1. Introduction
The demand for agricultural production is increasing all over the world as a result of the growing global population. The food consumed annually by China alone has increased significantly over the past decades [
1]. China has one of the largest populations in the world, and it is currently undergoing rapid urbanization. The continually increasing population and decreasing crop area (CA) highlight the necessity of CA protection. As an effective way to protect CA and determine CA changes, classification through remote sensing (RS) has been utilized to monitor the spatial distribution of agriculture and provide basic data for crop growth monitoring and yield forecasting, particularly for smallholder family farming in China [
2,
3,
4,
5].
Smallholder family farming is characterized by family-focused motives, such as favoring the stability of the farm household system; it mainly employs family labor for production and uses part of the farm’s products for the family’s consumption [
6]. CA in this system is usually characterized by small, heterogeneous, and often indistinct field patterns. Almost 70–80% of food in China is provided by this system [
7]. These fields are smaller than 2 ha, which makes resolving their distribution difficult with moderate spatial resolution (30–500 m) satellite imagery. The small size and large distribution area of smallholder family farming highlight the need for a precise and automatic method to map CA via high spatial resolution remote sensing images.
However, previous studies on CA or land cover maps in China and around the world have been mostly based on medium or low spatial resolution images [
8,
9]. At the coarse scale (>= 500 m), using the decision tree method and Moderate Resolution Imaging Spectroradiometer (MODIS), Friedl et al. [
10] and Tateishi et al. [
11] finished the global land cover classification task. With the openness of Landsat series images and the development of Google Earth Engine (GEE), a number of different approaches have been applied at the moderate resolution scale (30–500 m) [
12,
13,
14,
15,
16]. For medium-high resolution (10–30 m) satellites, because of its high spatial, spectral and temporal resolution, Sentinel-2 (S2) data has been used extensively in land cover mappings [
17,
18], crop type classifications [
19,
20], and monitoring of vegetation biomass [
21,
22]. These studies are usually based on S2’s time series information to get better results, which results in a high cost of image preprocessing work, including cloud masking, temporal gap filling and super resolution. Recent technologies have further increased the spatial resolution of available RS images (2 m spatial resolution and higher). The rich shape and context information provided by the high spatial resolution RS images allows researchers to get precise classification results with only one single-phase RS images. There have been some studies on urban land cover classification that used high spatial resolution images [
23,
24], but the methods have seldom aimed to map CA at a 1 m or even higher resolution. The era of using high spatial resolution RS images for mapping very small agriculture fields has only recently materialized [
25].
A high spatial resolution RS image provides the details necessary to observe smallholder agriculture. However, its low spectral resolution also presents challenges in smart image interpretation for CA to the remote sensing community. Some kinds of high spatial resolution RS images have only three bands, red-green-blue (RGB), thus lacking some useful spectral information, such as the near-infrared (NIR) band, for CA classification. Although there is vast literature on the automatic mapping of CA using machine learning algorithms, such as the inverse distance weighted interpolation method [
26], decision tree [
6], Support Vector Machine [
27], and artificial neural network [
28], the approaches have usually considered the spectrum of every individual pixel and then assigned each of them to a certain class [
25].
However, contextual features have proven to be very useful for classification [
29], especially when it comes to small and irregularly shaped targets. Meanwhile, the most prominent advantage of high spatial resolution RS images is their rich spatial information, so it is important to take full advantage of its contextual and shape features. Although some researchers have used texture statistics [
30,
31], mathematical morphology [
32,
33], and rotation invariance [
34,
35] as spatial and shape features, these mid-level features cannot describe the rich contextual information offered by high spatial resolution RS images. Moreover, these methods mostly rely on hand-engineered features, and most appearance descriptors depend on a set of free parameters, which are commonly set by user experience via experimental trial-and-error or cross-validation. So, we argue that a more thorough understanding of the spatial features, such as the shape of objects, is required to aid the mapping process of small and irregularly shaped smallholder agricultural fields.
Therefore, convolutional neural networks (CNNs) [
36] have attracted attention for their ability to automatically discover relevant contextual features in classification problems. CNNs, which learn the representative and discriminative features in a hierarchical manner from the data, have recently become a hotspot in the machine learning area and have been introduced to the geoscience and RS community for object detection [
37,
38], scene understanding [
39,
40], and image processing [
41,
42].
Recently, semantic classification tasks in remotely sensed data have also been approached by means of CNNs. In general, CNN architectures for semantic pixel-based classification use two main approaches: patch-based and pixel-to-pixel-based (end to end). At first, Patch classification was used for the task [
43,
44,
45]. These kinds of methods commonly start with training a CNN classifier on small image patches, followed by predicting the class of the center pixel using a sliding window approach. The drawback of these approaches is that the trained network can only predict the central pixel of the input image, resulting in low classification effectiveness. Then, an end-to-end framework for pixel-based methods became more popular [
46,
47,
48,
49] for its ability to learn global context features and its high process effectiveness [
50]. These frameworks are usually called semantic segmentation networks, and end-to-end usually means jointly learning a series of feature extractions from raw input data to generate a final, task-specific output. Compared with patch classification, semantic labeling-based strategies can label each pixel in the image. The network is trained to learn not only the relationships between spectral signatures and labels but also the contextual features of the whole input image.
Results from different studies have shown that both the accuracy and efficiency of end-to-end networks outperform standard patch-based strategies [
51,
52], suggesting that end-to-end structures are better suited for RS image classification. Recently, semantic segmentation networks, which are popular in computer vision, have been introduced to the field of RS image classification for their ability to learn both spatial and spectral information [
53,
54,
55]. In this study, we chose the DeepLabv3+ architecture to develop a methodology because it is effective in multi-scale feature fusion and boundary description. With the proposed method, we finished the automatic mapping of CA from Satellite images with only the three RGB bands.
In the next section, we first introduce the study area and the RS data we used in this study. In
Section 3, the details of our network architecture and training/classification strategies are presented. Then, we report the results of testing our semantic classification framework on WorldView-2 (WV-2) images with only RGB bands in
Section 4. Different classifiers are compared with the proposed method to prove its effectiveness, and the classification results are shown in
Section 5. Then, a Discussion about the strengths of the proposed method with respect to other relevant studies is given in
Section 6. Finally, considerations for future work and the conclusions of the study are given in
Section 7.
3. Method
In this study, we chose DeepLabv3+ as the classification model to get the CA from the study area; the architecture of the network is presented in
Section 3.1. Similar to other supervised classification methods, our approach generally has three stages (
Figure 2): the training stage, the classification stage, and the accuracy evaluation stage. In the training stage, image–label pairs, with pixel-class correspondence, are input into the DeepLabv3+ network as training samples. The error between predicted class labels and ground truth (GT) labels is calculated and back-propagated through the network using the chain rule, and then the parameters of the DeepLabv3+ network are updated using the gradient descent method. In the classification stage, the trained DeepLabv3+ network is fed an input image to generate a class prediction. Then, two kinds of evaluation methods are employed in the accuracy evaluation stage to establish the effectiveness of the proposed method. The details of the training and classification stages are introduced in
Section 3.2, while the two accuracy evaluation methods are detailed in
Section 3.3.
3.1. Network Architecture
In the last few years, semantic segmentation has been a hot topic in computer vision. A number of network architectures have been proposed, e.g., FCN [
58], U-Net [
59], PspNet [
60], SegNet [
61], and DeepLab series [
62,
63,
64,
65]. Meanwhile, there have been some studies focusing on semantic segmentation for RS images. From the first attempt by Mnih and Hinton [
66], who designed a shallow, fully connected network for road classification, different CNN architectures have been proposed for remote sensing images [
67,
68]. Recently, semantic segmentation networks that are popular in computer vision have been introduced to the field of RS image classification, and the results indicate that the networks are appropriate for RS images as well. In this study, we chose the DeepLabv3+ architecture (
Figure 3), which has achieved state-of-the-art performance on the PASCAL VOC 2012 [
69] and Cityscapes [
70] datasets.
DeepLabv3+ is built on a powerful CNN backbone architecture for the most accurate results. It is an encoder–decoder architecture that employs DeepLabv3 to encode the rich contextual information and a simple yet effective decoder module to recover object boundaries. Moreover, the spatial pyramid pooling strategy is applied in the network structure, resulting in a faster and stronger encoder–decoder network for semantic segmentation. Although the DeepLabv3+ model was designed for natural image segmentation, it is compatible with multichannel inputs and is sensitive to the boundaries in the images. So, DeepLabv3+ is particularly suitable for RS images classification and CA boundary delineation.
3.2. Network Training and Classification
Compared with traditional computer vision images, such as the images on ImageNet, RS images often have more coverage and a larger size. So, it is difficult to train RS images as a whole. Therefore, before training, we split the labeled RS images into small parts. As RS images labeled with the GT are limited, we used a sliding window for overlapped sampling rather than the general sampling procedure. The sliding window can help expand the training dataset and avoid overfitting. Meanwhile, four forms of data augmentation (rotate 90°, rotate 180°, rotate 270°, and flip) were also used in this work to further enlarge the dataset. The expanded training dataset, which is organized by Image–GT label pairs, was then inputted into DeepLabv3+ as the source of training samples. For better and faster training results, the model was first trained on ImageNet and then transferred to our dataset. The Softmax function [
71] was performed on the output feature map generated by the network to predict the class distribution. Then, the softmax loss was calculated and back-propagated, and finally, the network parameters were updated using Stochastic Gradient Descent (SGD) with momentum.
In the mapping stage, the trained network was used on the RS images to be classified. However, high spatial resolution RS images are often too large to be processed in only one pass through a CNN. Given current Graphic Processing Unit (GPU) memory limitations, we split our images into small patches using the same image size as that used in the training dataset. When splitting, an overlap strategy was also used. After predicting, we combined all of these small patches in order. For the overlapped part of the image predicted, we averaged the multiple predictions to obtain the final classification for overlapping pixels. This smooths the predictions along the borders of each patch and removes potential discontinuities.
3.3. Evaluation Method
3.3.1. Accuracy Evaluation Indicators
We employed the overall accuracy (OA), F1-Score, and Kappa coefficient as indicators to evaluate our approach. These indexes are calculated from the confusion matrix, where the overall accuracy is calculated as
where
represent the total number of correctly classified pixels, and
n is the total number of validation pixels. Overall accuracy denotes the proportion of the pixels that are correctly classified, and the F1-Score is computed as
where
the number of true positives for class
i;
the number of pixels belonging to class
i; and
the number of pixels attributed to class
i by the model. So,
is the number of correct positive results divided by the number of all positive results returned by the classifier,
is the number of correct positive results divided by the number of all relevant samples, and F1-Score represents the harmonic average of the
and
. The Kappa coefficient measures the consistency of the predicted classes with the GT classes, which is calculated as
where
is the number of times rater
k predicted category
i. The equations show that OA is the relative observed agreement among raters, and
is the hypothetical probability of chance agreement. If the raters are in complete agreement, then
. If there is no agreement among the raters other than what would be expected by chance (as given by
),
.
3.3.2. Per-Pixel Accuracy Evaluation Method
We randomly chose eight slices of the whole image for the pixel-based classification evaluation (
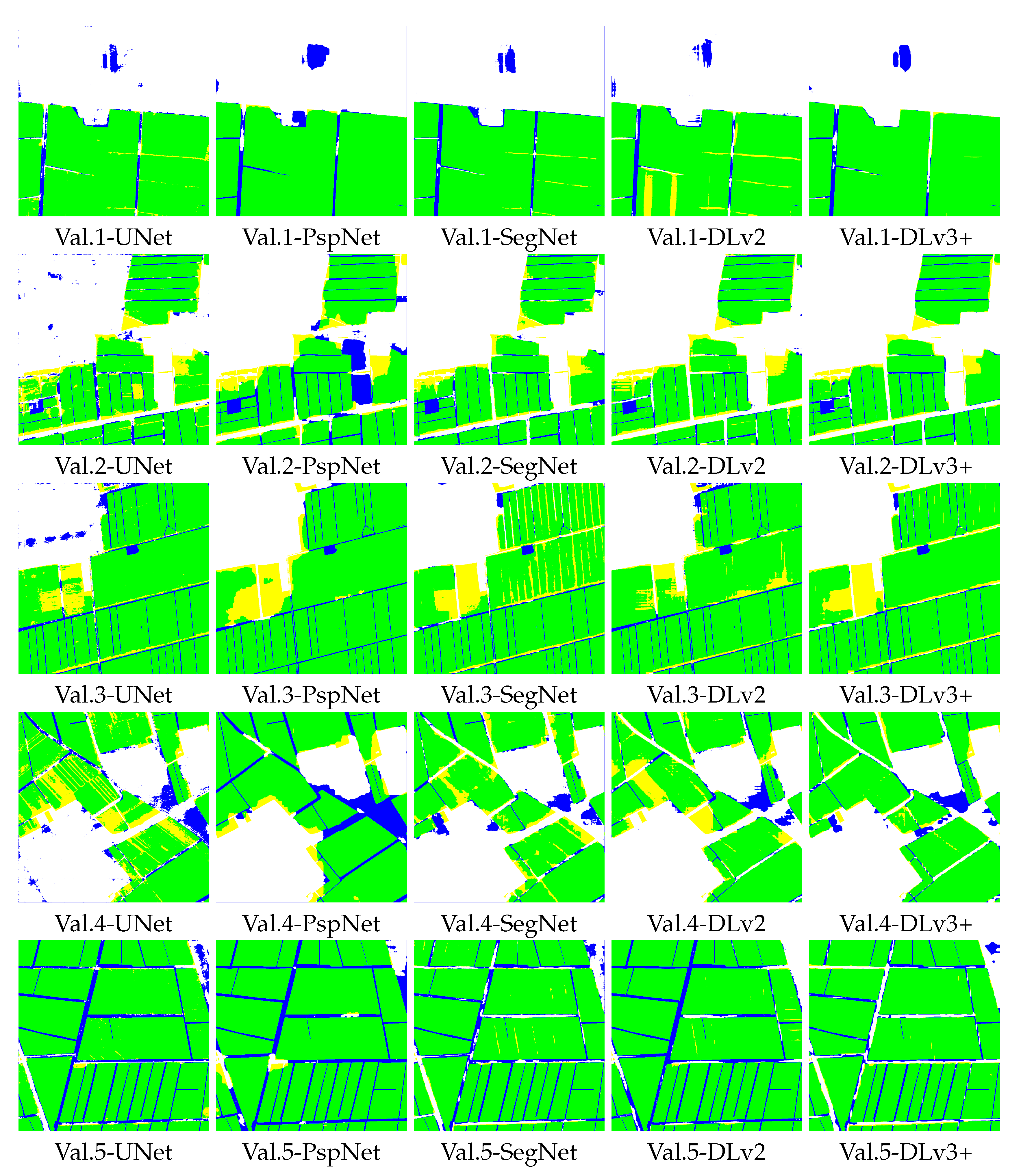
Figure 4). The size is 1024 × 1024 for all eight, and they were all labeled manually with the GT. None of the eight slices were involved in training. By obtaining the final mapping result and calculating the confusion matrix, we obtained the OA, kappa coefficient, and F1-Score for each slice. Furthermore, per-pixel accuracy was calculated for acquiring information on the spatial distribution of the classification error. Different kinds of competing methods were processed to prove the superiority of the method proposed in this paper.
3.3.3. Random Validation Point Accuracy Evaluation Method
As the RS images we used in this study have a high spatial resolution and cover the whole Baodi county at almost 1500 km2, it is hard to do per-pixel accuracy evaluation all across the study area. So, the evaluation was carried out using validation points to further prove that the classification method is effective for the whole study area. One hundred validation points were collected randomly from the entire image and labeled by visual interpretation. With the classification results, the confusion matrix was also calculated, along with the OA, kappa coefficient, and F1-Score.
4. Experiments and Comparison
4.1. Experiment Setup
Our training dataset a collection from WV-2 of Baodi, Tianjin, China. The images are in true color fusion with a 1-meter resolution. As the training dataset structure has a great influence on training and the classification result, we used K-MEANS, an unsupervised clustering method, before sampling to ensure that different kinds of CAs in the study area are covered in the training samples. After clustering, we manually labeled eight slices (sizes of 2048 × 2048) of the whole image at the pixel level as GT label data. In our training dataset, using a sliding window with a stride of 32 pixels, there are a total of 120,000 pairs of samples (sizes of 128 × 128). So, each pixel in the RS images corresponds to a pixel class. We used 96,000 images (80% of the whole set) for training, and the remaining 24,000 images (20% of the whole set) were used for testing. We used ResNet-101 as the network backbone in the DeepLabv3+ model. The ResNet-101 model was pretrained on ImageNet and then adapted to our dataset with 0.00001 as the initial learning rate. The max iteration in our training step was 75,000. In the training procedure, we fed the samples into the network in batches, and each batch contained 16 images. For the classification stage, we split the whole predicted image into small patches with a sliding window whose stride was 32 pixels. Then, all the patches were combined, and an averaging method was applied for the overlapped parts. In addition, we used the deep learning framework TensorFlow, Compute Unified Device Architecture 8.0 (CUDA 8.0), and Geospatial Data Abstraction Library (GDAL) to construct a platform for all of the work steps, including sampling, training, testing, and classifying, to extract and map CA.
4.2. Competing Method
Traditional machine learning methods have been widely used in the field of RS classification in the last few years. Common methods include Maximum Likelihood (ML) [
72], Support Vector Machine (SVM) [
73], and Random Forest (RF) [
74]. To prove that CNNs can get more thorough spatial or shape features from RGB high spatial resolution RS images, all three of these common classification methods were implemented using the same training dataset that we mentioned before. Detailed parameters are shown in
Table 1.
Different kinds of CNNs have been used recently for RS image classification for their ability to learn both spatial and spectral information. In this paper, to show the superiority of DeepLabv3+ for the task of CA mapping, we chose four popular end-to-end structure networks, i.e., U-Net, PspNet, SegNet, and DeepLabv2, as competing networks. The training strategy and parameters were the same for all five networks. Similar to the above, the training dataset was the same here, as well.
6. Discussion
Mapping CA using remotely sensed observations is important for CA protection and agricultural production. However, existing CA maps are mostly based on medium or low spatial resolution RS images that lack the essential spatial details to describe CA in a smallholder family farming system. Taking advantage of high spatial resolution RS images is an effective way to solve this problem, but it still presents several challenges when the traditional machine learning methods are used. These challenges include a thorough understanding of the rich spatial features and classification with low spectral resolution. Faced with these challenges, we developed an automatic classification framework based on deep semantic segmentation networks to map CA from WV-2 images with only three bands of RGB. Our study area, Baodi, has various types of soil and crops. It is an important grain and cotton production base in northern China. The climate and topographic conditions in the area are common in the North China Plain. All of these aspects make it representative for use in this study. Our research provides a number of key insights into how to utilize high spatial resolution RS images and deep semantic segmentation networks for mapping CA in a smallholder agricultural system.
First, our study demonstrates that, on the basis of high spatial resolution RS images and deep semantic segmentation networks, our method is suitable for the classification of CA in a smallholder family farming system. We compared our CA map with some other existing maps of Baodi. The Global Map–Global LC (GLCNMO) dataset from the International Steering Committee for Global Mapping, 2008, 500 m resolution [
11] and the Finer Resolution Observation and Monitoring Global LC dataset (FROM-GLC) from China based on Landsat images, 2015, 30 m resolution [
16] were used here. The same validation sample points introduced in
Section 3.3.3 were utilized to prove the effectiveness of high spatial resolution RS images and the method proposed in this study.
Table 7 shows the OA and kappa coefficient of the GLCNMO and FROM-GLC datasets and our result. The FROM-GLC dataset performs better than the GLCNMO dataset in the accuracy evaluation result, but they are very similar to each other. Results from our method show a significant increase in the OA and kappa coefficient. A comparison of the detailed mapping results is shown in
Figure 8. The sharpness of the CA boundaries and the details in the classification results are increased with the spatial resolution of RS images. The shape and contour of the road and river are also clearer in the results of WV-2 images. Further, the method proposed in this paper is better with the brushes and trees located between buildings and gives a more precise location of the CA in the mapping results, which is important for the small-sized fields in the smallholder family farming system.
A second major insight from our study is that deep semantic segmentation networks are effective in feature extraction from high spatial resolution RS images. Traditional machine learning methods usually rely on hand-engineered features to describe the spectral, contextual, and shape features of the input images. Most appearance descriptors depend on a set of free parameters, which are commonly set by user experience via experimental trial-and-error or cross-validation. However, as a sort of CNN, deep semantic segmentation networks are able to automatically discover relevant features in classification problems. Furthermore, the network used in this study, DeepLabv3+, can capture multi-scale information and generalize the standard convolution operation by the atrous convolution, which results in a more thorough understanding of the input information.
A third major insight is that deep semantic segmentation networks can prevent the salt-and-pepper phenomenon, which is common in pixel-based high spatial resolution RS image classification tasks. Before the appearance of deep semantic segmentation networks, the object-based classification method was usually used to solve the salt-and-pepper problem [
75,
76], but object segmentation also relies on researchers’ experience and knowledge to set up the segmentation parameters. However, a deep semantic segmentation network can perform segmentation and pixel classification at the same time by its encoder–decoder structure and obtain high classification accuracy and more detailed boundaries of CA. Therefore, compared with traditional machine learning methods, deep semantic segmentation can get better CA classification results, especially when it comes to high spatial resolution RS images with low spectral resolution.
A final key insight from our study is that it is possible to apply deep learning methods to the larger-scale task of RS image classification. Deep learning techniques were originally rooted in the computer vision fields for classification and recognition tasks, and they have only recently been introduced to the RS community. As a new research branch in RS image analysis, most of the recent studies have focused on the optimization of models and algorithms using a small-scale study area [
77,
78]. Studies using deep learning models for larger-scale RS classification are lacking. However, classification over large areas is one of the fundamental topics in the RS application field. In this study, we applied the proposed method to classify the CA of Baodi, which occupies 1500 km
2. With the development of hardware and the improvement of model training strategies, problems such as low efficiency and large numbers of training samples may be solved, and then deep learning models can be applied to the classification (or other analysis) of larger study areas, such as those at the regional or even national level.
Our method yielded automatic and precise smallholder agricultural CA maps, but a few uncertainties remain. First, our classification framework performed well with only one single-phase RS image and three RGB bands in this study. However, multi-temporal and multi-spectral features may help optimize the CA mapping results. Furthermore, although traditional machine learning methods had a lower classification accuracy, they were easier to train on a smaller dataset with point labels, and they had a higher efficiency in both the training and classification stages. The great performance of deep semantic segmentation models is often due to the availability of massive datasets. However, recent studies on semi-supervised [
79] or even unsupervised [
80] deep learning methods, as well as the transfer learning strategy [
81], indicate that this problem can be solved.
7. Conclusions
Prior studies have documented the effectiveness of RS image classification for the purpose of CA protection. However, these studies have been mostly based on RS images with medium or low spatial resolution, neglecting high spatial resolution RS images’ advantages for precise smallholder agriculture observation. Meanwhile, the methods used in these studies have often lacked a more thorough understanding of the context, such as the shape of objects. In this paper, using CNNs and WV-2 images, we developed a methodology to get better shapes and deeper contextual features of cropland, and we accomplished the automatic mapping of the CA of satellite images with only the three RGB bands.
We found that deep semantic segmentation networks, as a sort of CNN, are able to automatically extract the deep features from the input images and prevent salt-and-pepper problems by their encoder–decoder structure. Therefore, methods based on deep semantic segmentation models can get a higher classification accuracy and more detailed boundaries of CA than traditional machine learning methods, such as ML, SVM, and RF. These findings indicate that the deep semantic segmentation networks are effective for both the segmentation and classification of high spatial resolution RS images. Furthermore, we used the proposed method to classify the CA of the whole study area, which occupies 1500 km2. This study, therefore, provides insight into introducing deep learning methods to the larger-scale task of RS image classification.
Most notably, to our knowledge, this is the first study to use CNNs to extract the CA of a whole county area. Our results provide compelling evidence for CNNs’ ability to learn shape and contextual features and show that this approach appears to be effective for smallholder agriculture CA mapping. Owing to the representativeness of the study area and the generalization of the proposed framework, the methodology can be applied to other similar areas in the North China Plain or extended to mapping more refined cropland attributes such as crop types. However, there are still some limitations worth noting. Although our method achieved high accuracy in the study with only one single-phase RS image and three RGB bands, multi-temporal RS images and the near-infrared band have been proved to be important for CA classification. Future work should, therefore, focus on multi-source RS image fusion and multi-time sequence data processing with recurrent neural networks (RNNs).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}