
After the fall of the Berlin Wall, East Germans had to get used to a new way of consuming, working, and living.

After the fall of the Berlin Wall, East Germans had to get used to a new way of consuming, working, and living.

Войдите, чтобы подписываться на каналы, комментировать видео и оставлять реакции Вход и регистрацияВсе категории

有時候你在網路上看到某部影片,如果想收藏起來,預計在沒網路的時候也可以觀看,或是對你而言重要需要留存備份的影片,CatchV 是一個用來下載線上網路影片的工具,可以用來下載 YouTube 影片 (1080p, 1440p, 2160p MP4 / WebM)、下載 Facebook 影片、下載 Instagram 影片、等等 CatchV 目前已經支援的六千多家影片網站,你不需要額外安裝任何外掛,使用方法非常簡單! CatchV 是怎麼運作的? CatchV 的網頁爬蟲程式會根據你提供的網址,到那個網頁上搜尋有沒任何的影片連結,如果有找到的話,就將找到的影片連結直接返回給你。換句話說,CatchV 站上不會儲存任何原始影片檔案,所有影片都是在第三方伺服器上,所以 CatchV 不保證找到的影片內容會是什麼,也不對該內容負責任,所有的影片連結都來自你提供的網頁中。此外,如果來源網頁是私密不

Cisco Enterprise Networking オンラインセミナー 開催済みセミナーをオンデマンドで視聴いただけます。

どうもこんにちは、あんどう(@t_andou)です。 前回宣言した通りに誰でも簡単にYoutubeの字幕ファイルを作る方法を書きます。 「Youtubeの」と書いていますが、実際はどの動画でも対応してます。 前回の記事 blog.takuya-andou.com まずはGoogleColabの共有 colab.research.google.com 使い方 GoogleColabに記載していますが 1.GPUを使用するように切り替え 上の「ランタイム」→「ランタイムのタイプを変更」からからGPUを選択 2.右上の接続 下のセルを実行すると自動的に接続されるので省略可能です 3.動画をアップロード ここにドラッグ&ドロップでアップできます 大容量のデータの場合、GoogleDriveと連携した方が効率的です 4.入出力のパスの変更 ファイル名に合わせて変更してください 5.全セルを実行 あと

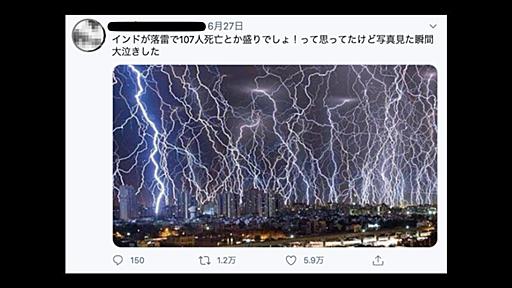
インパクトのある写真を反射的にシェアしてしまったり、「マスメディアに流れない事実」を見つけてリツイートしたり。そうやってあなたが拡散した情報は、世界中で何度も繰り返し現れるデマやフェイク情報かもしれない。 実例と、そういった情報に騙されないための具体的な方法を紹介する。 何度も拡散する「インドの雷神」画像2020年6月25日、インドで落雷によって107人が死亡したというニュースが流れた。その際に、ある匿名アカウントがツイートした画像が、冒頭に掲げたものだ。 信じがたい量の雷が降り注ぐ画像は1.2万回以上リツイートされ、「これが本当の『万雷』か」「逃げ場なし」などの反応を生んだ。 結論から言うと、この画像は2つの意味で現実のものではない。 一つは、雷が落ちている写真を何枚も合成して作った写真だということ。もう一つは、2017年4月に撮影されたものであるということ。 つまり、2020年6月25
Windows10だけですぐに簡単にデスクトップの録画ができます。ほんと以前とは変わりましたね。本記事では、デスクトップの動きや音声を録画して保存し動画にする方法を解説します。ご自身にあった方法で試されてみてください。 PCのデスクトップを動画にする デスクトップの操作やゲーム画面をそのまま動画にしたいときってありますよね。 ゲーム実況はもちろんのこと、何かを解説する動画ですとか、クラウドソーシングでPC作業の仕方を動画で示して指示を出すなど、あらゆる場面でデスクトップ録画は便利ですよね。 かつては高額なキャプチャボードや限られたソフトでしかできなかったのですが、技術進歩もあって実はとても簡単にできるようになりました。 それでは早速、最新のデスクトップ録画の方法をご紹介します。 デスクトップの録画方法 Windows10ゲームモードで録画 こちらがWindows10のデスクトップ録画の動画

どもです、水野です。(5000文字超えてます。。) 自分で記事を書く ↓ ある程度収益がでてくる ↓ その次の一手と言ったら? 多くの方が外注さんに仕事を依頼してサイトを拡大していこう!という流れだと思います。1サイトで売上がでてくると次々と良いアイデアがでてきますもんね。今回は記事の外注化の話をしていきます。 ※外注さん=プロor素人の方に仕事を依頼することを指します。 外注化したいけど外注さんはどこにいるの? 一昔前までは@SOHOというところに多くの外注さんが集まっていました。 今もいるとは思いますが、現在はクラウドワークス・ランサーズの認知度が高まり、フリーランスの記事ライターさんの多くはクラウド系に移行していっています。 個人的には昔のような@SOHO上の簡易メールでやりとりをし、その後は双方でやりとりをする方がクラウド系よりも長続きする場合が多かったのでよかったなぁと。 ただ、

Travel and explore the world of cinema. Largest collection of video quotes from movies on the web.
なんかいい映画ないかなぁと思うことは誰にだってありますよね。ちょっと時間ができた時なんかに、映画でも見てみようかと。でもこれはそんなに簡単なことではありません。 世の中にある映画なんて多すぎて一体いくつあるのか分からないくらいですし、一回選んだらだいたい2時間は取られるわけです。おもしろくない映画に2時間奪われるリスク、そして最高の映画を見ずに人生を終えてしまうリスク。こんなハイリスクを背負って僕たちは映画と向き合っていかなければいけません。 恐ろしい。 こんな恐ろしいことがありますか。 でも安心してください。機械学習がそれを解決してくれます。今回の記事では、機械学習を使って、自分自身に映画をおすすめするモデルを作ってみました。 何は無くともまずはデータが必要です。今回はみんなのレビューサイトさんからデータを拝借しています。 みんなのレビューサイトでは、レビュアーが自身のプロフィールを登録

本編をご覧のみなさんこんにちは。本編をご覧になっていないみなさんもこんにちは。 こちらの記事ではスクレイピング編をお送り致します。 言語は慣れたPythonを選択しています。 映画レビューサイトは、利用規約やデータ表示の構造から、みんなのシネマレビューさんにお世話になることにしました。ありがとうございます。情報量も多くて素晴らしいサイトですね。 では、早速やっていきましょう。まずは必要なライブラリをインポートしておきます。どれも一般的なものですね。 #必要なライブラリをインポート from bs4 import BeautifulSoup import requests import pandas as pd from pandas import Series, DataFrame import time みんなのシネマレビューさんでは、映画情報(制作年、監督、キャストなど)、レビュアーリ

はじめに 本記事では、Python, BeautifulSoup4, requestsをつかってFilmarksから特定の映画のレビューをすべて取得する方法について説明します。 Filmarksは「国内最大級の映画レビューサービス」です。現時点(2018年8月23日22時頃)で5314万3638件のレビューが掲載されています。 よほどマイナーか人気のない映画でない限りレビューが投稿されている、と思います。 映画レビューサイトはFilmarks以外にもYahoo!映画や映画.com、みんなのシネマレビューなどがあります。 ほかにも映画レビューサイトはあるのになぜFilmarksからレビューを取得するのかというとまず「HTMLの構造が単純でスクレイピングしやすい」というのがあります。複雑なHTML構造をしていないため、スクレイピング初心者の方やPython初心者の方がスクレイピングを学ぶ入り口

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


