Language technologies are becoming more pervasive in our everyday lives, and they are also being applied in critical domains involving health, justice, and education. Given the importance of these applications and how they may affect our quality of life, it has become crucial to assess the errors they may make. In characterizing patterns of error, it has been found that systems obtained by machine-learning(ML) techniques from large quantities of text, such as large language models (LLMs), reproduce and amplify stereotypes.
4 When deployed in actual applications, amplification of stereotypes can result in discriminatory behavior considered harmful in many jurisdictions.
This kind of behavior is known as
social bias, in that errors are distributed unevenly across social groups. Motivated by this problem, research about fairness in computational applications and in language technologies has grown considerably in recent years.
6 However, most of this research is based on languages and representations of social biases originating in Global North cultures.
Research about fairness in computational applications and in language technologies has grown considerably in recent years.
Currently, the most studied social biases are gender and race, defined from a U.S.- and European-centric cultural perspective. Moreover, methods to measure biases often rely on language-specific characteristics of English that do not apply to other languages. Therefore, most methods proposed in the literature cannot be directly applied to the assessment of biases for language technologies in Latin America.
Methods to measure biases often rely on language-specific characteristics of English that do not apply to other languages.
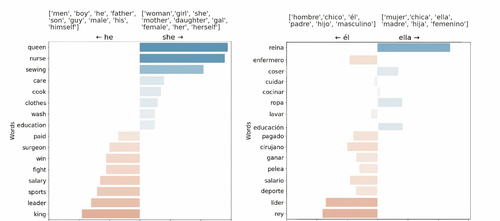
The accompanying figure shows how a set of the same words in Spanish and English have quite different biases. Some methods rely on gender-neutral words to assess whether a given model behaves equitably for gender, but most gender-neutral words do not exist in gendered languages. In English, it is possible to measure whether the word “programmer,” which can be used to refer to both a male or a female, is more strongly associated with words representing feminine or masculine concepts. However, in many languages throughout our region, such gender-neutral words are not as frequent as in English, and therefore this method is inadequate to detect unfair behavior. The gender-neutral word “programmer” does not exist in Spanish; it must be used either in feminine (“programadora”) or masculine (“programador”) forms. Moreover, even gender-neutral words do not represent the same concepts in English and other languages, or even variants of the same language, as the meaning of words is strongly culture-dependent. For example, we found the word “sports” is more strongly associated with words representing the masculine in resources developed for English than in resources for Spanish. Thus, methods developed for English cannot be applied directly, and culture-specific resources must be built, not translated, from predominant cultures.
Fortunately, pre-trained language models specifically for Spanish have been developed. BETO,
7 for example, is exclusively trained on Spanish data, providing researchers with a valuable and promising resource for evaluating biases specific to the Spanish language. This offers a more culturally relevant resource compared to models pre-trained on multilingual corpora, which can generate our languages but exhibit biases from English cultures.
8Even given the language-specific resources, a proper characterization of social biases in language technologies requires that experts in discrimination are engaged, be it social scientists, professionals working with vulnerable groups, or people with personal experiences in discrimination. Most bias assessment methods require programming, statistics, and machine-learning skills, especially those applied in the first stages of development, before an application is deployed and potentially causing harm. For example, frameworks such as WEFE
2 constitute a useful tool for encapsulating, evaluating, and comparing different fairness metrics in language models. However, the technical skills required to leverage the capabilities of such a powerful framework are beyond the capabilities of most people with expertise on discrimination and social biases.
EDIA (Stereotypes and Discrimination in Artificial Intelligence) is a long-term project aimed to empower Latin American social scientists and domain experts in detecting and analyzing biases in language models. We have developed a tool that enables intuitive manipulation of textual representations, allowing experts to explore both hypothesized and emergent biases in artifacts used in the backbone of most language technologies, namely word embeddings and generative language models. By focusing on linguistic manifestations of discrimination rather than mathematical concepts, the EDIA tool reduces technical barriers and fosters collaboration between disciplines, while at the same time providing experts with enough flexibility and additional information to adequately model the phenomena of interest, such as morphologically gendered languages, non-binary continuums of meaning, unmarked concepts,
3 and multiword expressions. A demo version of this tool is available at
https://huggingface.co/spaces/vialibre/edia and as a library in
https://github.com/fvialibre/edia, where it can be used with more than 50 natural languages.
We have evaluated the effectiveness of EDIA in five hands-on workshops involving around 300 people, showing how it allows experts to represent their biases of interest and audit them in particular language models. In a joint effort between academic and civil society actors, we gathered diverse groups of experts from different provinces in Argentina, Uruguay, Costa Rica, México, and Colombia. Participants from diverse backgrounds, including social scientists, domain experts, machine-learning specialists, and interested communities, engaged in a multidisciplinary exploration of social biases in language models. In three-hour sessions, experts were able to produce satisfactory, formal representations of biases specific to their own culture and to the whole of Latin America. For example, nutritionists studying the perception of a healthy diet in social networks found a synonym association between “ugly” and “fat” that was stronger for the feminine forms of those words than for masculine forms. Other participants were able to formalize common stereotypes about laziness in different provinces of Argentina, and found their hypothesis validated in the behavior of language models. Stereotypes about journalists being liars, or Paraguayans being worse at managing money than Germans, were also validated with the actual data obtained from the exploration of models. Further detail about the workshops, including the preliminary workshops that guided the design of the tool, can be found in Alonso Alemany et al.
1We expect that EDIA will be a compelling feasibility test to promote wide adoption of bias assessment in Latin America and the world. We will use EDIA to carry out community-centered methods to build a language dataset that represents stereotypes in Argentina; publish programming libraries to integrate the dataset in audit processes for public and private institutions that use language models; and publish structured content and teaching materials so that others can replicate our methods for other languages and contexts. We hope this and other projects will foster the creation of repositories of culture-specific resources that represent harmful stereotypes according to different social groups (like Dev et al.
9, Fort et al.
10), to facilitate starting assessments of fairness in language applications.
Hernán Maina, Universidad Nacional de Córdoba and CONICET, Argentina.
Laura Alonso Alemany, Universidad Nacional de Córdoba, Argentina.
Guido Ivetta, Universidad Nacional de Córdoba, Argentina.
Mariela Rajngewerc, Universidad Nacional de Córdoba and CONICET, Argentina.
Beatriz Busaniche, Fundación Vía Libre, Argentina.
Luciana Benotti, Universidad Nacional de Córdoba and CONICET, Argentina.