
第6回ゲームサーバ勉強会用資料です。 Webの技術の根幹となるHTTPやTCP/IPを軽くおさらいしたあと、 マルチプロセス、マルチスレッド、イベント駆動といったサーバアーキテクチャについて解析し、 さらにイベント駆動を実現するための非ブロッキングI/OとI/Oの多重化について解説します。


今日では HTTP(s) で API が公開されることは当たり前の時代ですが、エラーをアプリケーションにどう伝えるかは、個々の API の設計に依存していました。特に、HTTP ステータスコードは有限であり、元々持っている意味があるので、自由に使うことはできません。API はそのドメインごとにもっと複雑で細かなエラー情報があるはずで、それらはレスポンスボディに載せてアプリケーションに伝えることになりますが、その書式に規定は今までありませんでした。 HTTP API にて、アプリケーションにエラー情報を伝達するための(レスポンスボディに載せられる)標準的な形式が、RFC7807 Problem Details for HTTP APIs で定められています。適用例としては、以下のようになります。 HTTP/1.1 403 Forbidden Content-Type: application
a.md Chrome ExtensionのLive HTTP Headersを調査した。Firefox用のものではない。Firefox用のものではない。 https://chrome.google.com/webstore/detail/live-http-headers/iaiioopjkcekapmldfgbebdclcnpgnlo 11/7追記 類似 or 同様の方法で難読化scriptを埋め込んでいる拡張機能が大量にあったため、Googleに報告済み。 https://twitter.com/bulkneets/status/795260268221636608 English version: https://translate.google.com/translate?sl=ja&tl=en&js=y&prev=_t&hl=ja&ie=UTF-8&u=https%3A%2F%

[翻訳] Elixirのプロセスアーキテクチャ または私は如何にして心配するのを止めてクラッシュを愛するようになったか にもあるように Elixir においては例外処理は、それを頑張ってなんとかしようとするのではなく、軽量プロセスのコンテキストでむしろすすんでクラッシュさせてしまえ、というのが良い作法である。 クイズ番組で ○ か × か答えを選んで壁に突っ込んだ先に、正解ならクッションが、不正解なら泥水があるという企画があるが、それに喩えるなら 泥水だろうが何だろうが躊躇せずダイブしろ! というのが Elixir 流 (俺調べ) である。 もとい、クラッシュさせてどうするのかというと Supevisor を使って、別プロセスから該当プロセスを監視しておいて、クラッシュしてもアプリケーション全体としては間違いなく動いている状態を保証するのが正しい。 カッとなってちょっとそのための例を書いて

こちらです。Perl でいうと Devel::KYTProf に性質がちかい。 motemen/go-loghttp · GitHub (GoDoc) 使用例 たとえばこういうコードに… package main import ( "io" "log" "net/http" "os" ) func main() { resp, err := http.Get(os.Args[1]) if err != nil { log.Fatal(err) } io.Copy(os.Stdout, resp.Body) } % go run main.go http://example.com/ <!doctype html> ... 一行追加すると: package main import ( "io" "log" "net/http" "os" _ "github.com/motemen/go-lo

Something went wrong! Hang in there while we get back on track Writing an API is almost a given with modern web applications. I’d like to lay out some simple guidelines and best practises for Rails API testing. We need to determine what to test and why it should be tested. Once we’ve established what we will be writing tests for, we will set up RSpec to do this quickly and easily. Basically we’ll
このシリーズはHTTPリクエストの理解を通じてWebパフォーマンスの重要性について考える5章構成になっている。 【序章】HTTPリクエストは甘え 【CSS Sprite編】スプライト地獄からの解放 【WebFont編】ドラッグ&ドロップしてコマンド叩いてウェーイ 【DataURI編】遅延ロードでレンダリングブロックを回避 【終章】我々には1000msの猶予しか残されていない 1日目は、HTTPリクエストの概要について説明する。 例えに、私のポートフォリオページ(t32k.me)が表示されるまでの流れを見ていく。まず、検索からでも方法はなんでもよいが、ブラウザのURLバーにt32k.meと打ち込んでアクセスする。そのページを見にいくということは、つまりt32k.meに対してHTTPスキームでリクエストするということを意味している。 クライアントであるブラウザは入力されたURLを判断して、リソ
一般的な Web Programmer ならば、HTTP Status code はすべて暗記していると聞きました。 しかし、僕は初心者なので、なかなか覚えきれていないので、HTTPのステータスコードをさがすのに便利なツールを用意しました。 httpstatus-vim です。インストール方法は bundle かなんかで以下を追加して下さい。 mattn/httpstatus-vim - GitHub https://github.com/mattn/httpstatus-vim 使い方は以下のとおりです。 4xx なコードを列挙する。 :HttpStatus 4 400: Bad Request 401: Unauthorized 402: Payment Required 403: Forbidden 404: Not Found 405: Method Not Allowed 406

一般的な Web Programmer ならば、HTTP Status code はすべて暗記していると聞きました。 しかし、僕は初心者なので、なかなか覚えきれていないので、HTTPのステータスコードをさがすのに便利なツールを用意しました。App::httpstatus です。インストール方法は cpanm App::httpstatus です。というか依存とかないのでhttp://api.metacpan.org/source/TOKUHIROM/App-httpstatus-v1.0.0/httpstatus をコピーしてくればうごきます。 使い方は以下のとおりです。 4xx なコードを列挙する。 % httpstatus 4 400 Bad Request 401 Unauthorized 402 Payment Required 403 Forbidden 404 Not Foun
SPDYを知るSPDYという実験的なプロトコルがありまして、 SPDY - The Chromium Projects HTTP2.0はSPDYをベースに作られるかも、みたいな話も風の噂で聞いたりするのでじゃあどんなもんかなあと仕様を読んで見ました。 SPDY Protocol - Draft 2 - The Chromium Projects SPDY Protocol - Draft 3 - The Chromium Projects SPDYv2とSPDYv3というのがあって、基本的にはSPDYv3の方を読んどけばいいのかなあとは思います。 ただSPDYv2もすでにいろんなところで使われていますので、仕様書の「7.Incompatibilities with SPDY draft #2」の部分もチェックしておきましょう。 HTTP Layering over SPDYSPDYというの
先週と今週で夜なべして2つほどつまらぬGemを作りました。まず一つ目。 ScrymScrymというやつです。 authorNari/scrym ? GitHub http://rubygems.org/gems/scrym ScrymはSelf collecting Ruby Mutatorsという名前の略です。 何をするかというと、malloc/freeみたいなのを簡易的なMarkSweepでやるやつなんですね。 CRubyにはGCがありますが、Scrym::Mutator.mark(obj)とかすると対象のobjはGCから(ほぼ)管理されなくなり、その代わりにScrym::Mutator.collectの対象となります。 ふつうのMarkSweepみたくScrym::Mutator.collectと次のcollectの間でmarkしておけばそのオブジェクトは消されないし、markしなけ
The Web engineer's online toolboxというまとめ記事が便利そうだったので、実際に試しつつ抄訳してみました。(一部のコメントと体裁は変えています。) 目次 一覧 RequestBin httpリクエストを保存するエンドポイントを作ってくれる。 Create a RequestBin のボタンをクリックするとURLが表示されるので、そこをHTTPクライアントからたたくとRequestBin側にリクエスト内容が記録される。 ソースも公開されてるのでローカルで立ちあげることもできる。 githubのwebhookのhelpも参考にどうぞ。 Hurl httpリクエストを実行してくれる。パーマリンクも作ってくれるので、POSTリクエストもコピペで他の人と共有できる。 類似サービス: REST test test , Apigee console httpbin HTTP
HTTP status codes are three-digit numbers that are returned by servers to indicate the status of a client’s request. When a client (such as a web browser) makes a request to a server, the server will respond with a status code and a message indicating whether the request was successful or not. There are five classes of HTTP status codes, each identified by the first digit of the three-digit status

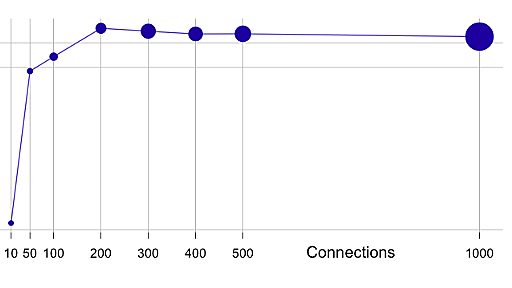
 500,000 requests/sec – Modern HTTP servers are fast
500,000 requests/sec – Modern HTTP servers are fast
A modern HTTP server running on somewhat recent hardware is capable of servicing a huge number of requests with very low latency. Here’s a plot showing requests per second vs. number of concurrent connections for the default index.html page included with nginx 1.0.14. With this particular hardware & software combination the server quickly reaches over 500,000 requests/sec and sustains that with gr
水風呂のすゝめ 毎日めちゃくちゃに暑い。 ここ数年「およげ!たいやきくん」のように昼間は太陽とオフィスビルとアスファルトの三方向から押し寄せる35℃オーバーの熱に挟まれ、夜になっても最低気温が27℃くらいまでしか下がらない。そんな理不尽な東京鍋の中の暮らしが毎年のことにな…

結論から言うと、強力な CPU と大容量のメモリを用意して Thread を大量に作るのが一番速い。 ださいことこの上無いが、これが速いんだから仕方ない。 def self.post tokens = [] User.all.each do |u| tokens << OAuth::AccessToken.new(consumer, u.token, u.secret_token) end tokens.each do |a| @t = Thread.start do res = a.post('/statuses/update.json', {:status => "なるほど四時じゃねーの"}) rescue nil end end @t.join end こんなの。本当にださいのだけど、これで十分なのだからしょうがない。というか Ruby でやる限りこれが一番速い。うちのそれなりのサー

Fiddler @sugamasao 先生もブログに書いてらっしゃる Fiddler は、全 Web 開発者必携のツールとも言える最高の HTTP プロキシというか HTTP スプーフィング・モニターツールですが、なんたることか MS 様謹製ゆえの Windows Only 。 ところが僕は今や会社も自宅も Ubuntu または OpenBSD である生粋の Unix ライクシステム野郎であり、 Fiddler つかえない!。あるのは WireShark だけ!。硬派すぎる!。レイヤー低すぎる!。もっとこうね、わかるでしょ?。素直にリクエストとレスポンスはまとまってて欲しいですし、レスポンスが JSON とか XML だったら特別なビューワで素敵に表示して欲しいですし、ポチポチと GUI で再リクエストしたりちょっとリクエストの内容変えてみたりレスポンス差し替えてみたりカジュアル感覚で H

Githubは、もはやファイアウォールの内側であってもread-onlyではない。 From now on, if you clone a repository over the http:// url and you are using a Git client version 1.6.6 or greater, Git will automatically use the newer, better transport mechanism. Even more amazing, however, is that you can now push over that protocol and clone private repositories as well. Smart HTTP Support | The GitHub Blog Githubはすばらしいサービスなのだが、数少ない欠

リリース、障害情報などのサービスのお知らせ
最新の人気エントリーの配信
j次のブックマーク
k前のブックマーク
lあとで読む
eコメント一覧を開く
oページを開く


