
An AI-Empowered Home-Infrastructure to Minimize Medication Errors



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Technical Background
- S is used to denote states;
- A is used to denote actions;
- R is used to denote a reward function;
- P indicates transition probability;
- is a discount factor: ∈ [0, 1].
4. System Model
4.1. Actor–Critic Algorithm
| Algorithm 1 actor critic algorithm |
Emulate , Initialize Rewards for all state–action pairs, Q to zero, Initialize tuning parameters Initialize s 1. Select OCR, BC, or DL method based on patient condition . 2. Get the next state (Right or wrong drug box) 3. Get the reward (positive in case of right drug box and negative in case of wrong drug box). 4. Update state utility function (critic). 5. Update the probability of the action using error (actor). until terminal state |
4.2. Dl Classifier
4.3. Optical Character Recognition
4.4. Barcode Method
- White and black bars are used in the structure of a barcode. Data retrieval is performed by shining a light from the scanner at a barcode, then capturing the reflected light and replacing the white and black bars with binary digital signals.
- Reflections are weak in black areas while strong in white areas. A sensor receives reflections to get analog waveforms.
- The analog waveforms are then converted into a digital signal using an analog to digital converter called binarization.
- Data retrieval is done when a code system is identified from the digital signal using the decoding process.
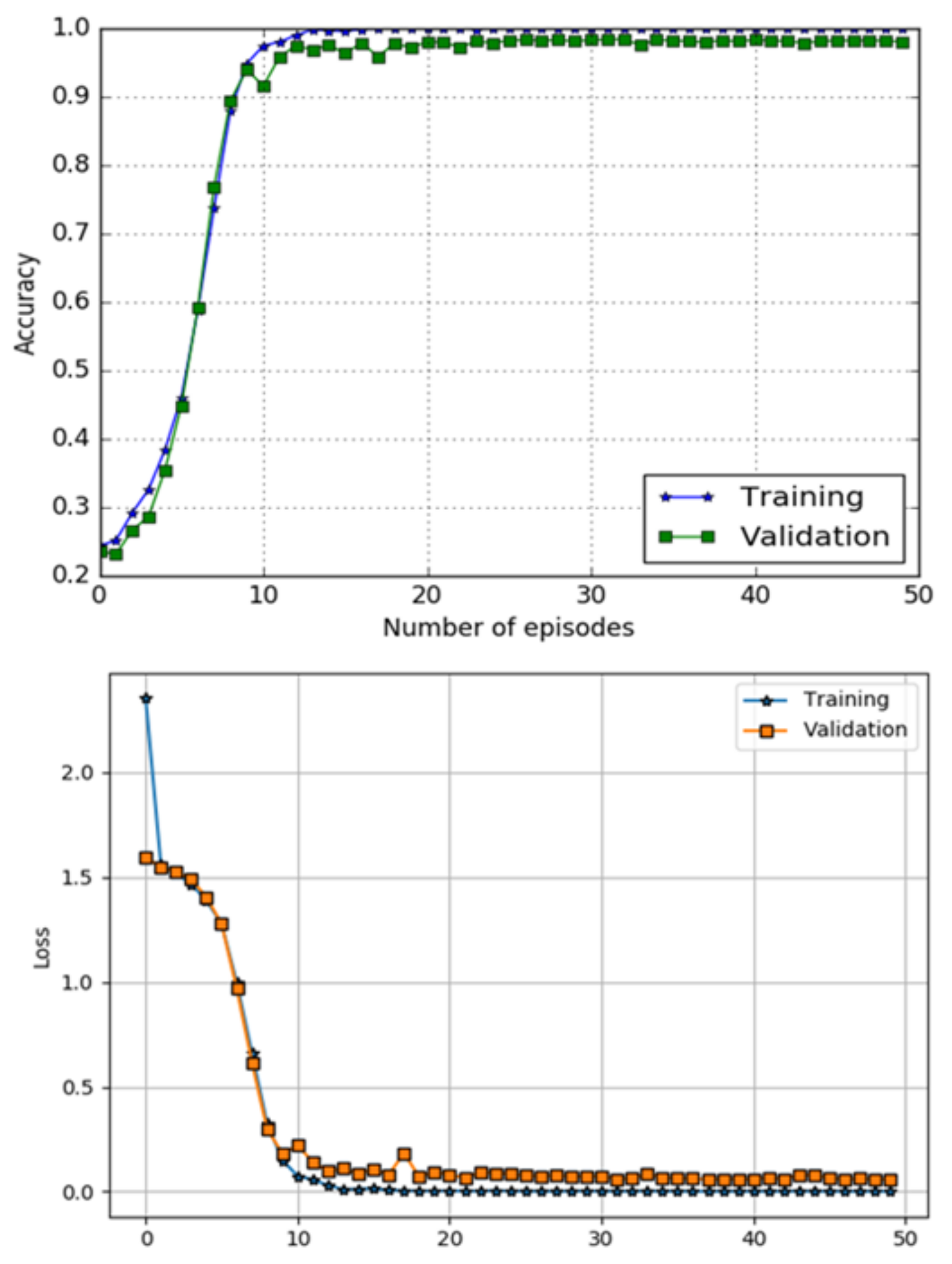
5. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rennke, S.; Ranji, S.R. Transitional care strategies from hospital to home: A review for the neurohospitalist. Neurohospitalist 2015, 5, 35–42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alzahrani, N. The effect of hospitalization on patients’ emotional and psychological well-being among adult patients: An integrative review. Appl. Nurs. Res. 2021, 61, 151488. [Google Scholar] [CrossRef] [PubMed]
- Stadhouders, N.; Kruse, F.; Tanke, M.; Koolman, X.; Jeurissen, P. Effective healthcare cost-containment policies: A systematic review. Health Policy 2019, 123, 71–79. [Google Scholar] [CrossRef] [PubMed]
- World Healthcare Organization. Adherence to Long-Term Therapies: Evidence for Action. Available online: http://www.who.int/chp/knowledge/adherence_full_report.pdf (accessed on 31 October 2020).
- Barber, N.; Alldred, D.; Raynor, D.; Dickinson, R.; Garfield, S.; Jesson, B.; Lim, R.; Savage, I.; Standage, C.; Buckle, P.; et al. Care homes’ use of medicines study: Prevalence, causes and potential harm of medication errors in care homes for older people. Qual. Saf. Health Care 2009, 18, 341–346. [Google Scholar] [CrossRef]
- World Healthcare Organization. Medication Errors. Available online: http://apps.who.int/iris/bitstream/handle/10665/252274/9789241511643\protect\discretionary{\char\hyphenchar\font}{}{}eng.pdf (accessed on 10 November 2020).
- European Medicines Agency. Streaming EMA Public Communication on Medication Errors. Available online: https://www.ema.europa.eu/documents/other/streamlining-ema-public-communication-medication-errors_en.pdf (accessed on 20 November 2020).
- DiMatteo, M.R. Evidence-based strategies to foster adherence and improve patient outcomes: The author’s recent meta-analysis indicates that patients do not follow treatment recommendations unless they know what to do, are committed to doing it, and have the resources to be able to adhere. JAAPA-J. Am. Acad. Physicians Assist. 2004, 17, 18–22. [Google Scholar]
- Sullivan, S.D. Noncompliance with medication regimens and subsequent hospitalization: A literature analysis and cost of hospitalization estimate. J. Res. Pharm. Econ. 1990, 2, 19–33. [Google Scholar]
- Perri, M., III; Menon, A.M.; Deshpande, A.D.; Shinde, S.B.; Jiang, R.; Cooper, J.W.; Cook, C.L.; Griffin, S.C.; Lorys, R.A. Adverse outcomes associated with inappropriate drug use in nursing homes. Ann. Pharmacother. 2005, 39, 405–411. [Google Scholar] [CrossRef] [PubMed]
- Bakhouya, M.; Campbell, R.; Coronato, A.; Pietro, G.D.; Ranganathan, A. Introduction to Special Section on Formal Methods in Pervasive Computing. ACM Trans. Auton. Adapt. Syst. 2012, 7, 6. [Google Scholar] [CrossRef]
- Naeem, M.; Rizvi, S.T.H.; Coronato, A. A Gentle Introduction to Reinforcement Learning and its Application in Different Fields. IEEE Access 2020, 8, 209320–209344. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; De Pietro, G.; Paragliola, G. Reinforcement learning for intelligent healthcare applications: A survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M. Ambient Intelligence for Home Medical Treatment Error Prevention. In Proceedings of the 2021 17th International Conference on Intelligent Environments (IE), Dubai, United Arab Emirates, 21–24 June 2021; pp. 1–8. [Google Scholar]
- Coronato, A.; Paragliola, G. A structured approach for the designing of safe aal applications. Expert Syst. Appl. 2017, 85, 1–13. [Google Scholar] [CrossRef]
- Ciampi, M.; Coronato, A.; Naeem, M.; Silvestri, S. An intelligent environment for preventing medication errors in home treatment. Expert Syst. Appl. 2022, 193, 116434. [Google Scholar] [CrossRef]
- Paragliola, G.; Naeem, M. Risk management for nuclear medical department using reinforcement learning algorithms. J. Reliab. Intell. Environ. 2019, 5, 105–113. [Google Scholar] [CrossRef]
- Coronato, A.; De Pietro, G. Tools for the Rapid Prototyping of Provably Correct Ambient Intelligence Applications. IEEE Trans. Softw. Eng. 2012, 38, 975–991. [Google Scholar] [CrossRef]
- Cinque, M.; Coronato, A.; Testa, A. A failure modes and effects analysis of mobile health monitoring systems. In Innovations and Advances in Computer, Information, Systems Sciences, and Engineering; Springer: New York, NY, USA, 2013; pp. 569–582. [Google Scholar]
- Testa, A.; Cinque, M.; Coronato, A.; De Pietro, G.; Augusto, J.C. Heuristic strategies for assessing wireless sensor network resiliency: An event-based formal approach. J. Heuristics 2015, 21, 145–175. [Google Scholar] [CrossRef] [Green Version]
- Coronato, A.; Pietro, G.D. Formal Design of Ambient Intelligence Applications. Computer 2010, 43, 60–68. [Google Scholar] [CrossRef]
- Naeem, M.; Paragiola, G.; Coronato, A.; De Pietro, G. A CNN-based monitoring system to minimize medication errors during treatment process at home. In Proceedings of the 3rd International Conference on Applications of Intelligent Systems, Las Palmas de Gran Canaria, Spain, 7–9 January 2020; pp. 1–5. [Google Scholar]
- Kautz, H.; Arnstein, L.; Borriello, G.; Etzioni, O.; Fox, D. An overview of the assisted cognition project. In Proceedings of the AAAI—2002 Workshop on Automation as Caregiver: The Role of Intelligent Technology in Elder Care, Edmonton, AB, Canada, 29 July 2002. [Google Scholar]
- Mynatt, E.D.; Essa, I.; Rogers, W. Increasing the Opportunities for Aging in Place. In Proceedings of the CUU’00: 2000 Conference on Universal Usability, Arlington, VA, USA, 16–17 November 2000; Association for Computing Machinery: New York, NY, USA, 2000; pp. 65–71. [Google Scholar] [CrossRef]
- Pineau, J.; Montemerlo, M.; Pollack, M.; Roy, N.; Thrun, S. Towards robotic assistants in nursing homes: Challenges and results. Robot. Auton. Syst. 2003, 42, 271–281. [Google Scholar] [CrossRef]
- Pollack, M.E. Planning Technology for Intelligent Cognitive Orthotics; AIPS, 2002; pp. 322–332. Available online: https://www.aaai.org/Papers/AIPS/2002/AIPS02-033.pdf (accessed on 20 December 2021).
- Hartl, A. Computer-vision based pharmaceutical pill recognition on mobile phones. In Proceedings of the 14th Central European Seminar on Computer Graphics, Budmerice, Slovakia, 10–12 May 2010; p. 5. [Google Scholar]
- Benjamim, X.C.; Gomes, R.B.; Burlamaqui, A.F.; Gonçalves, L.M.G. Visual identification of medicine boxes using features matching. In Proceedings of the 2012 IEEE International Conference on Virtual Environments Human-Computer Interfaces and Measurement Systems (VECIMS) Proceedings, Tianjin, China, 2–4 July 2012; pp. 43–47. [Google Scholar]
- Naeem, M.; Paragliola, G.; Coronato, A. A reinforcement learning and deep learning based intelligent system for the support of impaired patients in home treatment. Expert Syst. Appl. 2020, 168, 114285. [Google Scholar] [CrossRef]
- Neumann, L.; Matas, J. Real-time scene text localization and recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3538–3545. [Google Scholar]
- Al-Quwayfili, N.I.; Al-Khalifa, H.S. AraMedReader: An arabic medicine identifier using barcodes. In Proceedings of the International Conference on Human-Computer Interaction, Heraklion, Crete, Greece, 22–27 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 383–388. [Google Scholar]
- Ramljak, M. Smart home medication reminder system. In Proceedings of the 2017 25th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 21–23 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Alshamrani, M. IoT and artificial intelligence implementations for remote healthcare monitoring systems: A survey. J. King Saud-Univ.-Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Hong-tan, L.; Cui-hua, K.; Muthu, B.; Sivaparthipan, C. Big data and ambient intelligence in IoT-based wireless student health monitoring system. Aggress. Violent Behav. 2021, 101601. [Google Scholar] [CrossRef]
- Mirmomeni, M.; Fazio, T.; von Cavallar, S.; Harrer, S. From wearables to THINKables: Artificial intelligence-enabled sensors for health monitoring. In Wearable Sensors; Elsevier: Amsterdam, The Netherlands, 2021; pp. 339–356. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. A Deep Convolutional Activation Feature for Generic Visual Recognition; UC Berkeley & ICSI: Berkeley, CA, USA, 2013. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Aytar, Y.; Zisserman, A. Tabula rasa: Model transfer for object category detection. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2252–2259. [Google Scholar]
- Chui, K.T.; Fung, D.C.L.; Lytras, M.D.; Lam, T.M. Predicting at-risk university students in a virtual learning environment via a machine learning algorithm. Comput. Hum. Behav. 2020, 107, 105584. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naeem, M.; Coronato, A. An AI-Empowered Home-Infrastructure to Minimize Medication Errors. J. Sens. Actuator Netw. 2022, 11, 13. https://doi.org/10.3390/jsan11010013
Naeem M, Coronato A. An AI-Empowered Home-Infrastructure to Minimize Medication Errors. Journal of Sensor and Actuator Networks. 2022; 11(1):13. https://doi.org/10.3390/jsan11010013
Chicago/Turabian StyleNaeem, Muddasar, and Antonio Coronato. 2022. "An AI-Empowered Home-Infrastructure to Minimize Medication Errors" Journal of Sensor and Actuator Networks 11, no. 1: 13. https://doi.org/10.3390/jsan11010013
APA StyleNaeem, M., & Coronato, A. (2022). An AI-Empowered Home-Infrastructure to Minimize Medication Errors. Journal of Sensor and Actuator Networks, 11(1), 13. https://doi.org/10.3390/jsan11010013