
Abstract
Millions of people across the world are suffering from diabetic retinopathy. This disease majorly affects the retina of the eye, and if not identified priorly causes permanent blindness. Hence, detecting diabetic retinopathy at an early stage is very important to safeguard people from blindness. Several machine learning (ML) algorithms are implemented on the dataset of diabetic retinopathy available in the UCI ML repository to detect the symptoms of diabetic retinopathy. But, most of those algorithms are implemented individually. Hence, this article proposes an effective integrated ML approach that uses the support vector machine (SVM), principal component analysis (PCA), and moth-flame optimization techniques. Initially, the ML algorithms decision tree (DT), SVM, random forest (RF), and Naïve Bayes (NB) are applied to the diabetic retinopathy dataset. Among these, the SVM algorithm is outperformed with an average of 76.96% performance. Later, all the aforementioned ML algorithms are implemented by integrating the PCA technique to reduce the dimensions of the dataset. After integrating PCA, it is noticed that the performance of the algorithms NB, RF, and SVM is reduced dramatically; on the contrary, the performance of DT is increased. To improve the performance of ML algorithms, the moth-flame optimization technique is integrated with SVM and PCA. This proposed approach is outperformed with an average of 85.61% performance among all the other considered ML algorithms, and the classification of class labels is achieved correctly.
1 Introduction
Several classification techniques of machine learning (ML) algorithms were discussed, and these techniques greatly helped the stakeholders of the medical field for predicting heart disease. A model of the artificial neural network (ANN) was proposed by Dangare and Apte was outperformed with 100% accuracy [1]. To detect anomalies in hyperglycemia classification, techniques such as feedforward ANN, deep belief network, genetic algorithm (GA), support vector machine (SVM), and Bayesian neural network were proposed and implemented [2]. Some of the ML techniques were rarely implemented or not implemented at all. Besides, the accuracy of some ML techniques was lower than the accuracy obtained by DL techniques. Hence, the combined models of ML and deep learning (DL) techniques were discussed to enhance accuracy for diabetes prediction [3]. The principal component analysis (PCA) was discussed to deal with large datasets. The dimensions of these large datasets could be reduced by using PCA to observe the correlation between the attributes and for better interpretability [4]. Diabetic retinopathy would affect eyes. The current trends of disease, mechanisms, and approaches to treat diabetic retinopathy were discussed [5]. A system with ML algorithms namely,
1.1 State-of-the art literature review
The aforementioned works represent various ML algorithms and their corresponding accuracies in the medical diagnosis. In this section, in addition to mentioned earlier, some more state-of-the-art related works are presented as follows: PCA-based techniques were discussed in refs [11,12, 13,14], where PCA and
2 Proposed methodology and implementation
To implement the proposed methodology, the dataset diabetic retinopathy is retrieved from the UCI ML repository. The proposed techniques such as normalization, PCA, and SVM are briefly described as follows. The dimensions of a dataset may consist of different levels of data. If the dataset is directly taken for the computation process, the higher-ordered dimensions may dominate the other lower-ordered dimensions. The obtained result is no way useful for decision-making. So, it is necessary to scale the data to make all the dimensions to be at the same level. The normalization technique scales the data and removes anomalies existing in the data. This is a preprocessing technique generally applied to the dataset before proceeding with the analysis process. The normalized data usually lies between 0 and 1. The main functionality of the PCA is to reduce the dimensions of a dataset. This is also referred to as dimensionality reduction. When a dataset contains more dimensions, several dimensions might be highly correlated. This problem is referred to as multicollinearity. The existence of multicollinearity affects the quality of data analysis. The PCA technique is best to deal with the multicollinearity problem. The main elements in PCA are principal components (PCs). The generation of the number of PCs is based on the number of dimensions given as input. The same number of PCs will be generated for the given number of dimensions, and they are ordered by their variance. PCs with high variance come first and then next higher level and so on. SVM is one of the most widely used supervised ML techniques. It is largely used for classification in high-dimensional data. It can be applied to both linearly and non-linearly separable problems. The key elements of the SVM are hyperplanes. In SVM, the classification of data will be done by identifying the hyperplanes. Support vectors are the vectors that describe the hyperplanes. In Section 2.1, the description of the dataset is given. In Section 2.2, the algorithm and objective function for the moth-flame optimization technique is described. The flow of activities in the proposed model is shown in Figure 1.

Flowchart for the proposed integrated ML approach.
As an initial step, the collected diabetic retinopathy dataset is inputted to the proposed model. The details of the retinal images presented in this dataset are used to classify the images and to decide whether there are any symptoms of the diabetic retinopathy existing. Before proceeding to implement ML algorithms, it is important to normalize the data. This normalization can be done by using a standard scaler. After normalization, the ML algorithms such as DT, NB, RF, and SVM will be individually applied to the dataset. Next, the PCA technique is implemented for reducing the features in the dataset. This feature reduction will enable all the features to be at the same level. It means that the domination of higher-order features will be avoided. Now, the reduced features are inputted into aforesaid ML algorithms. The performance of ML algorithms before and after the implementation of PCA is observed. If high performance is observed, then we can continue with the recently applied technique. Otherwise, to improve the performance of ML algorithms, the resultants of previously applied techniques are feeded into the proposed integrated approach, i.e., SVM + PCA + moth-flame optimization technique. Then, the performance of ML algorithms was evaluated and compared concerning the performance measures discussed in Section 1.1. By looking into the comparative analysis, it can be understood that the ML approach that outperformed among all the others represents the correct classification of class labels.
2.1 Dataset description
The diabetic retinopathy dataset comprises 20 features that represent the Messidor image set. Extracted features from an image will reveal the existence and non-existence of diabetic retinopathy. Features represented in the dataset will provide the information on any detected injury/lesion or description of the image. All 20 features are numbered from 0 through 19 as presented in Table 1. In the dataset, feature 0 consists of the values related to the quality of the image. If lesions are identified effectively in the captured image, it is said to have good quality otherwise bad quality. This quality is represented with binary values 1 and 0. The existence of value 1 means, the image contains good quality, and the value 0 means, the image contains bad quality. Feature 1 consists of the details of pre-screening. This feature is also described with binary values 1 and 0. The existence of value 1 represents that there is a severe abnormality and 0 represents no abnormality in the retina. Features from 2 to 7 consist of the number of values detected that is related to microaneurysms (MA). The microaneurysms cause blood leakage to the tissues of the retina. These MA values are detected with confidence intervals from 0.5 through 1. Features from 8 to 15 consist of the normalized values related to exudates. These are represented as same as the features from 2 to 7. The normalization makes all the features to be at the same level. Feature 16 gives the Euclidean distance information between the centers of the macula and optic disc. Feature 17 consists of the details of the optic disc diameter. The starting point of retinal blood vessels is an optic disc. Feature 18 consists of the binary values related to the classification based on the modulations AM and FM. Finally, feature 19 consists of the binary values related to class labels. The value 1 represents the existence of symptoms of diabetic retinopathy, and 0 represents no symptoms existing.
Description of dataset features
| Feature number | Description of feature |
|---|---|
| 0 | Image quality is represented as binary values 1 and 0. 1 = good quality, and 0 = bad quality |
| 1 | Pre-screening information is represented as binary values 1 and 0. 1 = severe abnormality in the retina, and 0 = no abnormality |
| 2–7 | These features represent the number of MA values detected. MA causes retinal blood leakage. These features show the results at confidence intervals 0.5 through 1 respectively |
| 8–15 | Same as 2–7 for exudates. These are normalized to make all the features at the same level |
| 16 | This feature gives Euclidean distance information between the centers of the macula and optic disc |
| 17 | This feature contains information about optic disc diameter |
| 18 | The binary values of classification based on amplitude modulation (AM) and frequency modulation (FM) |
| 19 | Class labels are represented as binary values 1 and 0. 1 = symptoms of diabetic retinopathy, and 0 = no symptoms |
2.2 Proposed algorithm
The general phenomenon of the moth-flame optimization technique is described as follows. The moth-flame optimization technique also referred to as a population-based technique. In this technique, both moths and flames are said to be solutions. The moths are said to be agents of search space, and flames are said to be the best positions. The difference between these two depends on the update of each iteration. By updating the position at each iteration, the moth never misses the best position. The steps of the proposed technique are given in Algorithm 1.
| Algorithm 1 Algorithm for moth-flame optimization technique | |
|---|---|
| 1: | Initiate the parameters. |
| 2: | Initiate the generation of moths randomly. |
| 3: | Identify the fitness functions and mark the best positions of flames. |
| 4: | Update flame numbers. |
| 5: | Calculate distance related to moth. |
| 6: | Update the positions related to moth. |
| 7: | Repeat the steps 2–6 until the expected criteria achieved. |
| 8: | If criteria are achieved report the best positions of moths. |
2.3 Objective function
The objective function of moth-flame is given in equations (1)–(11) as follows: initialization of moths is represented in a matrix as shown in (1):
where
Initialization of flames is represented in a matrix ss shown in equation (3):
where
The mathematical model of moth-flame optimization technique represented as a three-tuple is given in equation (5):
The function
The function
The equation for updating the position is given in equation (9):
where
where
where
3 Results and discussion
The implementation of ML algorithms was performed on a diabetic retinopathy dataset retrieved from the UCI ML repository. The performance of the proposed integrated ML model is evaluated using measures such as precision,
where PT = positive (true value), PF = positive (false value), NT = negative (true value), and NF = negative (false value). The simulation results of ML algorithms and corresponding performance measures are described as follows: First, the dataset has experimented with four popular ML algorithms, namely, DT, NB, RF, and SVM. Figure 2 depicts the performance of these algorithms.
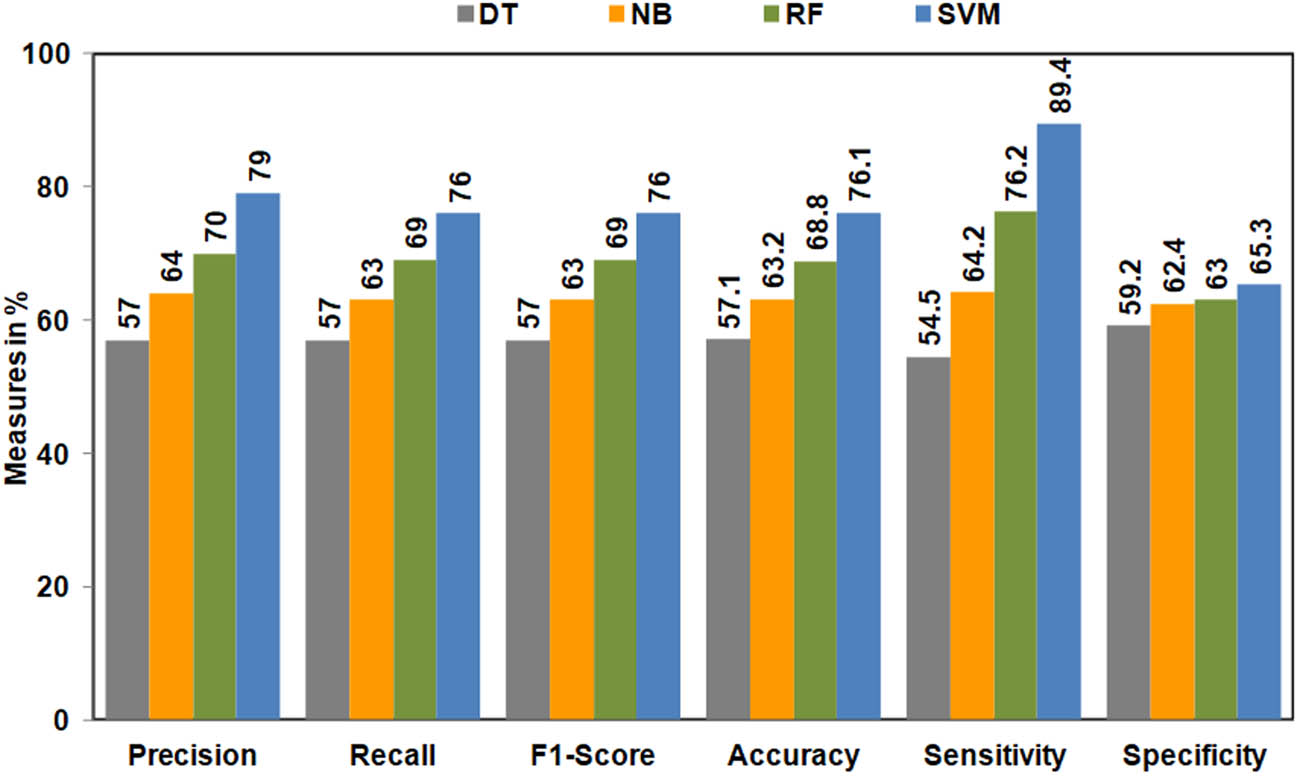
Performance of ML algorithms on the original dataset.
From Figure 2, it can be observed that the DT classifier has achieved 57% of precision, recall, and
The dataset is then fed in to the PCA for dimensionality reduction. The PCA has reduced the dataset from 20 dimensions to 12 dimensions. These reduced features of the dataset are given as input to the aforementioned classifiers. Figure 3 depicts the results obtained after applying ML algorithms on reduced dimensions.
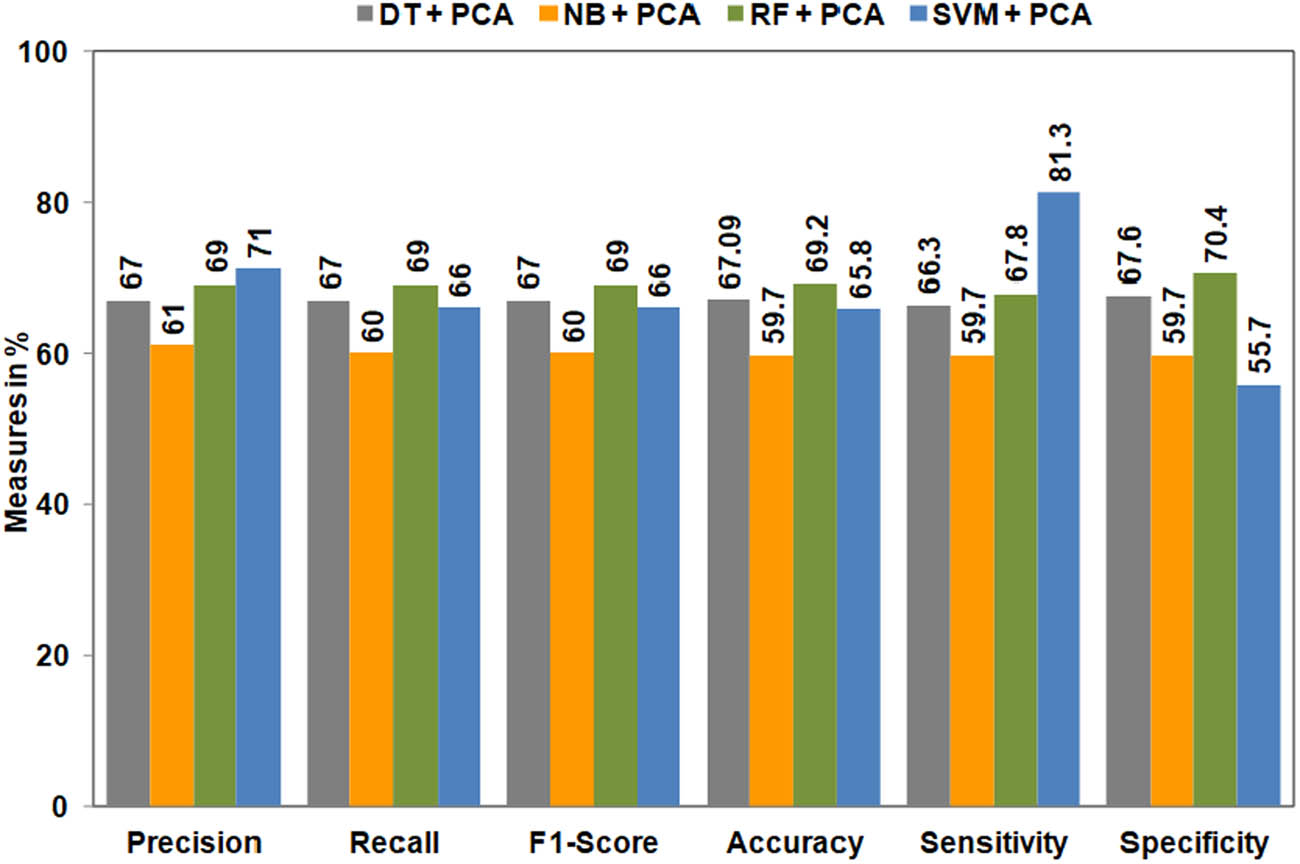
Performance of ML algorithms after reducing dimensions using PCA.
From Figure 3, it can be observed that the DT classifier has achieved 67% of precision, recall, and
To achieve better performance of PCA-based classifiers, the moth-flame optimization technique is applied. This technique eliminated the attributes that are affecting the performance of the classification model negatively. It chooses the optimal features/attributes that have a positive impact on performance. By implementing the moth-flame technique, the 12 dimensions were further reduced to 9. Based on this reduction, it is understood three dimensions are affecting the performance of the model. These three dimensions are eliminated by the moth-flame algorithm. Figure 4 depicts the result of the model with PCA and moth-flame optimization techniques.
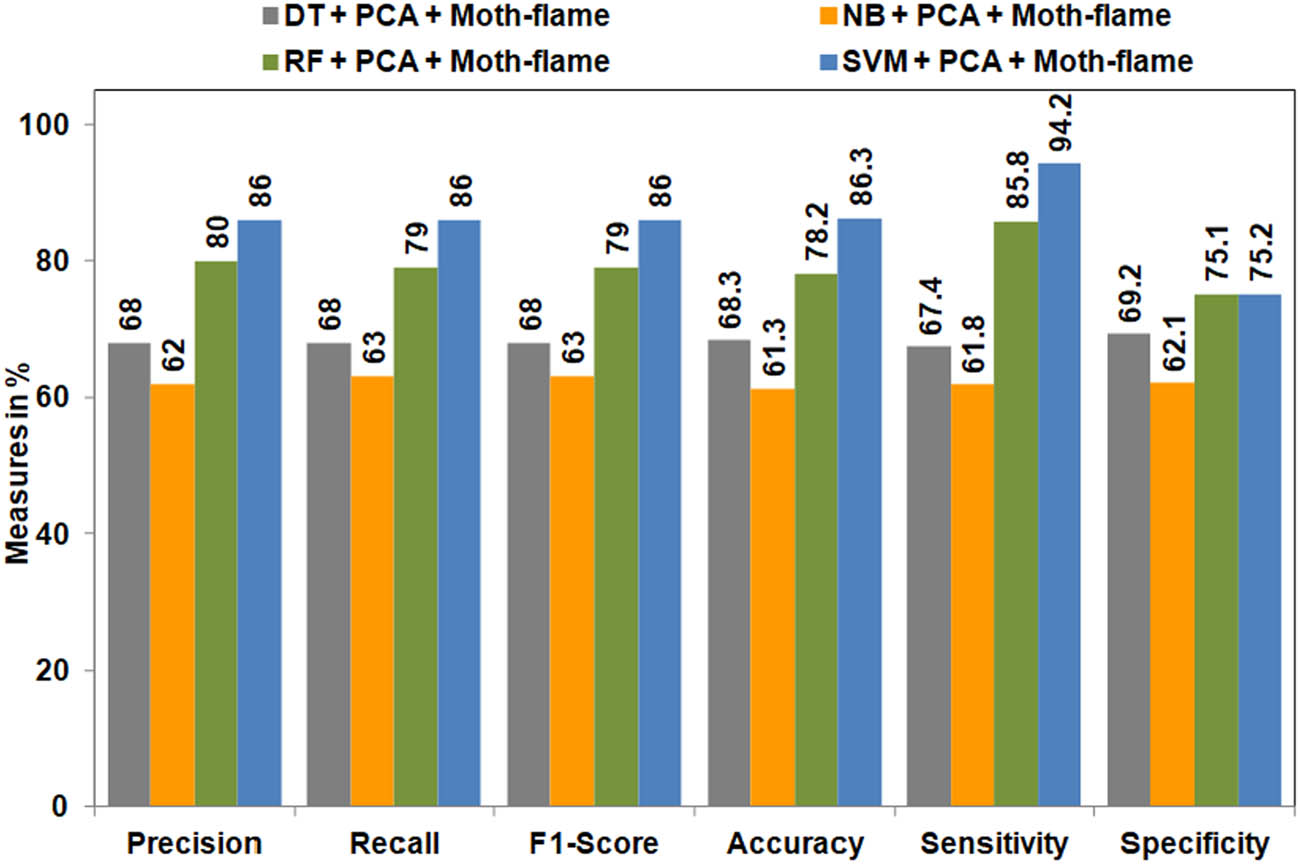
Performance of ML algorithms after implementation of moth-flame optimization technique.
Figure 4 shows that the DT classifier has achieved 68% of precision, recall, and
Performance summary of ML algorithms
| ML algorithms | Prscn | Rcl |
|
Acc | Sens | Spec |
|---|---|---|---|---|---|---|
| DT | 57 | 57 | 57 | 57.1 | 54.5 | 59.2 |
| NB | 64 | 63 | 63 | 63.2 | 64.2 | 62.4 |
| RF | 70 | 69 | 69 | 68.8 | 76.2 | 63 |
| SVM | 79 | 76 | 76 | 76.1 | 89.4 | 65.3 |
| DT + PC | 67 | 67 | 67 | 67.09 | 66.3 | 67.6 |
| NB + PC | 61 | 60 | 60 | 59.7 | 59.7 | 59.7 |
| RF + PC | 69 | 69 | 69 | 69.2 | 67.8 | 70.4 |
| SVM + PC | 71 | 66 | 66 | 65.8 | 81.3 | 55.7 |
| DT + PC + MF | 68 | 68 | 68 | 68.3 | 67.4 | 69.2 |
| NB + PC + MF | 62 | 63 | 63 | 61.3 | 61.8 | 62.1 |
| RF + PC + MF | 80 | 79 | 79 | 78.2 | 85.8 | 75.1 |
| SVM + PC + MF | 86 | 86 | 86 | 86.3 | 94.2 | 75.2 |
4 Conclusion
To identify the diabetic retinopathy, this article proposed an integrated approach of ML algorithms and achieved high performance. The dataset that is retrieved from the UCI ML repository is used for the proposed approach. The key observations of the proposed integrated approach are as follows:
From Figure 2, it is observed that when the ML algorithms are implemented individually, SVM is outperformed than other ML algorithms.
From Figure 3, it is evident that the reduction of the dimensions using the PCA technique has negatively influenced the performance of majority ML algorithms.
From Figure 4, it is understood that the integration of SVM, PCA, and moth-flame optimization techniques improved the performance of classification and identified the class labels correctly.
From Table 2, it is easy to interpret and compare the performances achieved by the implemented ML algorithms.
-
Conflict of interest: Authors state no conflict of interest.
-
Data availability statement: The datasets generated during and/or analyzed during the current study are available in the Diabetic Retinopathy Debrecen Data Set, https://archive.ics.uci.edu/ml/datasets/Diabetic+Retinopathy+Debrecen+Data+Set.
References
[1] C. S. Dangare and S. S. Apte, “Improved study of heart disease prediction system using data mining classification techniques,” Int J Comput Appl., vol. 47, no. 10, pp. 44–48, 2012. 10.5120/7228-0076Search in Google Scholar
[2] J. D. Elia, J. K. Sun, and W. S. Alan, “Diabetic retinopathy: current understanding mechanisms, and treatment strategies,” JCI Insight, vol. 2, pp. 1–13, 2017. 10.1172/jci.insight.93751Search in Google Scholar PubMed PubMed Central
[3] M. I. Al-janabi, M. H. Qutqut, and M. Hijjawi, “Machine learning classification techniques for heart disease prediction: a review,” Int J Eng Technol., vol. 7, pp. 5373–5379, 2018. Search in Google Scholar
[4] A. W. Zebene, A. Eirik, T. Botsis, D. Albers, M. Lena, and H. Gunnar, “Data-driven blood glucose pattern classification and anomalies detection: machine-learning applications in type 1 diabetes,” J Med Internet Res., vol. 21, pp. 1–18, 2019. 10.2196/11030Search in Google Scholar PubMed PubMed Central
[5] S. L. M. Sainte, A. Linah, A. Rana, and T. Saba, “Current techniques of diabetes prediction: review and case study,” Appl. Sci., vol. 9, pp. 1–19, 2019. 10.3390/app9214604Search in Google Scholar
[6] A. Javeria, M. Sharif, M. Yasmin, H. Ali, and S. F. Lawrence, “A method for the detection and classification of diabetic retinopathy using structural predictors of bright lesions,” J. Comput. Sci., vol. 19, pp. 153–164, 2017. 10.1016/j.jocs.2017.01.002Search in Google Scholar
[7] F. Cut, E. M. Sipayung, and M. Siti, “Analysis and prediction of diabetes complication disease using data mining algorithm,” Proc. Comput. Sci., vol. 161, pp. 449–457, 2019. 10.1016/j.procs.2019.11.144Search in Google Scholar
[8] G. Sumalatha and N. J. R. Muniraj, “Survey on medical diagnosis using data mining techniques,” International Conference on Optical Imaging Sensor and Security, Coimbatore, India, 2013. 10.1109/ICOISS.2013.6678433Search in Google Scholar
[9] R. Ghosh, G. Kuntal, and S. Maitra, “Automatic detection and classification of diabetic retinopathy stages using CNN,” International Conference on Signal Processing and Integrated Networks, Noida, India, 2017. 10.1109/SPIN.2017.8050011Search in Google Scholar
[10] A. E. Ahmed, A. T. Sahlol, and A. A. Mohamed, “A bio-inspired Moth-flame optimization algorithm for Arabic handwritten letter recognition,” International Conference on Control Artificial Intelligence, Robotics & Optimization, Prague, Czech Republic, 2017. Search in Google Scholar
[11] C. Zhu, C. I. Uwa, and W. Feng, “Improved logistic regression model for diabetes prediction by integrating PCA and K-means techniques,” Informatic Med Unlocked, vol. 17, pp. 1–7, 2019. 10.1016/j.imu.2019.100179Search in Google Scholar
[12] G. T. Reddy, M. P. K. Reddy, K. Lakshmanna, R. Kaluri, D. S. Rajput, G. Srivastava, et al., “Analysis of dimensionality reduction techniques on big data,” IEEE Access, vol. 8, pp. 54776–54788, 2020. 10.1109/ACCESS.2020.2980942Search in Google Scholar
[13] T. R. Gadekallu, N. Khare, S. Bhattacharya, S. Singh, P. K. R. Maddikunta, I. H. Ra, et al., “Early detection of diabetic retinopathy using PCA-firefly-based deep learning model,” Electronics, vol. 9, pp. 1–16, 2020. 10.3390/electronics9020274Search in Google Scholar
[14] S. Bhattacharya, S. R. K. S, P. K. R. Maddikunta, R. Kaluri, S. Singh, T. R. Gadekallu, et al., “A novel PCA-firefly-based XGBoost classification model for intrusion detection in networks using GPU,” Electronics, vol. 9, pp. 1–16, 2020. 10.3390/electronics9020219Search in Google Scholar
[15] J. S. Salimi, M. Z. Hossein, and K. Mozafari, “Hepatitis disease diagnosis using a novel hybrid method based on support vector machine and simulated annealing (SVM-SA),” Comput. Meth. Prog. Bio., vol. 108, pp. 570–579, 2012. 10.1016/j.cmpb.2011.08.003Search in Google Scholar PubMed
[16] L. Shen, H. Chen, Z. Yu, W. Kang, B. Zhang, H. Li, et al., “Evolving support vector machines using fruit fly optimization for medical data classification,” Knowledge-Based Syst., vol. 96, pp. 61–75, 2016. 10.1016/j.knosys.2016.01.002Search in Google Scholar
[17] S. Poornima, S. Singh, and G. S. J. Pandi, “Effective heart disease prediction system using data mining techniques,” Int. J. Nanomed., vol. 13, pp. 121–124, 2018. 10.2147/IJN.S124998Search in Google Scholar PubMed PubMed Central
[18] H. D. Jude, D. Omer, and U. Kose, “An enhanced diabetic retinopathy detection and classification approach using deep convolutional neural network,” Intell. Biomed. Data Anal. Process., vol. 32, pp. 707–721, 2019. 10.1007/s00521-018-03974-0Search in Google Scholar
[19] T. Mahboob Alam, M. A. Iqbal, Y. Ali, A. Wahab, S. Ijaz, T. Imtiaz Baig, et al., “A model for early prediction of diabetes,” Informatics Med. Unlocked, vol. 16, pp. 1–6, 2019. 10.1016/j.imu.2019.100204Search in Google Scholar
[20] H. Chirath and C. Charith, “A Machine learning approach to predict diabetes using short recorded photoplethysmography and physiological characteristics,” Artif. Intell. Med., vol. 11526, pp. 322–327, 2019. 10.1007/978-3-030-21642-9_41Search in Google Scholar
[21] W. Mitesh, V. Kumar, S. Tarale, G. Payal, and D. J. Chaudhari, “Diabetes diagnosis using machine learning algorithms,” Int. Res. J. Eng. Technol., vol. 6, pp. 1470–1476, 2019. Search in Google Scholar
[22] G. Rishab and T. Leng, “Automated identification of diabetic retinopathy using deep learning,” Ophthalmology, vol. 124, pp. 962–969, 2017. 10.1016/j.ophtha.2017.02.008Search in Google Scholar PubMed
[23] S. Qummar, F. G. Khan, S. Shah, A. Khan, S. Shamshirband, Z. U. Rehman, et al., “A deep learning ensemble approach for diabetic retinopathy detection,” IEEE Access, vol. 7, pp. 150530–150539, 2019. 10.1109/ACCESS.2019.2947484Search in Google Scholar
[24] J. Sahlsten, J. Jaskari, J. Kivinen, L. Turunen, E. Jaanio, K. Hietala, et al., “Deep learning fundus image analysis for diabetic retinopathy and macular edema grading,” Sci. Rep., vol. 9, pp. 1–11, 2019. 10.1038/s41598-019-47181-wSearch in Google Scholar PubMed PubMed Central
[25] R. A. Welikala, M. M. Fraz, J. Dehmeshki, A. Hoppe, V. Tah, S. Mann, et al., “Genetic algorithm based feature selection combined with dual classification for the automated detection of proliferative diabetic retinopathy,” Computerize. Med. Imag. Graphic., vol. 43, pp. 64–77, 2015. 10.1016/j.compmedimag.2015.03.003Search in Google Scholar PubMed
[26] C. G. Babu and S. P. Shantharajah, “An optimized feature selection based on genetic approach and support vector machine for heart disease,” Cluster Comput., vol. 22, pp. 14777–14787, 2019. 10.1007/s10586-018-2416-4Search in Google Scholar
[27] T. G. Reddy, M. K. R. Praveen, L. Kuruva, R. D. Singh, K. Rajesh, and S. Gautam, “Hybrid genetic algorithm and a fuzzy logic classifier for heart disease diagnosis,” Evolut. Intell., vol. 13, pp. 185–196, 2019. 10.1007/s12065-019-00327-1Search in Google Scholar
[28] B. Antal and H. Andras, “An ensemble-based system for automatic screening of diabetic retinopathy,” Knowledge-Based Syst., vol. 60, pp. 20–27, 2014. 10.1016/j.knosys.2013.12.023Search in Google Scholar
[29] M. Seyedali, “Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm,” Knowledge-Based Syst., vol. 89, pp. 228–249, 2015. 10.1016/j.knosys.2015.07.006Search in Google Scholar
[30] R. G. Thippa and N. Khare, “Hybrid firefly-bat optimized fuzzy artificial neural network based classifier for diabetes diagnosis,” Int. J. Intell. Eng. Syst., vol. 10, pp. 18–27, 2017. 10.22266/ijies2017.0831.03Search in Google Scholar
[31] C. Iwendi, P. K. R. Maddikunta, G. T. Reddy, L. Kuruva, B. K. Ali, and M. P. Jalil, “A metaheuristic optimization approach for energy efficiency in the IoT networks,” Softw: Pract Exper, vol. 51, pp. 1–14, 2020. 10.1002/spe.2797Search in Google Scholar
[32] C. A. Jake, C. S. Long, P. S. Beth, T. L. Smith, and L. D. George, “Combining elemental analysis of toenails and machine learning techniques as a non-invasive diagnostic tool for the robust classification of type-2 diabetes,” Expert Syst. Appl., vol. 115, pp. 245–255, 2019. 10.1016/j.eswa.2018.08.002Search in Google Scholar
[33] X. Jia, B. M. Mirja, M. Farhaan, and G. H. Hamid, “A cox-based risk prediction model for early detection of cardiovascular disease: Identification of key risk factors for the development of a 10-year CVD risk prediction,” Adv. Preventive Med., vol. 2019, pp. 1–11, 2019. 10.1155/2019/8392348Search in Google Scholar PubMed PubMed Central
[34] B. M. Donovan, P. J. Breheny, J. G. Robinson, R. J. Baer, A. F. Saftlas, W. Bao, et al., “Development and validation of a clinical model for preconception and early pregnancy risk prediction of gestational diabetes mellitus in nulliparous women,” PLoS ONE, vol. 14, pp. 1–21, 2019. 10.1371/journal.pone.0215173Search in Google Scholar PubMed PubMed Central
[35] Q. Wang, C. Weijia, J. Guo, J. Ren, C. Yongqiang, and D. N. Davis, “DMP-MI: An effective diabetes mellitus classification algorithm on imbalanced data with missing values,” IEEE Access, vol. 7, pp. 102232–102238, 2019. Search in Google Scholar
© 2022 Penikalapati Pragathi and Agastyaraju Nagaraja Rao, published by De Gruyter
This work is licensed under the Creative Commons Attribution 4.0 International License.