちは!sakasegawaです! ( https://twitter.com/gyakuse ) 今日は今流行のChatGPTについて紹介します! ChatGPTとは OpenAIが開発するGPT-3(※)というめちゃくちゃすごい言語モデルをベースとしたチャットアプリです。 色んな質問にすぐ答えてくれます。 この記事ではさまざまな使い方を紹介します。 https://chat.openai.com/ ちなみにGPT-3関連では、noteの以下記事も便利なのでぜひ読んでみてください AIがコミットメッセージ自動生成!神ツール『auto-commit』『commit-autosuggestions』の紹介 ※正確にはGPT-3.5シリーズと呼ばれています ChatGPTの仕組みを考えながらプロンプトを作る手法はこちらに別途まとめています 文章 質問-応答 〜について教えて Wikiped

-
HなStable Diffusion
前提として、Stable Diffusionでエロ画像を出そうとしてもsafety checkerという機能が入っており、センシティブな画像を出そうとすると黒塗りになる。 (Stable DiffusionのSaaSであるDream Studioはぼかしだが、多分別の技術) https://github.com/huggingface/diffusers/releases/tag/v0.2.3 そこでGoogle Colabでちゃちゃっと環境を作り、なおかつNSFWを回避する。 1. 下記のリンクでノートを開く https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb 2. 下記の箇所を書き換える vvvvvvvvvvvvvvvvvv f

-
-
Increasing number of attempts ver. 2021
試行回数の増やし方 2021年度版です

-
真面目なプログラマのためのディープラーニング入門
はじめに: 本講座は「機械学習ってなんか面倒くさそう」と感じている プログラマのためのものである。本講座では 「そもそも機械が『学習する』とはどういうことか?」 「なぜニューラルネットワークで学習できるのか?」といった 根本的な疑問に答えることから始める。 そのうえで「ニューラルネットワークでどのようなことが学習できるのか?」 という疑問に対する具体例として、物体認識や奥行き認識などの問題を扱う。 最終的には、機械学習のブラックボックス性を解消し、所詮は ニューラルネットワークもただのソフトウェアであり、 固有の長所と短所をもっていることを学ぶことが目的である。 なお、この講座では機械学習のソフトウェア的な原理を中心に説明しており、 理論的・数学的な基礎はそれほど厳密には説明しない。 使用環境は Python + PyTorch を使っているが、一度原理を理解してしまえば 環境や使用言語が

-
東京工業大学、機械学習の講義ノートが無料公開 Pythonの実装も学べる | Ledge.ai
サインインした状態で「いいね」を押すと、マイページの 「いいね履歴」に一覧として保存されていくので、 再度読みたくなった時や、あとでじっくり読みたいときに便利です。

-
「どんな文章も3行に要約するAI」デモサイト、東大松尾研発ベンチャーが公開 「正確性は人間に匹敵」
東京大学・松尾豊研究室発のAIベンチャーELYZA(イライザ/東京都文京区)は8月26日、文章の要約文を生成するAI「ELYZA DIGEST」を試せるデモサイトを公開した。人間より短時間で要約でき、要約の正確性は「人間に匹敵する」という。今後も精度を高め、議事録作りやコールセンターでの対話メモ作成などでの活用を目指す。 同社は自然言語処理技術(NLP)の研究を進めており、日本語テキストデータの学習量・モデルの大きさともに日本最大級というAIエンジン「ELYZA Brain」を開発している。 ELYZA DIGESTは、大規模言語モデルを基に、要約というタスクに特化したAIとして開発。読み込んだテキストを基に、AIが一から要約文を生成する「生成型」モデルで、文の一部を抜き出す「抽出型」モデルなどと異なり、文の構造が崩れていたり、話者が多数いる会話文だったりしても、精度の高い要約文を生成でき

-
機械学習のパラメータチューニングを「これでもか!」というくらい丁寧に解説 - Qiita
はじめに 私はこれまで機械学習のパラメータチューニングに関し、様々な書籍やサイトで学習を進めてきました。 しかしどれもテクニックの解説が主体のものが多く、 「なぜチューニングが必要なのか?」 という目的に関する記載が非常に少なかったため、体系的な理解に苦労しました。 この経験を後世に役立てられるよう、「初心者でも体系的に理解できる丁寧さ!」をモットーに記事にまとめたいと思います。 具体的には、 1. パラメータチューニングの目的 2. チューニングの手順とアルゴリズム一覧 3. Pythonでの実装手順 (SVMでの分類を例に) の手順で解説を進めます。 独自解釈も含まれるため、間違っている点等ございましたら指摘頂けると有難いです。 なお、文中のコードはこちらのGitHubにもアップロードしております。 2021/9/6追記:LightGBMのチューニング実行例追加 以下の記事に、Ligh

-
Hiroshi Takahashi
Skip to the content. 機械学習の研究者を目指す人へ 機械学習の研究を行うためには、プログラミングや数学などの前提知識から、サーベイの方法や資料・論文の作成方法まで、幅広い知識が必要になります。本レポジトリは、学生や新社会人を対象に、機械学習の研究を行うにあたって必要になる知識や、それらを学ぶための書籍やWebサイトをまとめたものです。 目次 プログラミングの準備 Pythonを勉強しよう 分かりやすいコードを書けるようになろう 数学の準備 最適化数学を学ぼう 基本的なアルゴリズムとその実践 機械学習の全体像を学ぼう 基本的なアルゴリズムを学ぼう 深層学習の基礎を学ぼう scikit-learnやPyTorchのチュートリアルをやってみよう サーベイの方法 国際会議論文を読もう Google Scholarを活用しよう arXivをチェックしよう スライドの作り方 論文の
-
OptunaとKubeflow Pipelinesを用いた並列ハイパーパラメータチューニング | MoT Lab (GO Inc. Engineering Blog)
はじめに こんにちは。AI技術開発部 MLエンジニアリング第1グループの築山です。 以前、社内でOptunaとKubeflow Pipelines(以下KFP)を用いて並列ハイパーパラメータチューニングを行い、とあるプロダクト(後述する『お客様探索ナビ』の経路推薦システム)のパラメータに適用する機会がありました。 その際は社内向け勉強会のためにスライドをまとめ、以下のツイートとともにSlideShareで公開しており、多少の反響もいただいていました。 https://twitter.com/2kyym/status/1256147262738018304?s=20 そのスライドがOptunaの開発者の方の目に留まり、「テックブログを書いて欲しい」と打診をいただき、今回執筆している次第です。 公開済みスライドと被る部分もありますが、基本的には 今回のユースケースOptunaとKFPの紹介・チ

-
Optunaでハイパパラメータチューニング - け日記
今回はハイパパラメータチューニングを自動化するOptunaを触りながら紹介していきます。 Optuna BayesianOptimizationのかゆいところ Optunaを用いた実装 1変数関数の最適化 分散最適化 scikit-learnの最適化 まとめ Optuna 勾配ブースティング木やニューラルネットワークなどのハイパパラメータチューニングは職人芸みたいなところがあって、一発で最適に近い値をマークするなどほぼ不可能です。かと言って、グリッドサーチなどで探索しようにもパラメータ数が多いと計算時間が膨大になります。 こうした実質ブラックボックスのパラメータチューニングを、ベイズ最適化で行ってくれるPythonライブラリが Optuna です。 preferred.jp これら↓の記事が大変参考になります。 tech.preferred.jp PyData.Tokyo Meetup #

-
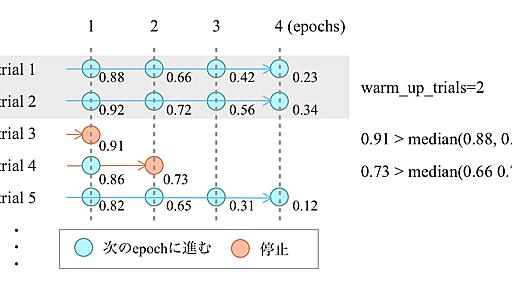
ハイパーパラメーター最適化フレームワークOptunaの実装解説 | | AI tech studio
AI Lab AutoMLチームの芝田です (GitHub: @c-bata)。 ハイパーパラメーター最適化は、機械学習モデルがその性能を発揮するために重要なプロセスの1つです。Pythonのハイパーパラメーター最適化ライブラリとして有名な Optuna [1] は、様々な最適化アルゴリズムに対応しつつも、使いやすく設計的にも優れたソフトウェアです。本記事ではOptunaの内部実装についてソフトウェア的な側面を中心に解説します。 Optunaの内部実装を理解するためには、主要コンポーネントの役割と全体の動作の流れを押さえる必要があります。しかしOptunaの開発は活発で、コード量も多くなり、全体の流れをコードから読み取ることは難しくなってきました。そこで今回Minitunaという小さなプログラムを用意しました。Minitunaには全部で3つのversionがあり、それぞれ100行、200行



公式Twitter
- @HatenaBookmark
リリース、障害情報などのサービスのお知らせ
- @hatebu
最新の人気エントリーの配信
キーボードショートカット一覧
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く

