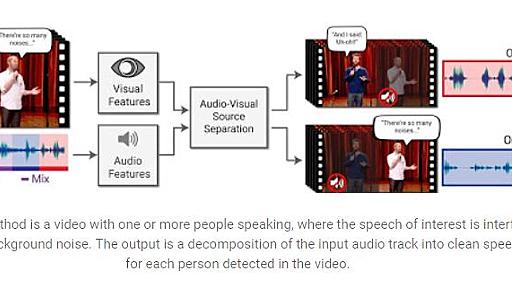
米Googleは4月11日(現地時間)、会話や騒音が多い中などの動画から、1人の人の声を分離するディープラーニングモデルについての論文「Looking to Listen at the Cocktail Party」を発表した。 人間は、パーティー会場のような複数の会話が進行している中でも、自分が聴きたい声を自然に聞き取る選択的聴取能力があり、一般に「カクテルパーティー効果」と呼ばれる。これを、ディープラーニングで再現しようというものだ。 サンプルの動画では、2人の男性がステージで同時に同じくらいの声量で話しているものを、一人ずつの声に切り分けて字幕をつけることに成功している。下の画像で、最初は2人同時の音声、右の男性の顔に枠が付いた段階では右の男性の声だけ、左の男性の顔に枠が付いた段階では左の男性の声だけが聞こえる。 この動画の音源はステレオではなく、ディープラーニングモデルが音声を切り