
Research on LSTM-Based Maneuvering Motion Prediction for USVs


Abstract
:1. Introduction
2. Sample Data Set Construction and Data Processing
2.1. The Maneuvering Motion Model of USV
2.2. Sample Data Acquisition
2.3. Sample Data Processing
3. LSTM-Based USV Motion Black-Box Prediction Model
4. Analysis on Network Structure and Simulation
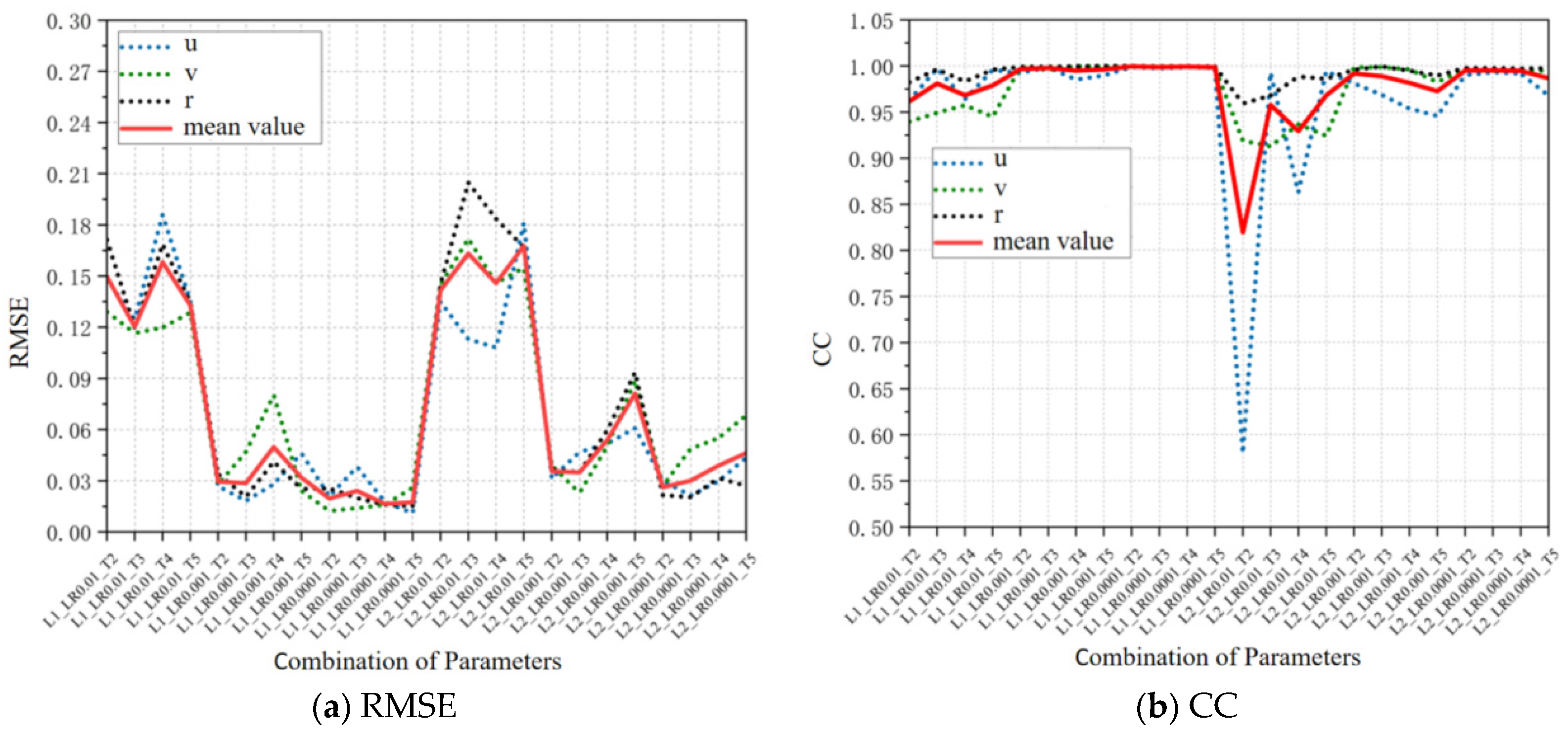
4.1. Discussion of Network Structure
- (1)
- Impact of Network Structure on Prediction Accuracy:
- (2)
- Impact of Network Structure on Iterations
- (1)
- LSTM Network Layers:
- (2)
- Number of Neurons:
- (3)
- Regularization Parameters:
4.2. Discussion of Training Settings
- (1)
- Learning Rate:
- (2)
- Window Function Width:
4.3. Comparing Simulations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| USVs | Unmanned Surface Vehicles |
| MMG | Maneuvering Modeling Group |
| SVM | Support Vector Machines |
| 3DoF | Three-Degree-of-Freedom |
| WAM-V | Wave Adaptive Modular Vessel |
| CFD | Computational Fluid Dynamics |
| SVR | Support Vector Regression |
| LSSVM | Least Squares Support Vector Machines |
| WNN | Wavelet Neural Networks |
| BP | Back Propagation |
| WEC | Wave Energy Converter |
| LSTM | Long Short-Term Memory Network |
| OU | Ornstein–Uhlenbeck |
| HMM | Hidden Markov Model |
| RNN | Recurrent Neural Network |
| RMSE | Root Mean Square Error |
| CC | Correlation Coefficient |
References
- Wang, S. Research on development status and combat applications of USVs in worldwide. Command. Syst. 2019, 44, 11–15. [Google Scholar]
- Yuan, X.Y. Hierarchical model identification method for unmanned surface vehicle. J. Shanghai Univ. (Nat. Sci.) 2020, 26, 896–908. [Google Scholar]
- Abkowitz, M.A. Measurement of hydrodynamic characteristics from ship maneuvering trials by system identification. Trans. Soc. Nav. Archit. Mar. Eng. 1980, 88, 283–318. [Google Scholar]
- Liu, Y.; Zou, L.; Zou, Z.; Guo, H.P. Predictions of ship maneuverability based on virtual captive model tests. Eng. Appl. Comput. Fluid Mech. 2018, 12, 334–353. [Google Scholar] [CrossRef]
- Xu, H.; Soares, C.G. Hydrodynamic coefficient estimation for ship manoeuvring in shallow water using an optimal truncated LS-SVM. Ocean Eng. 2019, 191, 106488. [Google Scholar] [CrossRef]
- He, H.; Wang, Z.; Zou, Z.; Liu, Y. System Identification Based on Completely Connected Neural Networks for Black-Box Modeling of Ship Maneuvers. In Advances in Guidance, Navigation and Control; Lecture Notes in Electrical Engineering; Springer: Singapore, 2022; Volume 644. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, Z. Identification of models of ship manoeuvring motion using Support Vector Regression and Particle Swarm Optimization. J. Ship Mech. 2016, 20, 1427–1432. [Google Scholar] [CrossRef]
- Xu, H.; Hinostroza, M.A.; Wang, Z.; Guedes Soares, C. Experimental investigation of shallow water effect on vessel steering model using system identification method. Ocean Eng. 2020, 199, 106940. [Google Scholar] [CrossRef]
- Xu, H.; Hassani, V.; Soares, C.G. Uncertainty analysis of the hydrodynamic coefficients estimation of a nonlinear manoeu-vring model based on planar motion mechanism tests. Ocean Eng. 2019, 173, 450–459. [Google Scholar] [CrossRef]
- Pandey, J.; Hasegawa, K. Study on turning manoeuvre of catamaran surface vessel with a combined experimental and simulation method. IFAC-PapersOnLine 2016, 49, 446–451. [Google Scholar] [CrossRef]
- Luo, W.; Zhang, Z. Modeling of ship maneuvering motion using neural networks. J. Mar. Sci. Appl. 2016, 15, 426–432. [Google Scholar] [CrossRef]
- Carrillo, S.; Contreras, J. Obtaining first and second order nomoto models of a fluvial support patrol using identification techniques. Ship Sci. Technol. 2018, 11, 19–28. [Google Scholar] [CrossRef]
- Liu, C.D.; Zhang, H.; Han, Y.; Shi, C. Black-box modeling and prediction of ship maneuverability based on Least Square Support Vector Machine. J. Ship Mech. 2013, 17, 872–877. [Google Scholar] [CrossRef]
- Xu, F.; Chen, Q.; Zhou, Z. Modeling of Underwater Vehicles’ Maneuvering Motion by Using Integral Sample Structure for Identification. J. Ship Mech. 2014, 211–220. [Google Scholar]
- Bonci, M.; Viviani, M.; Broglia, R.; Dubbioso, G. Method for estimating parameters of practical ship manoeuvring models based on the combination of RANSE computations and System Identification. Appl. Ocean Res. 2015, 52, 274–294. [Google Scholar] [CrossRef]
- Gupta, P.; Rasheed, A.; Steen, S. Ship performance monitoring using machine-learning. Ocean Eng. 2022, 254, 111094. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Wang, Z.H.; Zou, Z.J. Black-box modeling of ship maneuvering motion based on multi-output nu-support vector regression with random excitation signal. Ocean Eng. 2022, 257, 111279. [Google Scholar] [CrossRef]
- Song, L.; Hao, L.; Tao, H.; Xu, C.; Guo, R.; Li, Y.; Yao, J. Research on Black-Box Modeling Prediction of USV Maneuvering Based on SSA-WLS-SVM. J. Mar. Sci. Eng. 2023, 11, 324. [Google Scholar] [CrossRef]
- He, H.; Zou, Z. Black-Box Modeling of Ship Maneuvering Motion Using System Identification Method Based on BP Neural Network. In Proceedings of the ASME 2020 39th International Conference on Ocean, Offshore and Arctic Engineering, Virtual, Online, 3–7 August 2020; Volume 6B: Ocean Engineering. [Google Scholar] [CrossRef]
- Liu, Y.; Xue, Y.; Huang, S.; Xue, G.; Jing, Q. Dynamic Model Identification of Ships and Wave Energy Converters Based on Semi-Conjugate Linear Regression and Noisy Input Gaussian Process. J. Mar. Sci. Eng. 2021, 9, 194. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenarios | Conditions |
|---|---|
| No Wave | 10°/10° Zigzag |
| 15°/15° Zigzag | |
| 20°/20° Zigzag | |
| 25° Turning | |
| 30° Turning | |
| 35° Turning | |
| Wave | 10°/10° Zigzag |
| 15°/15° Zigzag | |
| 20°/20° Zigzag | |
| 25° Turning | |
| 30° Turning | |
| 35° Turning |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, R.; Mao, Y.; Xiang, Z.; Hao, L.; Wu, D.; Song, L. Research on LSTM-Based Maneuvering Motion Prediction for USVs. J. Mar. Sci. Eng. 2024, 12, 1661. https://doi.org/10.3390/jmse12091661
Guo R, Mao Y, Xiang Z, Hao L, Wu D, Song L. Research on LSTM-Based Maneuvering Motion Prediction for USVs. Journal of Marine Science and Engineering. 2024; 12(9):1661. https://doi.org/10.3390/jmse12091661
Chicago/Turabian StyleGuo, Rong, Yunsheng Mao, Zuquan Xiang, Le Hao, Dingkun Wu, and Lifei Song. 2024. "Research on LSTM-Based Maneuvering Motion Prediction for USVs" Journal of Marine Science and Engineering 12, no. 9: 1661. https://doi.org/10.3390/jmse12091661
APA StyleGuo, R., Mao, Y., Xiang, Z., Hao, L., Wu, D., & Song, L. (2024). Research on LSTM-Based Maneuvering Motion Prediction for USVs. Journal of Marine Science and Engineering, 12(9), 1661. https://doi.org/10.3390/jmse12091661