
Multiscale Hybrid Convolutional Deep Neural Networks with Channel Attention

Abstract
:1. Introduction
- An effective MA module is proposed, which can extract multi-scale spatial information and establish channel long-range dependence. MA is a plug and play module that can be applied to various computer vision task architectures to improve the performance of the model.
- An effective backbone network EMANet is obtained by using the MA module instead of 3 × 3 convolution in the ResNet network, which can obtain rich feature information.
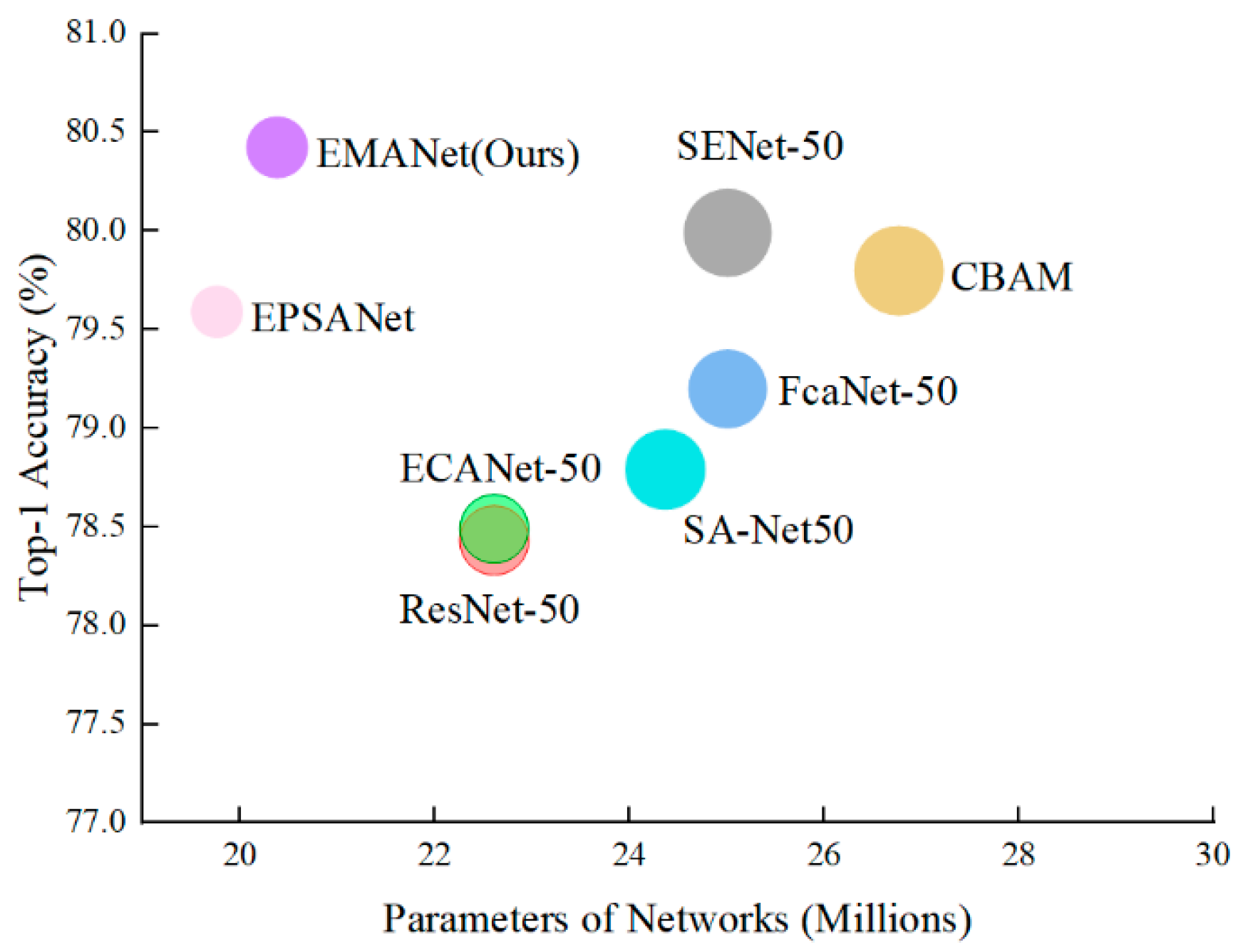
- Experimental results on mini-ImageNet, CIFAR-10 and PASCAL-VOC2007 datasets indicate that the proposed EMANet network achieves a distinguished performance compared with other attention networks while maintaining low complexity.
2. Methods
2.1. Channel Attention Module
2.2. Hybrid Attention Module
2.3. Network Design
3. Experimental Verification and Results Analysis
3.1. Dataset
3.2. Experimental Parameter Settings
3.3. Image Classification Results
3.4. Network Visualization Results
3.5. Object Detection Results
3.6. Ablation Study
- Convolution group size
- 2.
- Mixed operation kernel size
4. Conclusions
- The MA module will be further improved to become a lightweight plug and play module.
- We will use Mask-RCNN and RetinaNet detectors to verify the generalization ability of the EMANet model on the MS-COCO dataset.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Accuracy (%) |
|---|---|
| Baseline | 95.45 |
| +BN | 95.44 |
| +IEBN | 95.19 |
| +SoftBAN | 95.61 |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovic, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference for Learning Representations (ICLR), Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Zhou, D.; Shi, Y.; Kang, B.; Yu, W.; Jiang, Z.; Li, Y.; Jin, X.; Hou, Q.; Feng, J. Refiner: Refining Self-attention for Vision Transformers. arXiv 2021, arXiv:2106.03714. [Google Scholar]
- Rui, C.; Youwei, G.; Huafei, Z.; Hongyu, J. A Comprehensive Approach for UAV Small Object Detection with Simulation-based Transfer Learning and Adaptive Fusion. arXiv 2021, arXiv:2109.01800. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, X.; Hu, X.; Yang, J. Spatial group-wise enhance: Improving semantic feature learning in convolutional networks. arXiv 2019, arXiv:1905.09646. [Google Scholar]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract Your Attention: Multi-head Cross Attention Network for Facial Expression Recognition. arXiv 2022, arXiv:2109.07270. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global Second-Order Pooling Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Trockman, A.; Kolter, J.Z. Patches Are All You Need? In Proceedings of the International Conference on Learning Representations (ICLR), Amster, MA, USA, 25–29 April 2022. [Google Scholar]
- Zhang, H.; Zu, K.; Lu, J.; Zou, Y.; Meng, D. EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network. arXiv 2021, arXiv:2105.14447. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling Up Your Kernels to 31 × 31: Revisiting Large Kernel Design in CNNs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Liang, S.; Huang, Z.; Liang, M.; Yang, H. Instance Enhancement Batch Normalization: An Adaptive Regulator of Batch Noise. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 7–12 February 2020. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Ding, X.; Chen, H.; Zhang, X.; Han, J.; Ding, G. Repmlpnet: Hierarchical vision mlp with re-parameterized locality. arXiv 2021, arXiv:2112.11081. [Google Scholar]






| Output | ResNet-50 | EMANet |
|---|---|---|
| , 64, stride 2 | ||
| max pool, stride 2 | ||
| global average pool, 1000-d fc | ||
| Networks | Parameters (M) | FLOPs (G) | Top-1 (%) | Top-5 (%) |
|---|---|---|---|---|
| SENet [13] | 25.01 | 3.84 | 79.99 | 94.48 |
| ResNet [4] | 22.61 | 3.83 | 78.43 | 93.50 |
| FcaNet [14] | 25.01 | 3.83 | 79.20 | 93.77 |
| ECANet [15] | 22.61 | 3.83 | 78.49 | 93.50 |
| EPSANet [25] | 19.76 | 3.37 | 79.59 | 93.75 |
| CBAM [12] | 26.77 | 3.84 | 79.80 | 94.52 |
| SA-Net [22] | 24.37 | 3.83 | 78.79 | 93.78 |
| EMANet | 20.38 | 3.53 | 80.43 | 94.58 |
| Network | Parameters (M) | FLOPs (G) | Accuracy (%) |
|---|---|---|---|
| ResNet [4] | 22.43 | 1.215 | 93.62 |
| CBAM [12] | 24.83 | 1.222 | 93.43 |
| SA-Net [22] | 22.43 | 1.216 | 93.79 |
| SENet [13] | 24.83 | 1.219 | 95.35 |
| FcaNet [14] | 24.83 | 1.217 | 95.49 |
| ECANet [15] | 22.43 | 1.217 | 95.35 |
| EPSANet [25] | 19.58 | 1.066 | 95.32 |
| EMANet | 20.20 | 1.119 | 95.61 |
| Backbone | Parameters (M) | FLOPs (G) | mAP | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|---|---|
| SENet [13] | 30.98 | 351.76 | 80.77 | 48.1 | 80.5 | 50.3 | 13.3 | 34.1 | 54.3 |
| ResNet [4] | 28.47 | 317.98 | 78.60 | 45.7 | 78.3 | 47.8 | 6.7 | 32.3 | 51.6 |
| FcaNet [14] | 30.98 | 351.63 | 82.53 | 49.4 | 82.3 | 52.6 | 10 | 34.9 | 55.8 |
| ECANet [15] | 28.47 | 351.11 | 81.41 | 48.4 | 81 | 50.9 | 10.2 | 32.9 | 55.1 |
| EMANet | 26.13 | 268.57 | 85.20 | 53.9 | 84.8 | 59 | 13.6 | 37 | 61.1 |
| Group Size | Kernel Size | Parameters (M) | FLOPs (G) | Top-1 Acc (%) | Top-5 Acc (%) |
|---|---|---|---|---|---|
| (4,8,16,16) | 9 | 16.499 | 2.914 | 78.16 | 93.29 |
| (16,16,16,16) | 9 | 15.525 | 2.759 | 78.05 | 93.11 |
| (1,4,16,16) | 9 | 19.460 | 3.388 | 79.84 | 93.93 |
| (1,4,8,16) | 9 | 20.378 | 3.533 | 80.43 | 94.58 |
| (1,4,8,16) | 5 | 20.176 | 3.461 | 72.77 | 90.28 |
| (1,4,8,16) | 7 | 20.263 | 3.492 | 78.30 | 93.33 |
| (1,4,8,16) | 13 | 20.695 | 3.646 | 79.29 | 93.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Yang, M.; He, B.; Qin, T.; Yang, J. Multiscale Hybrid Convolutional Deep Neural Networks with Channel Attention. Entropy 2022, 24, 1180. https://doi.org/10.3390/e24091180
Yang H, Yang M, He B, Qin T, Yang J. Multiscale Hybrid Convolutional Deep Neural Networks with Channel Attention. Entropy. 2022; 24(9):1180. https://doi.org/10.3390/e24091180
Chicago/Turabian StyleYang, Hua, Ming Yang, Bitao He, Tao Qin, and Jing Yang. 2022. "Multiscale Hybrid Convolutional Deep Neural Networks with Channel Attention" Entropy 24, no. 9: 1180. https://doi.org/10.3390/e24091180
APA StyleYang, H., Yang, M., He, B., Qin, T., & Yang, J. (2022). Multiscale Hybrid Convolutional Deep Neural Networks with Channel Attention. Entropy, 24(9), 1180. https://doi.org/10.3390/e24091180